 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal or Not Real, that is the Question
Feb 12, 2020
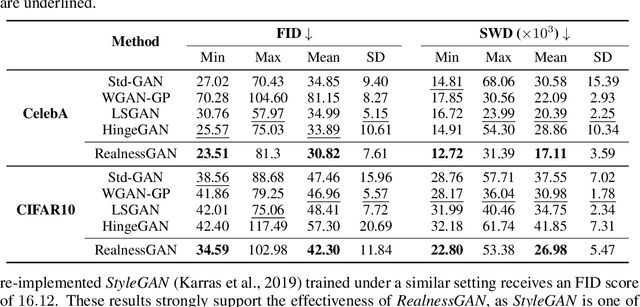

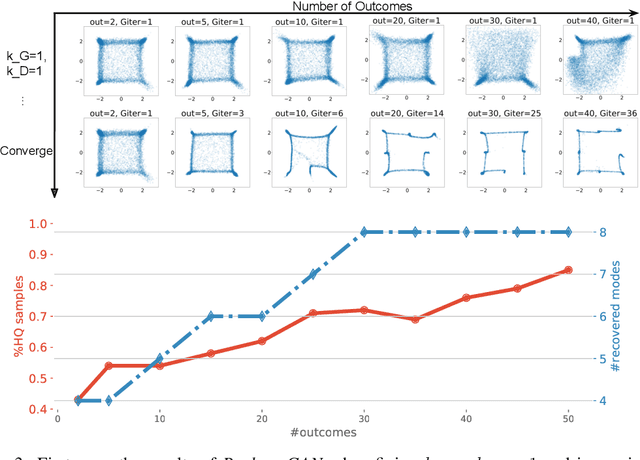
While generative adversarial networks (GAN) have been widely adopted in various topics, in this paper we generalize the standard GAN to a new perspective by treating realness as a random variable that can be estimated from multiple angles. In this generalized framework, referred to as RealnessGAN, the discriminator outputs a distribution as the measure of realness. While RealnessGAN shares similar theoretical guarantees with the standard GAN, it provides more insights on adversarial learning. Compared to multiple baselines, RealnessGAN provides stronger guidance for the generator, achieving improvements on both synthetic and real-world datasets. Moreover, it enables the basic DCGAN architecture to generate realistic images at 1024*1024 resolution when trained from scratch.
Improving On-policy Learning with Statistical Reward Accumulation
Sep 07, 2018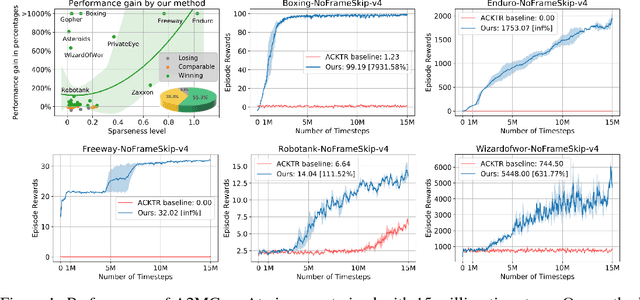
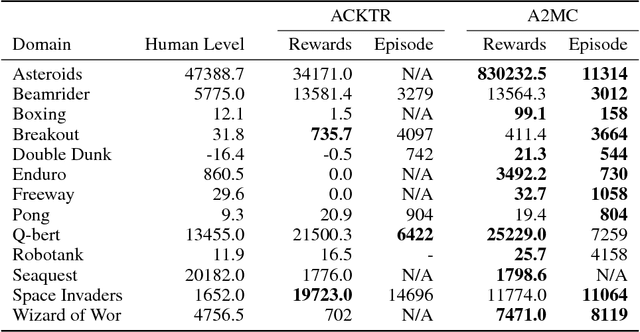
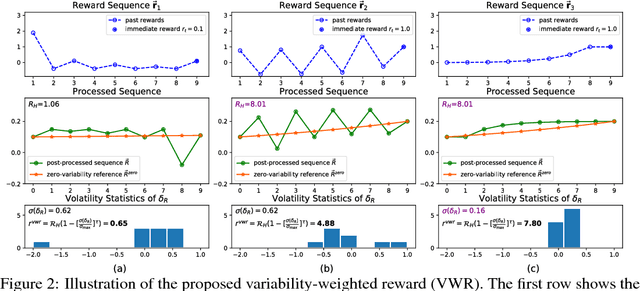
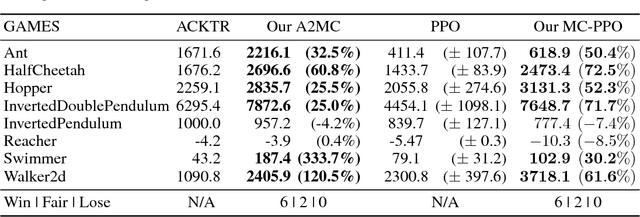
Deep reinforcement learning has obtained significant breakthroughs in recent years. Most methods in deep-RL achieve good results via the maximization of the reward signal provided by the environment, typically in the form of discounted cumulative returns. Such reward signals represent the immediate feedback of a particular action performed by an agent. However, tasks with sparse reward signals are still challenging to on-policy methods. In this paper, we introduce an effective characterization of past reward statistics (which can be seen as long-term feedback signals) to supplement this immediate reward feedback. In particular, value functions are learned with multi-critics supervision, enabling complex value functions to be more easily approximated in on-policy learning, even when the reward signals are sparse. We also introduce a novel exploration mechanism called "hot-wiring" that can give a boost to seemingly trapped agents. We demonstrate the effectiveness of our advantage actor multi-critic (A2MC) method across the discrete domains in Atari games as well as continuous domains in the MuJoCo environments. A video demo is provided at https://youtu.be/zBmpf3Yz8tc.
