 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCDWT-GAN: Generative Adversarial Networks Based on Color Channel Using Discrete Wavelet Transform for Document Image Binarization
May 27, 2023To efficiently extract the textual information from color degraded document images is an important research topic. Long-term imperfect preservation of ancient documents has led to various types of degradation such as page staining, paper yellowing, and ink bleeding; these degradations badly impact the image processing for information extraction. In this paper, we present CCDWT-GAN, a generative adversarial network (GAN) that utilizes the discrete wavelet transform (DWT) on RGB (red, green, blue) channel splited images. The proposed method comprises three stages: image preprocessing, image enhancement, and image binarization. This work conducts comparative experiments in the image preprocessing stage to determine the optimal selection of DWT with normalization. Additionally, we perform an ablation study on the results of the image enhancement stage and the image binarization stage to validate their positive effect on the model performance. This work compares the performance of the proposed method with other state-of-the-art (SOTA) methods on DIBCO and H-DIBCO ((Handwritten) Document Image Binarization Competition) datasets. The experimental results demonstrate that CCDWT-GAN achieves a top two performance on multiple benchmark datasets, and outperforms other SOTA methods.
A Framework for Real-time Object Detection and Image Restoration
Mar 16, 2023Object detection and single image super-resolution are classic problems in computer vision (CV). The object detection task aims to recognize the objects in input images, while the image restoration task aims to reconstruct high quality images from given low quality images. In this paper, a two-stage framework for object detection and image restoration is proposed. The first stage uses YOLO series algorithms to complete the object detection and then performs image cropping. In the second stage, this work improves Swin Transformer and uses the new proposed algorithm to connect the Swin Transformer layer to design a new neural network architecture. We name the newly proposed network for image restoration SwinOIR. This work compares the model performance of different versions of YOLO detection algorithms on MS COCO dataset and Pascal VOC dataset, demonstrating the suitability of different YOLO network models for the first stage of the framework in different scenarios. For image super-resolution task, it compares the model performance of using different methods of connecting Swin Transformer layers and design different sizes of SwinOIR for use in different life scenarios. Our implementation code is released at https://github.com/Rubbbbbbbbby/SwinOIR.
Three-stage binarization of color document images based on discrete wavelet transform and generative adversarial networks
Dec 17, 2022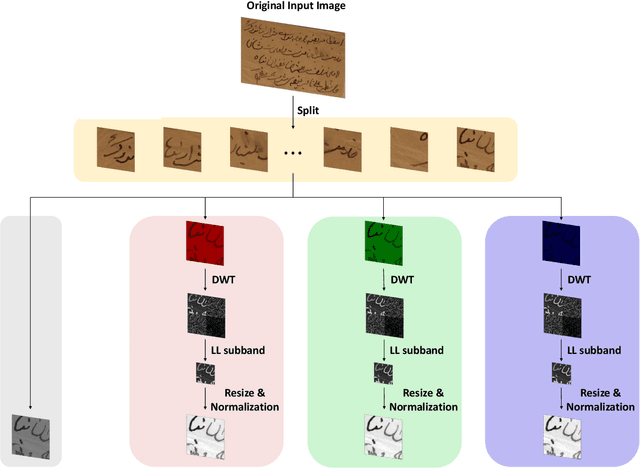



The efficient segmentation of foreground text information from the background in degraded color document images is a hot research topic. Due to the imperfect preservation of ancient documents over a long period of time, various types of degradation, including staining, yellowing, and ink seepage, have seriously affected the results of image binarization. In this paper, a three-stage method is proposed for image enhancement and binarization of degraded color document images by using discrete wavelet transform (DWT) and generative adversarial network (GAN). In Stage-1, we use DWT and retain the LL subband images to achieve the image enhancement. In Stage-2, the original input image is split into four (Red, Green, Blue and Gray) single-channel images, each of which trains the independent adversarial networks. The trained adversarial network models are used to extract the color foreground information from the images. In Stage-3, in order to combine global and local features, the output image from Stage-2 and the original input image are used to train the independent adversarial networks for document binarization. The experimental results demonstrate that our proposed method outperforms many classical and state-of-the-art (SOTA) methods on the Document Image Binarization Contest (DIBCO) dataset. We release our implementation code at https://github.com/abcpp12383/ThreeStageBinarization.
Aggregated Pyramid Vision Transformer: Split-transform-merge Strategy for Image Recognition without Convolutions
Mar 02, 2022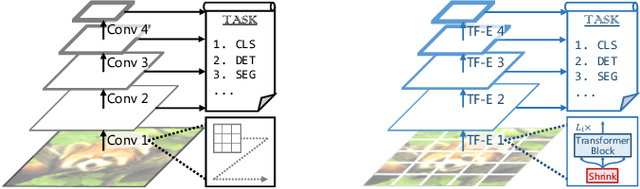
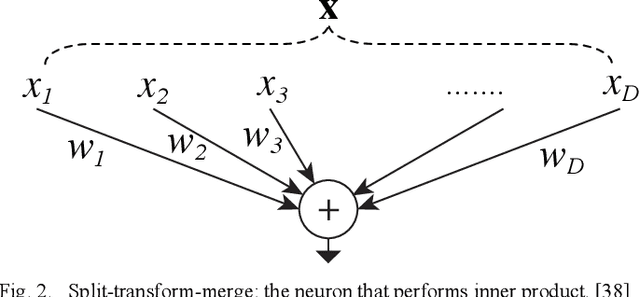


With the achievements of Transformer in the field of natural language processing, the encoder-decoder and the attention mechanism in Transformer have been applied to computer vision. Recently, in multiple tasks of computer vision (image classification, object detection, semantic segmentation, etc.), state-of-the-art convolutional neural networks have introduced some concepts of Transformer. This proves that Transformer has a good prospect in the field of image recognition. After Vision Transformer was proposed, more and more works began to use self-attention to completely replace the convolutional layer. This work is based on Vision Transformer, combined with the pyramid architecture, using Split-transform-merge to propose the group encoder and name the network architecture Aggregated Pyramid Vision Transformer (APVT). We perform image classification tasks on the CIFAR-10 dataset and object detection tasks on the COCO 2017 dataset. Compared with other network architectures that use Transformer as the backbone, APVT has excellent results while reducing the computational cost. We hope this improved strategy can provide a reference for future Transformer research in computer vision.