 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimalist and High-Performance Semantic Segmentation with Plain Vision Transformers
Oct 19, 2023

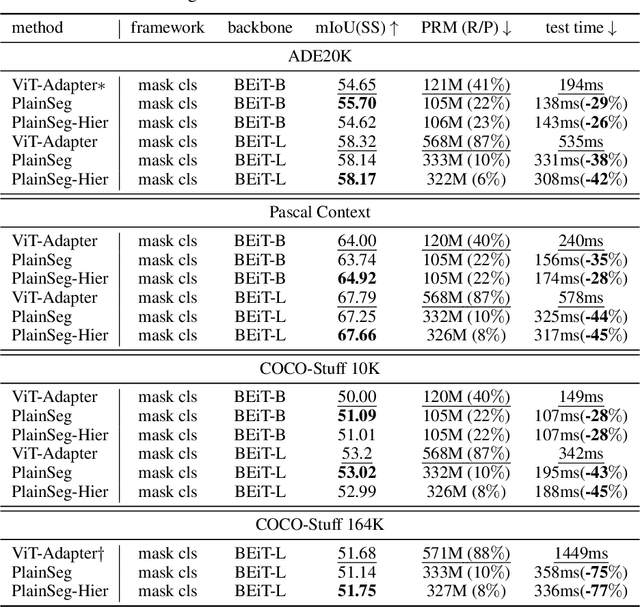

In the wake of Masked Image Modeling (MIM), a diverse range of plain, non-hierarchical Vision Transformer (ViT) models have been pre-trained with extensive datasets, offering new paradigms and significant potential for semantic segmentation. Current state-of-the-art systems incorporate numerous inductive biases and employ cumbersome decoders. Building upon the original motivations of plain ViTs, which are simplicity and generality, we explore high-performance `minimalist' systems to this end. Our primary purpose is to provide simple and efficient baselines for practical semantic segmentation with plain ViTs. Specifically, we first explore the feasibility and methodology for achieving high-performance semantic segmentation using the last feature map. As a result, we introduce the PlainSeg, a model comprising only three 3$\times$3 convolutions in addition to the transformer layers (either encoder or decoder). In this process, we offer insights into two underlying principles: (i) high-resolution features are crucial to high performance in spite of employing simple up-sampling techniques and (ii) the slim transformer decoder requires a much larger learning rate than the wide transformer decoder. On this basis, we further present the PlainSeg-Hier, which allows for the utilization of hierarchical features. Extensive experiments on four popular benchmarks demonstrate the high performance and efficiency of our methods. They can also serve as powerful tools for assessing the transfer ability of base models in semantic segmentation. Code is available at \url{https://github.com/ydhongHIT/PlainSeg}.
Representation Separation for Semantic Segmentation with Vision Transformers
Dec 28, 2022Vision transformers (ViTs) encoding an image as a sequence of patches bring new paradigms for semantic segmentation.We present an efficient framework of representation separation in local-patch level and global-region level for semantic segmentation with ViTs. It is targeted for the peculiar over-smoothness of ViTs in semantic segmentation, and therefore differs from current popular paradigms of context modeling and most existing related methods reinforcing the advantage of attention. We first deliver the decoupled two-pathway network in which another pathway enhances and passes down local-patch discrepancy complementary to global representations of transformers. We then propose the spatially adaptive separation module to obtain more separate deep representations and the discriminative cross-attention which yields more discriminative region representations through novel auxiliary supervisions. The proposed methods achieve some impressive results: 1) incorporated with large-scale plain ViTs, our methods achieve new state-of-the-art performances on five widely used benchmarks; 2) using masked pre-trained plain ViTs, we achieve 68.9% mIoU on Pascal Context, setting a new record; 3) pyramid ViTs integrated with the decoupled two-pathway network even surpass the well-designed high-resolution ViTs on Cityscapes; 4) the improved representations by our framework have favorable transferability in images with natural corruptions. The codes will be released publicly.
