 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLiFT-ASR: A Cross-Lingual Fine-Tuning Framework for Low-Resource Taiwanese Hokkien Speech Recognition
Nov 10, 2025Automatic speech recognition (ASR) for low-resource languages such as Taiwanese Hokkien is difficult due to the scarcity of annotated data. However, direct fine-tuning on Han-character transcriptions often fails to capture detailed phonetic and tonal cues, while training only on romanization lacks lexical and syntactic coverage. In addition, prior studies have rarely explored staged strategies that integrate both annotation types. To address this gap, we present CLiFT-ASR, a cross-lingual fine-tuning framework that builds on Mandarin HuBERT models and progressively adapts them to Taiwanese Hokkien. The framework employs a two-stage process in which it first learns acoustic and tonal representations from phonetic Tai-lo annotations and then captures vocabulary and syntax from Han-character transcriptions. This progressive adaptation enables effective alignment between speech sounds and orthographic structures. Experiments on the TAT-MOE corpus demonstrate that CLiFT-ASR achieves a 24.88\% relative reduction in character error rate (CER) compared with strong baselines. The results indicate that CLiFT-ASR provides an effective and parameter-efficient solution for Taiwanese Hokkien ASR and that it has potential to benefit other low-resource language scenarios.
Automated Speaking Assessment of Conversation Tests with Novel Graph-based Modeling on Spoken Response Coherence
Sep 11, 2024Automated speaking assessment in conversation tests (ASAC) aims to evaluate the overall speaking proficiency of an L2 (second-language) speaker in a setting where an interlocutor interacts with one or more candidates. Although prior ASAC approaches have shown promising performance on their respective datasets, there is still a dearth of research specifically focused on incorporating the coherence of the logical flow within a conversation into the grading model. To address this critical challenge, we propose a hierarchical graph model that aptly incorporates both broad inter-response interactions (e.g., discourse relations) and nuanced semantic information (e.g., semantic words and speaker intents), which is subsequently fused with contextual information for the final prediction. Extensive experimental results on the NICT-JLE benchmark dataset suggest that our proposed modeling approach can yield considerable improvements in prediction accuracy with respect to various assessment metrics, as compared to some strong baselines. This also sheds light on the importance of investigating coherence-related facets of spoken responses in ASAC.
Exploring Non-Autoregressive End-To-End Neural Modeling For English Mispronunciation Detection And Diagnosis
Nov 01, 2021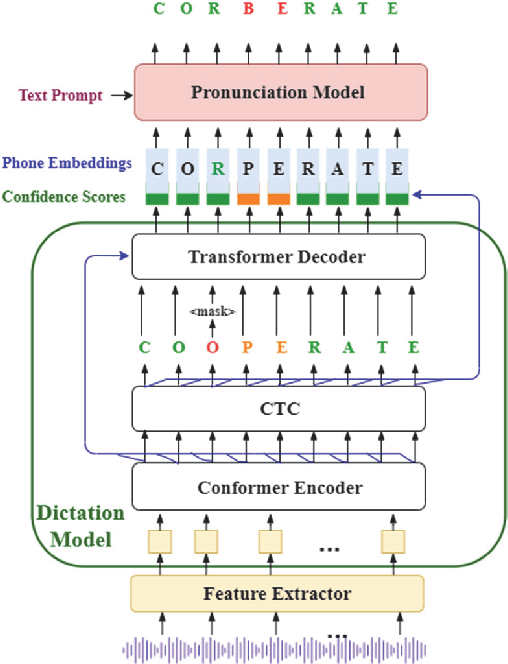
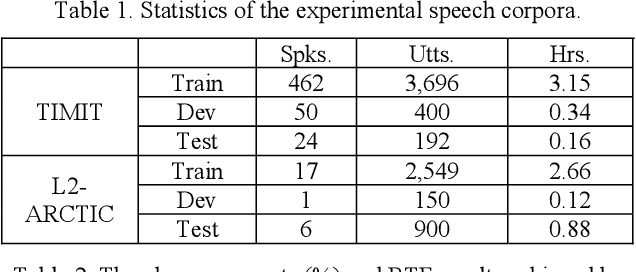
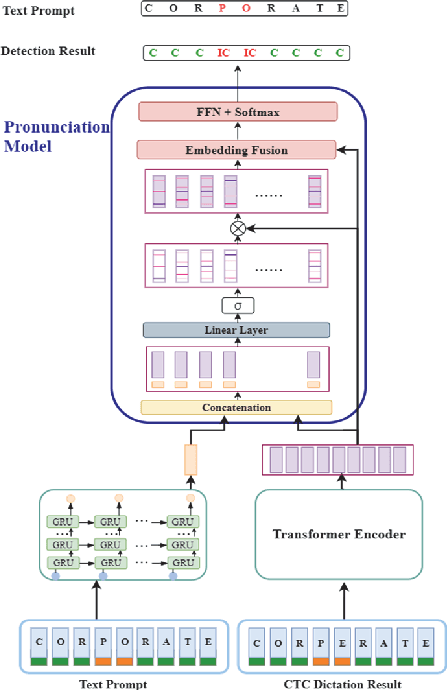
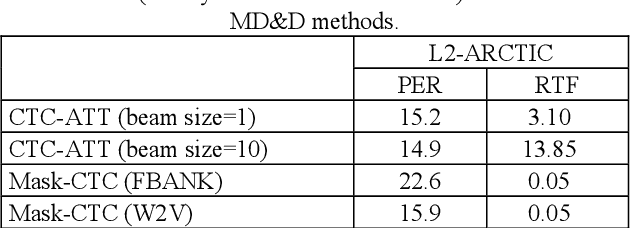
End-to-end (E2E) neural modeling has emerged as one predominant school of thought to develop computer-assisted language training (CAPT) systems, showing competitive performance to conventional pronunciation-scoring based methods. However, current E2E neural methods for CAPT are faced with at least two pivotal challenges. On one hand, most of the E2E methods operate in an autoregressive manner with left-to-right beam search to dictate the pronunciations of an L2 learners. This however leads to very slow inference speed, which inevitably hinders their practical use. On the other hand, E2E neural methods are normally data greedy and meanwhile an insufficient amount of nonnative training data would often reduce their efficacy on mispronunciation detection and diagnosis (MD&D). In response, we put forward a novel MD&D method that leverages non-autoregressive (NAR) E2E neural modeling to dramatically speed up the inference time while maintaining performance in line with the conventional E2E neural methods. In addition, we design and develop a pronunciation modeling network stacked on top of the NAR E2E models of our method to further boost the effectiveness of MD&D. Empirical experiments conducted on the L2-ARCTIC English dataset seems to validate the feasibility of our method, in comparison to some top-of-the-line E2E models and an iconic pronunciation-scoring based method built on a DNN-HMM acoustic model.
