 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Neural Networks with Human Demonstrations for Deep Reinforcement Learning
Sep 12, 2017

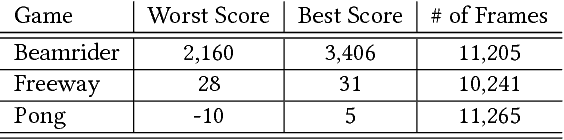
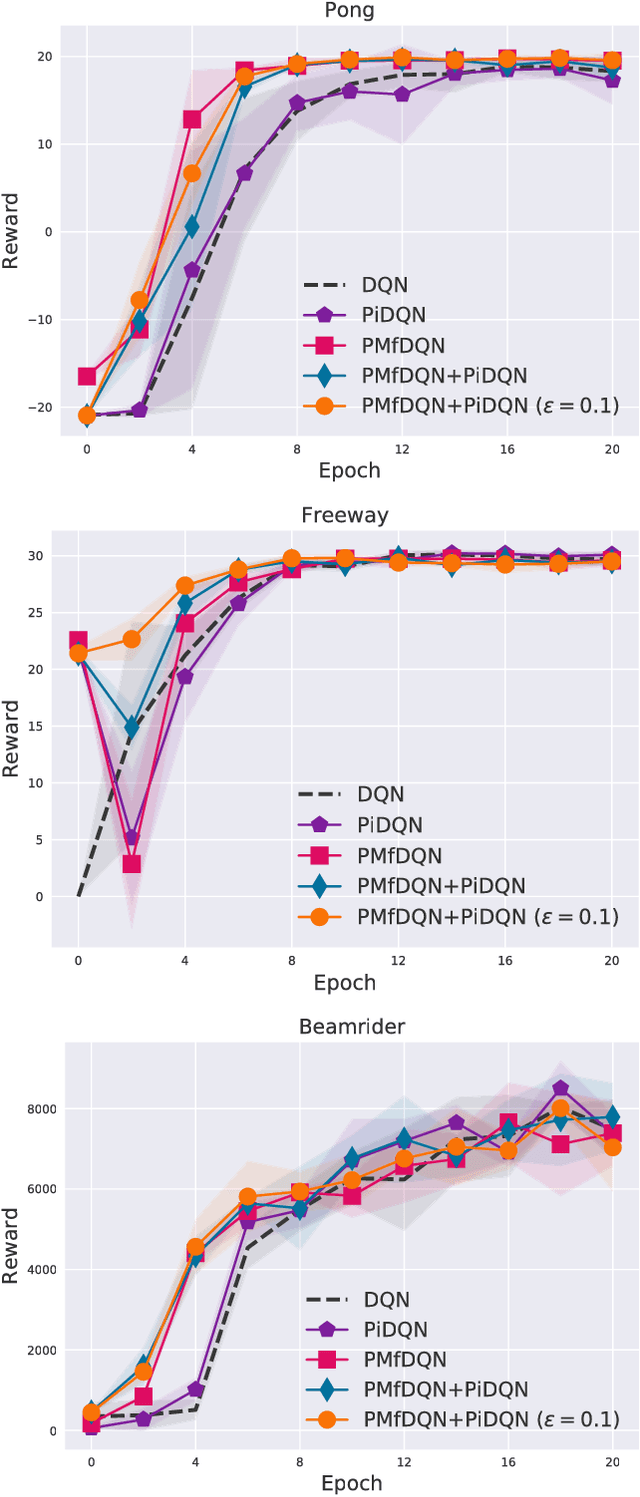
Deep reinforcement learning (deep RL) has achieved superior performance in complex sequential tasks by using a deep neural network as its function approximator and by learning directly from raw images. A drawback of using raw images is that deep RL must learn the state feature representation from the raw images in addition to learning a policy. As a result, deep RL can require a prohibitively large amount of training time and data to reach reasonable performance, making it difficult to use deep RL in real-world applications, especially when data is expensive. In this work, we speed up training by addressing half of what deep RL is trying to solve --- learning features. Our approach is to learn some of the important features by pre-training deep RL network's hidden layers via supervised learning using a small set of human demonstrations. We empirically evaluate our approach using deep Q-network (DQN) and asynchronous advantage actor-critic (A3C) algorithms on the Atari 2600 games of Pong, Freeway, and Beamrider. Our results show that: 1) pre-training with human demonstrations in a supervised learning manner is better at discovering features relative to pre-training naively in DQN, and 2) initializing a deep RL network with a pre-trained model provides a significant improvement in training time even when pre-training from a small number of human demonstrations.