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes
Jan 15, 2021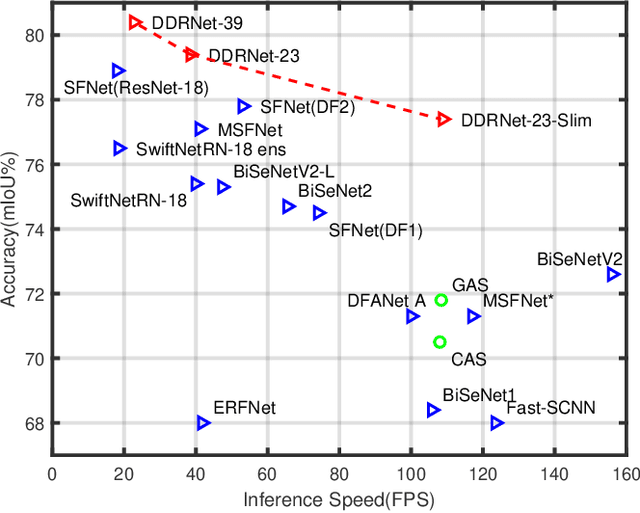
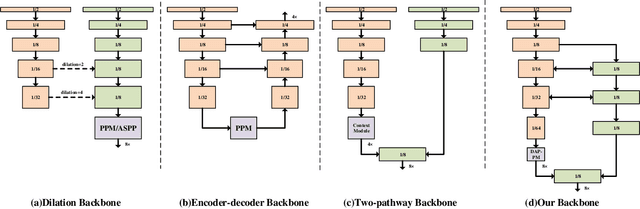
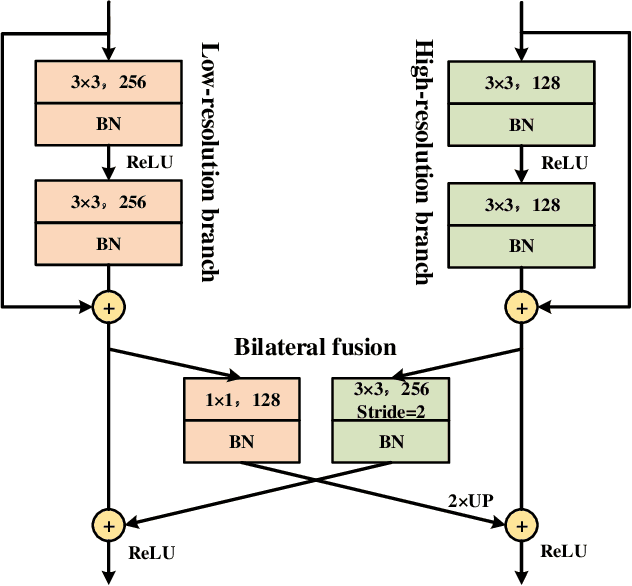
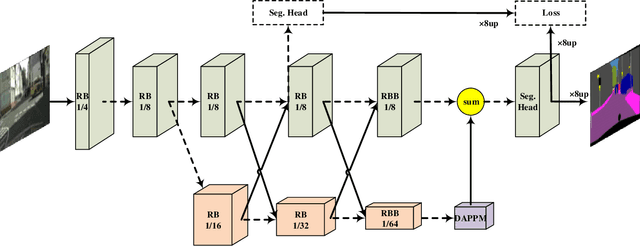
Semantic segmentation is a critical technology for autonomous vehicles to understand surrounding scenes. For practical autonomous vehicles, it is undesirable to spend a considerable amount of inference time to achieve high-accuracy segmentation results. Using light-weight architectures (encoder-decoder or two-pathway) or reasoning on low-resolution images, recent methods realize very fast scene parsing which even run at more than 100 FPS on single 1080Ti GPU. However, there are still evident gaps in performance between these real-time methods and models based on dilation backbones. To tackle this problem, we propose novel deep dual-resolution networks (DDRNets) for real-time semantic segmentation of road scenes. Besides, we design a new contextual information extractor named Deep Aggregation Pyramid Pooling Module (DAPPM) to enlarge effective receptive fields and fuse multi-scale context. Our method achieves new state-of-the-art trade-off between accuracy and speed on both Cityscapes and CamVid dataset. Specially, on single 2080Ti GPU, DDRNet-23-slim yields 77.4% mIoU at 109 FPS on Cityscapes test set and 74.4% mIoU at 230 FPS on CamVid test set. Without utilizing attention mechanism, pre-training on larger semantic segmentation dataset or inference acceleration, DDRNet-39 attains 80.4% test mIoU at 23 FPS on Cityscapes. With widely used test augmentation, our method is still superior to most state-of-the-art models, requiring much less computation. Codes and trained models will be made publicly available.