 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNellie: Automated organelle segmentation, tracking, and hierarchical feature extraction in 2D/3D live-cell microscopy
Mar 20, 2024The analysis of dynamic organelles remains a formidable challenge, though key to understanding biological processes. We introduce Nellie, an automated and unbiased pipeline for segmentation, tracking, and feature extraction of diverse intracellular structures. Nellie adapts to image metadata, eliminating user input. Nellie's preprocessing pipeline enhances structural contrast on multiple intracellular scales allowing for robust hierarchical segmentation of sub-organellar regions. Internal motion capture markers are generated and tracked via a radius-adaptive pattern matching scheme, and used as guides for sub-voxel flow interpolation. Nellie extracts a plethora of features at multiple hierarchical levels for deep and customizable analysis. Nellie features a Napari-based GUI that allows for code-free operation and visualization, while its modular open-source codebase invites customization by experienced users. We demonstrate Nellie's wide variety of use cases with two examples: unmixing multiple organelles from a single channel using feature-based classification and training an unsupervised graph autoencoder on mitochondrial multi-mesh graphs to quantify latent space embedding changes following ionomycin treatment.
Three-stage binarization of color document images based on discrete wavelet transform and generative adversarial networks
Dec 17, 2022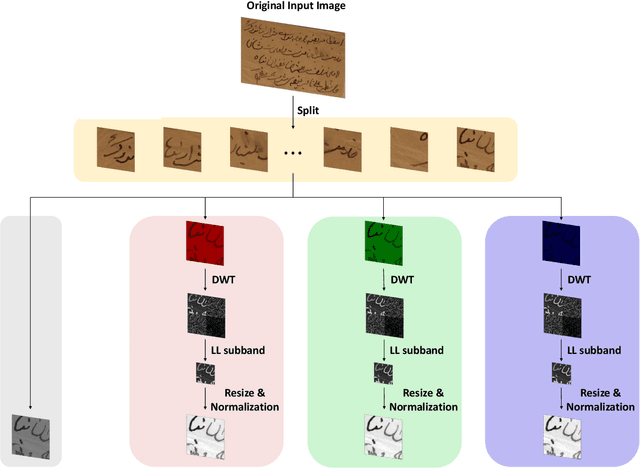



The efficient segmentation of foreground text information from the background in degraded color document images is a hot research topic. Due to the imperfect preservation of ancient documents over a long period of time, various types of degradation, including staining, yellowing, and ink seepage, have seriously affected the results of image binarization. In this paper, a three-stage method is proposed for image enhancement and binarization of degraded color document images by using discrete wavelet transform (DWT) and generative adversarial network (GAN). In Stage-1, we use DWT and retain the LL subband images to achieve the image enhancement. In Stage-2, the original input image is split into four (Red, Green, Blue and Gray) single-channel images, each of which trains the independent adversarial networks. The trained adversarial network models are used to extract the color foreground information from the images. In Stage-3, in order to combine global and local features, the output image from Stage-2 and the original input image are used to train the independent adversarial networks for document binarization. The experimental results demonstrate that our proposed method outperforms many classical and state-of-the-art (SOTA) methods on the Document Image Binarization Contest (DIBCO) dataset. We release our implementation code at https://github.com/abcpp12383/ThreeStageBinarization.
