 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Expansion System for the VoxCeleb Speaker Recognition Challenge 2020
Nov 04, 2020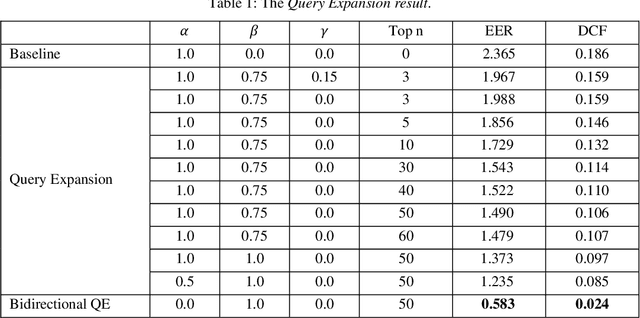
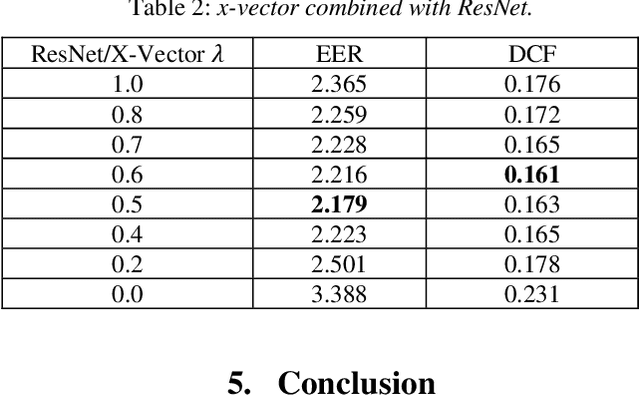
In this report, we describe our submission to the VoxCeleb Speaker Recognition Challenge (VoxSRC) 2020. Two approaches are adopted. One is to apply query expansion on speaker verification, which shows significant progress compared to baseline in the study. Another is to use Kaldi extract x-vector and to combine its Probabilistic Linear Discriminant Analysis (PLDA) score with ResNet score.
Effective FAQ Retrieval and Question Matching With Unsupervised Knowledge Injection
Oct 27, 2020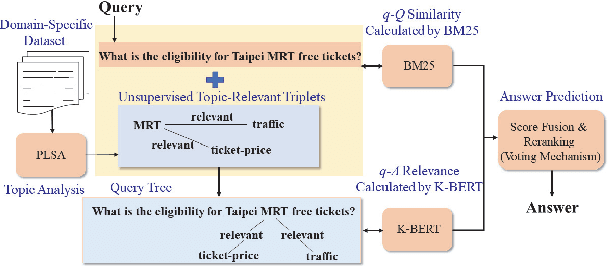
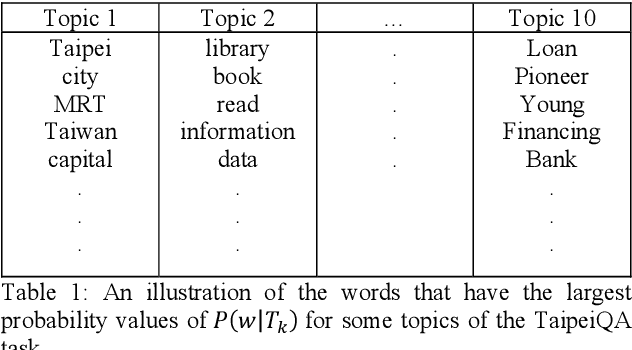
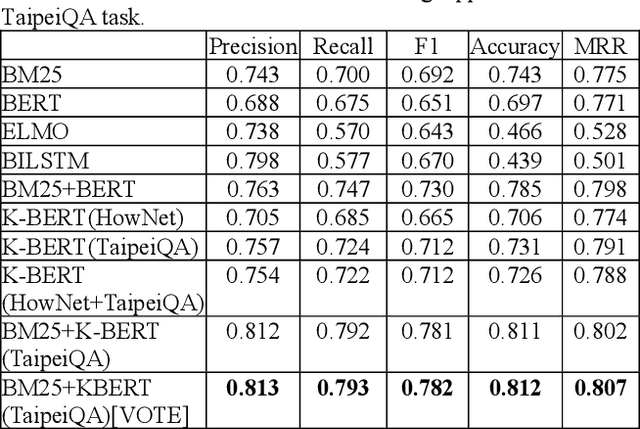
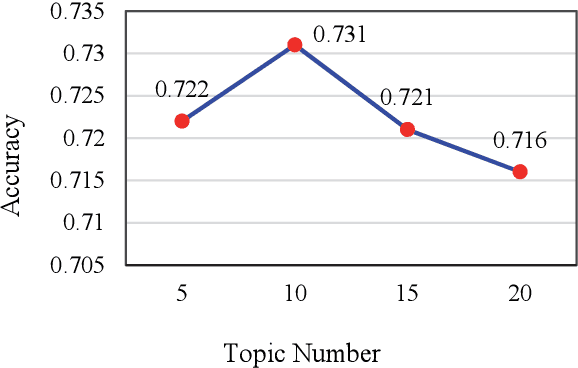
Frequently asked question (FAQ) retrieval, with the purpose of providing information on frequent questions or concerns, has far-reaching applications in many areas, where a collection of question-answer (Q-A) pairs compiled a priori can be employed to retrieve an appropriate answer in response to a user\u2019s query that is likely to reoccur frequently. To this end, predominant approaches to FAQ retrieval typically rank question-answer pairs by considering either the similarity between the query and a question (q-Q), the relevance between the query and the associated answer of a question (q-A), or combining the clues gathered from the q-Q similarity measure and the q-A relevance measure. In this paper, we extend this line of research by combining the clues gathered from the q-Q similarity measure and the q-A relevance measure and meanwhile injecting extra word interaction information, distilled from a generic (open domain) knowledge base, into a contextual language model for inferring the q-A relevance. Furthermore, we also explore to capitalize on domain-specific topically-relevant relations between words in an unsupervised manner, acting as a surrogate to the supervised domain-specific knowledge base information. As such, it enables the model to equip sentence representations with the knowledge about domain-specific and topically-relevant relations among words, thereby providing a better q-A relevance measure. We evaluate variants of our approach on a publicly-available Chinese FAQ dataset, and further apply and contextualize it to a large-scale question-matching task, which aims to search questions from a QA dataset that have a similar intent as an input query. Extensive experimental results on these two datasets confirm the promising performance of the proposed approach in relation to some state-of-the-art ones.