Aesthetic-Driven Image Enhancement by Adversarial Learning
Jul 02, 2018
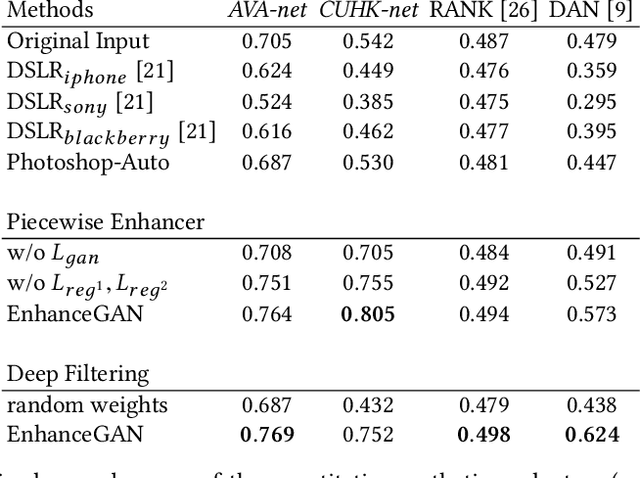
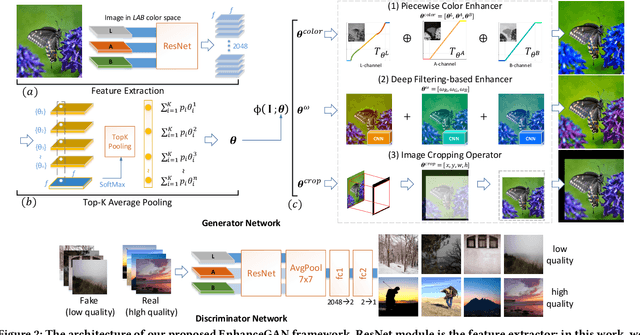
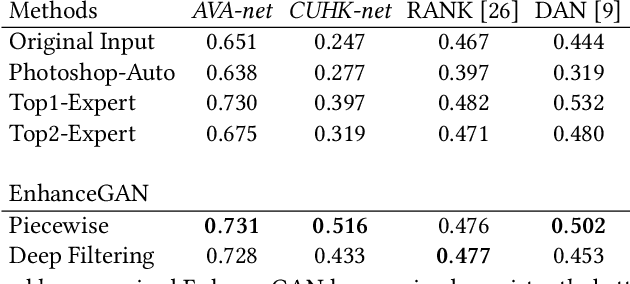
We introduce EnhanceGAN, an adversarial learning based model that performs automatic image enhancement. Traditional image enhancement frameworks typically involve training models in a fully-supervised manner, which require expensive annotations in the form of aligned image pairs. In contrast to these approaches, our proposed EnhanceGAN only requires weak supervision (binary labels on image aesthetic quality) and is able to learn enhancement operators for the task of aesthetic-based image enhancement. In particular, we show the effectiveness of a piecewise color enhancement module trained with weak supervision, and extend the proposed EnhanceGAN framework to learning a deep filtering-based aesthetic enhancer. The full differentiability of our image enhancement operators enables the training of EnhanceGAN in an end-to-end manner. We further demonstrate the capability of EnhanceGAN in learning aesthetic-based image cropping without any groundtruth cropping pairs. Our weakly-supervised EnhanceGAN reports competitive quantitative results on aesthetic-based color enhancement as well as automatic image cropping, and a user study confirms that our image enhancement results are on par with or even preferred over professional enhancement.