TripleNet: A Low Computing Power Platform of Low-Parameter Network
Apr 02, 2022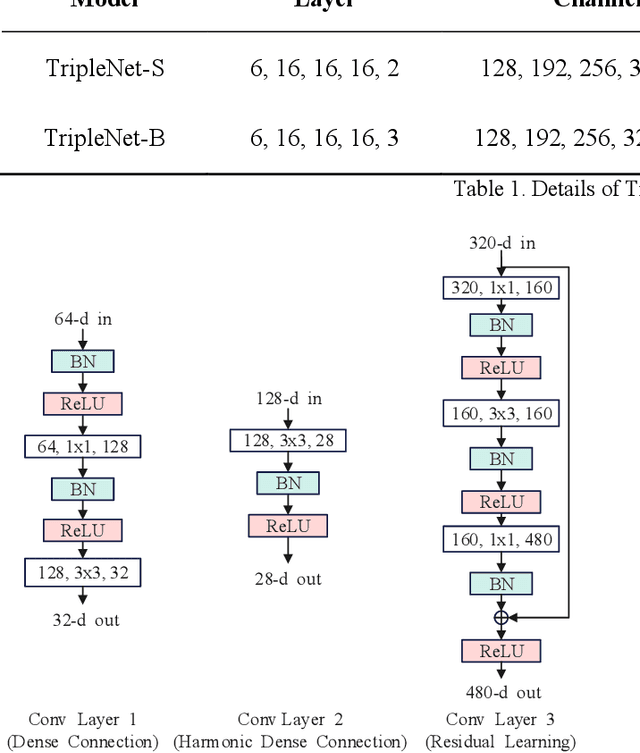

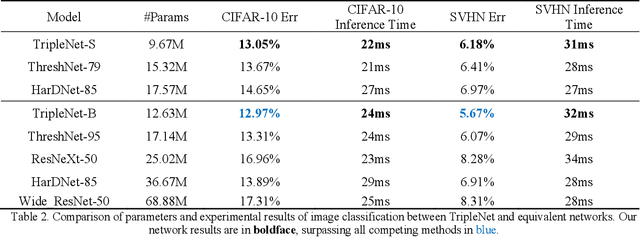
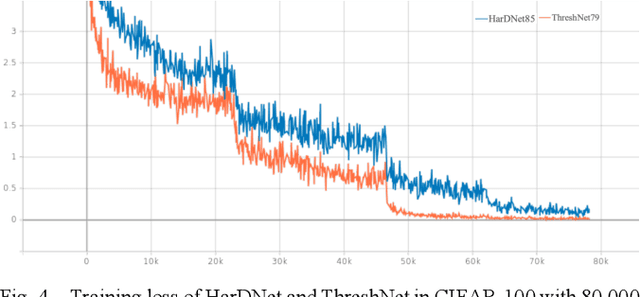
With the excellent performance of deep learning technology in the field of computer vision, convolutional neural network (CNN) architecture has become the main backbone of computer vision task technology. With the widespread use of mobile devices, neural network models based on platforms with low computing power are gradually being paid attention. This paper proposes a lightweight convolutional neural network model, TripleNet, an improved convolutional neural network based on HarDNet and ThreshNet, inheriting the advantages of small memory usage and low power consumption of the mentioned two models. TripleNet uses three different convolutional layers combined into a new model architecture, which has less number of parameters than that of HarDNet and ThreshNet. CIFAR-10 and SVHN datasets were used for image classification by employing HarDNet, ThreshNet, and our proposed TripleNet for verification. Experimental results show that, compared with HarDNet, TripleNet's parameters are reduced by 66% and its accuracy rate is increased by 18%; compared with ThreshNet, TripleNet's parameters are reduced by 37% and its accuracy rate is increased by 5%.
Aggregated Pyramid Vision Transformer: Split-transform-merge Strategy for Image Recognition without Convolutions
Mar 02, 2022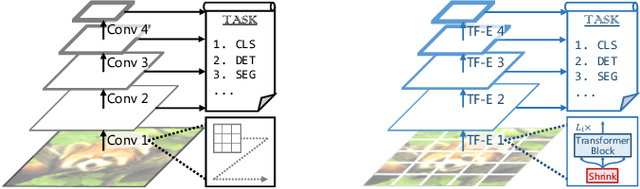
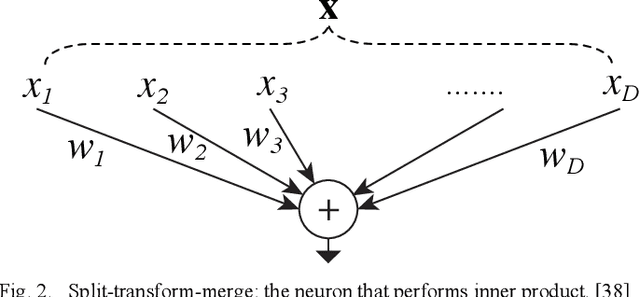


With the achievements of Transformer in the field of natural language processing, the encoder-decoder and the attention mechanism in Transformer have been applied to computer vision. Recently, in multiple tasks of computer vision (image classification, object detection, semantic segmentation, etc.), state-of-the-art convolutional neural networks have introduced some concepts of Transformer. This proves that Transformer has a good prospect in the field of image recognition. After Vision Transformer was proposed, more and more works began to use self-attention to completely replace the convolutional layer. This work is based on Vision Transformer, combined with the pyramid architecture, using Split-transform-merge to propose the group encoder and name the network architecture Aggregated Pyramid Vision Transformer (APVT). We perform image classification tasks on the CIFAR-10 dataset and object detection tasks on the COCO 2017 dataset. Compared with other network architectures that use Transformer as the backbone, APVT has excellent results while reducing the computational cost. We hope this improved strategy can provide a reference for future Transformer research in computer vision.
