 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-EVAL: Evaluating Ancient Chinese Language Understanding in Large Language Models
Mar 11, 2024


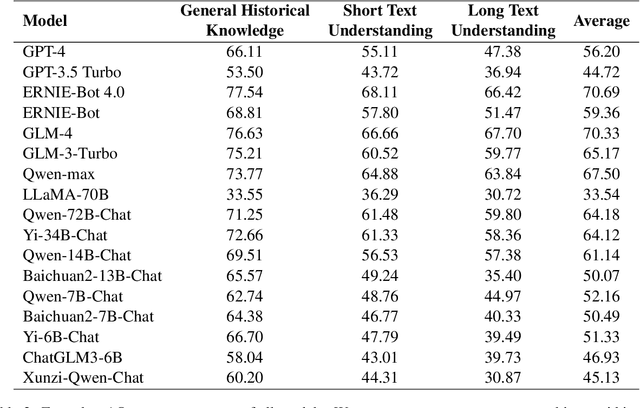
Given the importance of ancient Chinese in capturing the essence of rich historical and cultural heritage, the rapid advancements in Large Language Models (LLMs) necessitate benchmarks that can effectively evaluate their understanding of ancient contexts. To meet this need, we present AC-EVAL, an innovative benchmark designed to assess the advanced knowledge and reasoning capabilities of LLMs within the context of ancient Chinese. AC-EVAL is structured across three levels of difficulty reflecting different facets of language comprehension: general historical knowledge, short text understanding, and long text comprehension. The benchmark comprises 13 tasks, spanning historical facts, geography, social customs, art, philosophy, classical poetry and prose, providing a comprehensive assessment framework. Our extensive evaluation of top-performing LLMs, tailored for both English and Chinese, reveals a substantial potential for enhancing ancient text comprehension. By highlighting the strengths and weaknesses of LLMs, AC-EVAL aims to promote their development and application forward in the realms of ancient Chinese language education and scholarly research. The AC-EVAL data and evaluation code are available at https://github.com/yuting-wei/AC-EVAL.
Query-aware Long Video Localization and Relation Discrimination for Deep Video Understanding
Oct 19, 2023The surge in video and social media content underscores the need for a deeper understanding of multimedia data. Most of the existing mature video understanding techniques perform well with short formats and content that requires only shallow understanding, but do not perform well with long format videos that require deep understanding and reasoning. Deep Video Understanding (DVU) Challenge aims to push the boundaries of multimodal extraction, fusion, and analytics to address the problem of holistically analyzing long videos and extract useful knowledge to solve different types of queries. This paper introduces a query-aware method for long video localization and relation discrimination, leveraging an imagelanguage pretrained model. This model adeptly selects frames pertinent to queries, obviating the need for a complete movie-level knowledge graph. Our approach achieved first and fourth positions for two groups of movie-level queries. Sufficient experiments and final rankings demonstrate its effectiveness and robustness.