Image Aesthetic Assessment: An Experimental Survey
Apr 20, 2017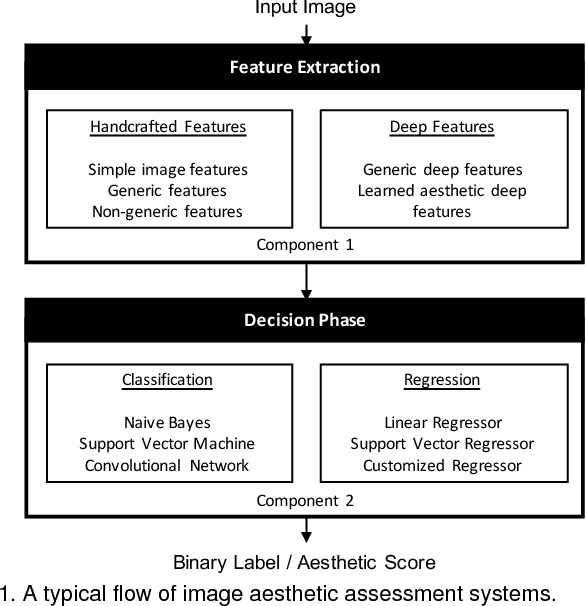
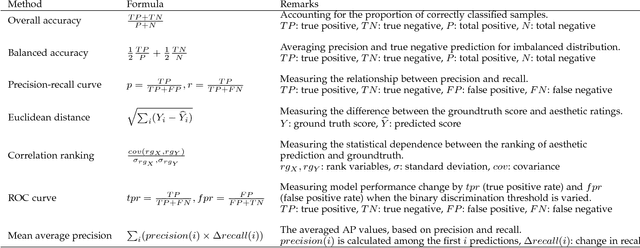


This survey aims at reviewing recent computer vision techniques used in the assessment of image aesthetic quality. Image aesthetic assessment aims at computationally distinguishing high-quality photos from low-quality ones based on photographic rules, typically in the form of binary classification or quality scoring. A variety of approaches has been proposed in the literature trying to solve this challenging problem. In this survey, we present a systematic listing of the reviewed approaches based on visual feature types (hand-crafted features and deep features) and evaluation criteria (dataset characteristics and evaluation metrics). Main contributions and novelties of the reviewed approaches are highlighted and discussed. In addition, following the emergence of deep learning techniques, we systematically evaluate recent deep learning settings that are useful for developing a robust deep model for aesthetic scoring. Experiments are conducted using simple yet solid baselines that are competitive with the current state-of-the-arts. Moreover, we discuss the possibility of manipulating the aesthetics of images through computational approaches. We hope that our survey could serve as a comprehensive reference source for future research on the study of image aesthetic assessment.
Boosting Optical Character Recognition: A Super-Resolution Approach
Jun 07, 2015
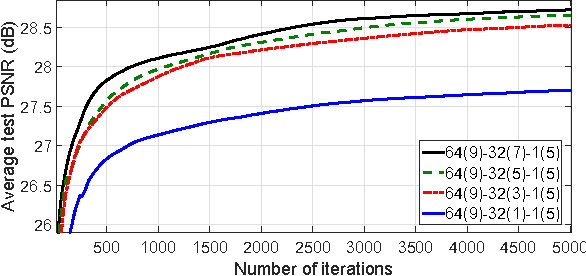
Text image super-resolution is a challenging yet open research problem in the computer vision community. In particular, low-resolution images hamper the performance of typical optical character recognition (OCR) systems. In this article, we summarize our entry to the ICDAR2015 Competition on Text Image Super-Resolution. Experiments are based on the provided ICDAR2015 TextSR dataset and the released Tesseract-OCR 3.02 system. We report that our winning entry of text image super-resolution framework has largely improved the OCR performance with low-resolution images used as input, reaching an OCR accuracy score of 77.19%, which is comparable with that of using the original high-resolution images 78.80%.