Effective FAQ Retrieval and Question Matching With Unsupervised Knowledge Injection
Oct 27, 2020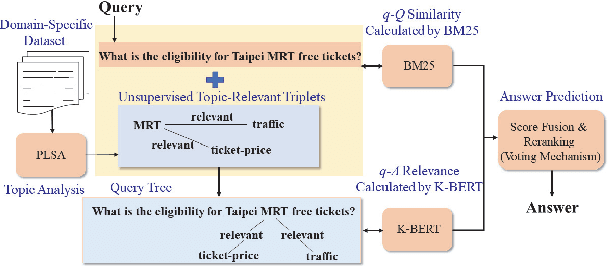
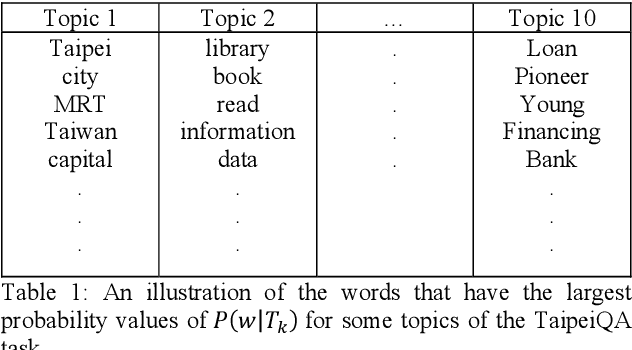
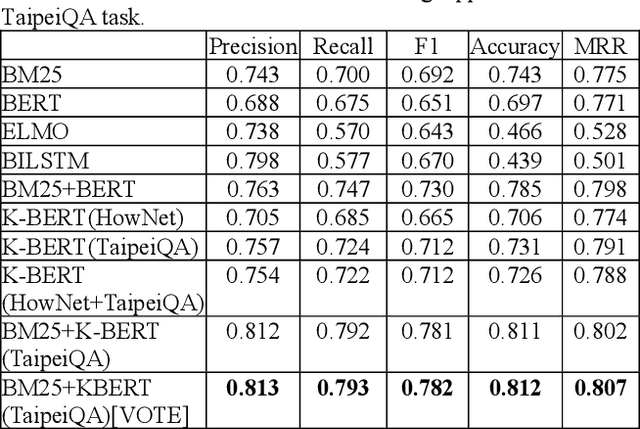
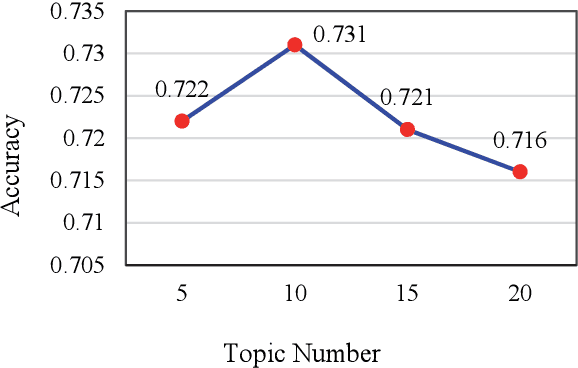
Frequently asked question (FAQ) retrieval, with the purpose of providing information on frequent questions or concerns, has far-reaching applications in many areas, where a collection of question-answer (Q-A) pairs compiled a priori can be employed to retrieve an appropriate answer in response to a user\u2019s query that is likely to reoccur frequently. To this end, predominant approaches to FAQ retrieval typically rank question-answer pairs by considering either the similarity between the query and a question (q-Q), the relevance between the query and the associated answer of a question (q-A), or combining the clues gathered from the q-Q similarity measure and the q-A relevance measure. In this paper, we extend this line of research by combining the clues gathered from the q-Q similarity measure and the q-A relevance measure and meanwhile injecting extra word interaction information, distilled from a generic (open domain) knowledge base, into a contextual language model for inferring the q-A relevance. Furthermore, we also explore to capitalize on domain-specific topically-relevant relations between words in an unsupervised manner, acting as a surrogate to the supervised domain-specific knowledge base information. As such, it enables the model to equip sentence representations with the knowledge about domain-specific and topically-relevant relations among words, thereby providing a better q-A relevance measure. We evaluate variants of our approach on a publicly-available Chinese FAQ dataset, and further apply and contextualize it to a large-scale question-matching task, which aims to search questions from a QA dataset that have a similar intent as an input query. Extensive experimental results on these two datasets confirm the promising performance of the proposed approach in relation to some state-of-the-art ones.