 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Speaking Assessment of Conversation Tests with Novel Graph-based Modeling on Spoken Response Coherence
Sep 11, 2024Automated speaking assessment in conversation tests (ASAC) aims to evaluate the overall speaking proficiency of an L2 (second-language) speaker in a setting where an interlocutor interacts with one or more candidates. Although prior ASAC approaches have shown promising performance on their respective datasets, there is still a dearth of research specifically focused on incorporating the coherence of the logical flow within a conversation into the grading model. To address this critical challenge, we propose a hierarchical graph model that aptly incorporates both broad inter-response interactions (e.g., discourse relations) and nuanced semantic information (e.g., semantic words and speaker intents), which is subsequently fused with contextual information for the final prediction. Extensive experimental results on the NICT-JLE benchmark dataset suggest that our proposed modeling approach can yield considerable improvements in prediction accuracy with respect to various assessment metrics, as compared to some strong baselines. This also sheds light on the importance of investigating coherence-related facets of spoken responses in ASAC.
ConPCO: Preserving Phoneme Characteristics for Automatic Pronunciation Assessment Leveraging Contrastive Ordinal Regularization
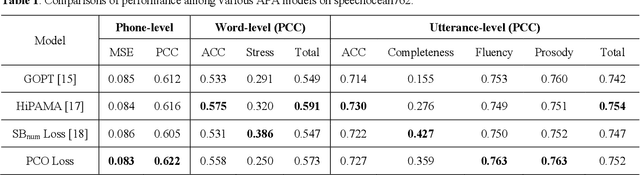
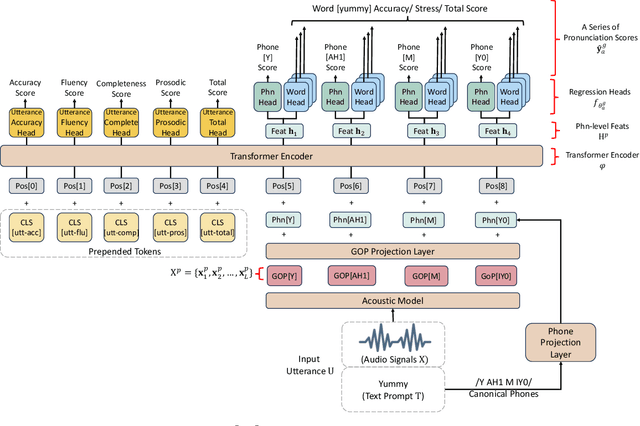
Jun 05, 2024Automatic pronunciation assessment (APA) manages to evaluate the pronunciation proficiency of a second language (L2) learner in a target language. Existing efforts typically draw on regression models for proficiency score prediction, where the models are trained to estimate target values without explicitly accounting for phoneme-awareness in the feature space. In this paper, we propose a contrastive phonemic ordinal regularizer (ConPCO) tailored for regression-based APA models to generate more phoneme-discriminative features while considering the ordinal relationships among the regression targets. The proposed ConPCO first aligns the phoneme representations of an APA model and textual embeddings of phonetic transcriptions via contrastive learning. Afterward, the phoneme characteristics are retained by regulating the distances between inter- and intra-phoneme categories in the feature space while allowing for the ordinal relationships among the output targets. We further design and develop a hierarchical APA model to evaluate the effectiveness of our method. Extensive experiments conducted on the speechocean762 benchmark dataset suggest the feasibility and efficacy of our approach in relation to some cutting-edge baselines.
Preserving Phonemic Distinctions for Ordinal Regression: A Novel Loss Function for Automatic Pronunciation Assessment
Oct 04, 2023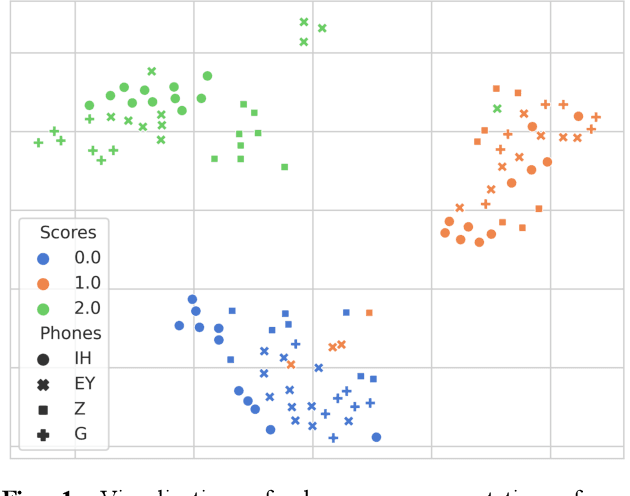
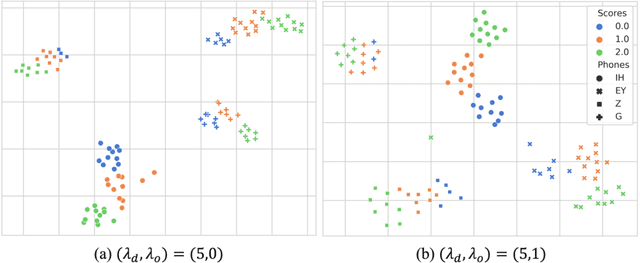
Automatic pronunciation assessment (APA) manages to quantify the pronunciation proficiency of a second language (L2) learner in a language. Prevailing approaches to APA normally leverage neural models trained with a regression loss function, such as the mean-squared error (MSE) loss, for proficiency level prediction. Despite most regression models can effectively capture the ordinality of proficiency levels in the feature space, they are confronted with a primary obstacle that different phoneme categories with the same proficiency level are inevitably forced to be close to each other, retaining less phoneme-discriminative information. On account of this, we devise a phonemic contrast ordinal (PCO) loss for training regression-based APA models, which aims to preserve better phonemic distinctions between phoneme categories meanwhile considering ordinal relationships of the regression target output. Specifically, we introduce a phoneme-distinct regularizer into the MSE loss, which encourages feature representations of different phoneme categories to be far apart while simultaneously pulling closer the representations belonging to the same phoneme category by means of weighted distances. An extensive set of experiments carried out on the speechocean762 benchmark dataset suggest the feasibility and effectiveness of our model in relation to some existing state-of-the-art models.