Learning to Recognize Pedestrian Attribute
Apr 29, 2015
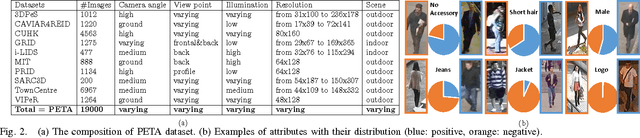
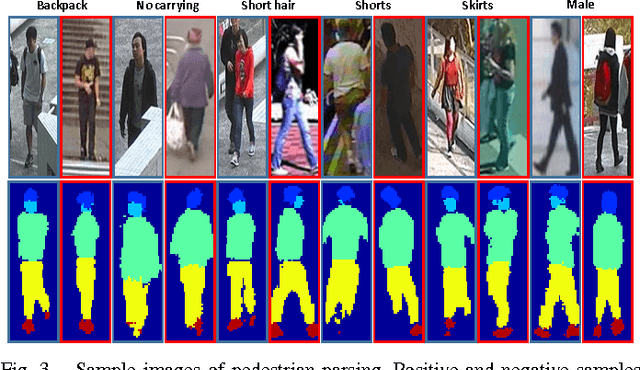

Learning to recognize pedestrian attributes at far distance is a challenging problem in visual surveillance since face and body close-shots are hardly available; instead, only far-view image frames of pedestrian are given. In this study, we present an alternative approach that exploits the context of neighboring pedestrian images for improved attribute inference compared to the conventional SVM-based method. In addition, we conduct extensive experiments to evaluate the informativeness of background and foreground features for attribute recognition. Experiments are based on our newly released pedestrian attribute dataset, which is by far the largest and most diverse of its kind.
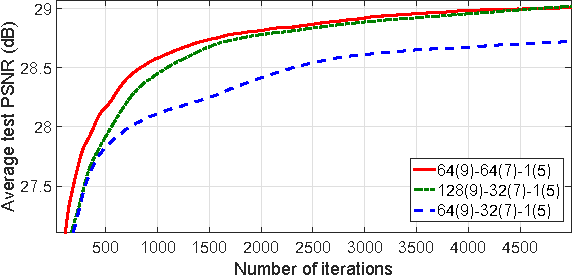
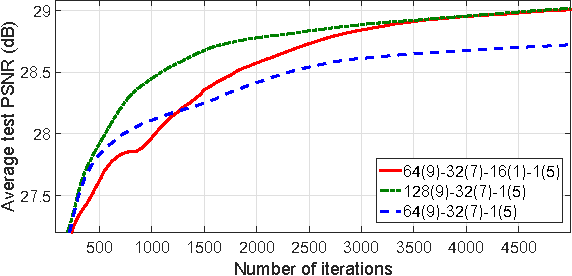
Compression Artifacts Reduction by a Deep Convolutional Network
Apr 27, 2015
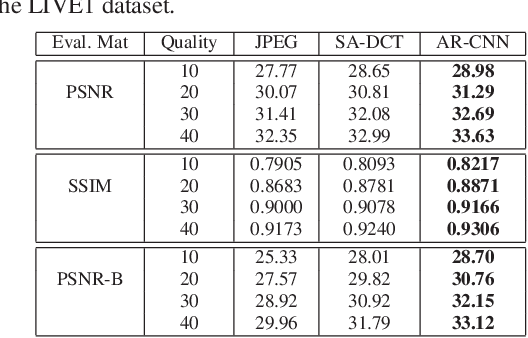
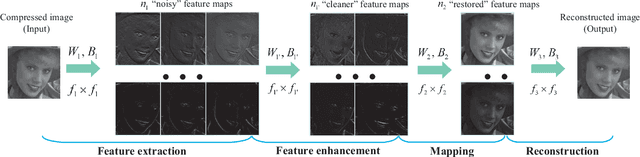
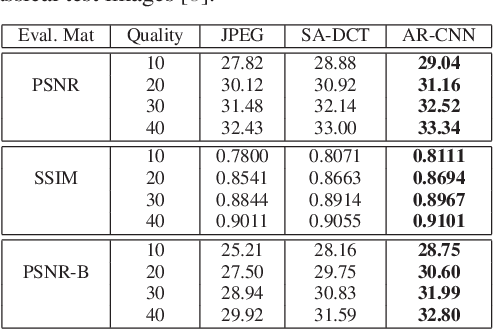
Lossy compression introduces complex compression artifacts, particularly the blocking artifacts, ringing effects and blurring. Existing algorithms either focus on removing blocking artifacts and produce blurred output, or restores sharpened images that are accompanied with ringing effects. Inspired by the deep convolutional networks (DCN) on super-resolution, we formulate a compact and efficient network for seamless attenuation of different compression artifacts. We also demonstrate that a deeper model can be effectively trained with the features learned in a shallow network. Following a similar "easy to hard" idea, we systematically investigate several practical transfer settings and show the effectiveness of transfer learning in low-level vision problems. Our method shows superior performance than the state-of-the-arts both on the benchmark datasets and the real-world use case (i.e. Twitter). In addition, we show that our method can be applied as pre-processing to facilitate other low-level vision routines when they take compressed images as input.