ThreshNet: An Efficient DenseNet using Threshold Mechanism to Reduce Connections
Jan 09, 2022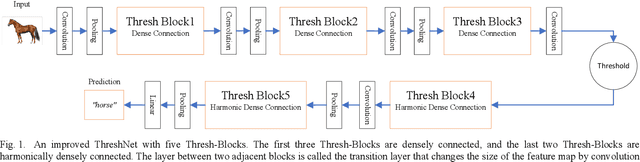
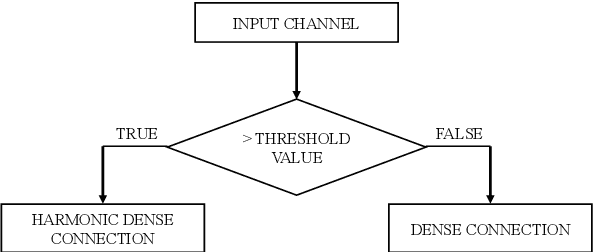
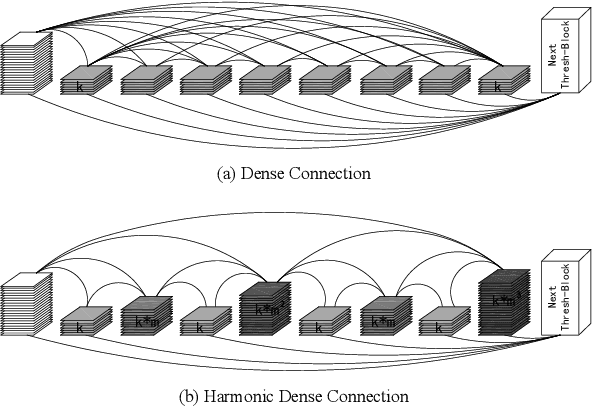
With the continuous development of neural networks in computer vision tasks, more and more network architectures have achieved outstanding success. As one of the most advanced neural network architectures, DenseNet shortcuts all feature maps to solve the problem of model depth. Although this network architecture has excellent accuracy at low MACs (multiplications and accumulations), it takes excessive inference time. To solve this problem, HarDNet reduces the connections between feature maps, making the remaining connections resemble harmonic waves. However, this compression method may result in decreasing model accuracy and increasing MACs and model size. This network architecture only reduces the memory access time, its overall performance still needs to be improved. Therefore, we propose a new network architecture using threshold mechanism to further optimize the method of connections. Different numbers of connections for different convolutional layers are discarded to compress the feature maps in ThreshNet. The proposed network architecture used three datasets, CIFAR-10, CIFAR-100, and SVHN, to evaluate the performance for image classifications. Experimental results show that ThreshNet achieves up to 60% reduction in inference time compared to DenseNet, and up to 35% faster training speed and 20% reduction in error rate compared to HarDNet on these datasets.
ThresholdNet: Pruning Tool for Densely Connected Convolutional Networks
Aug 31, 2021
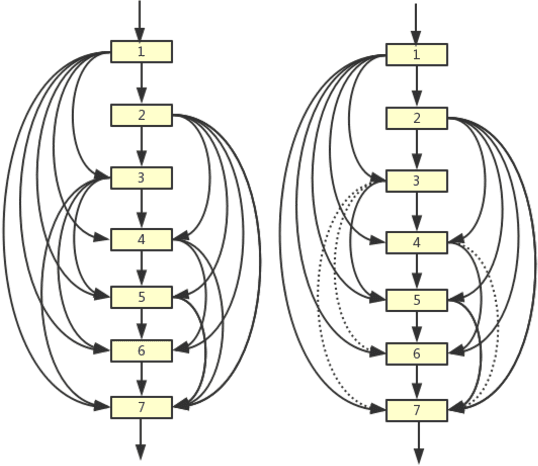
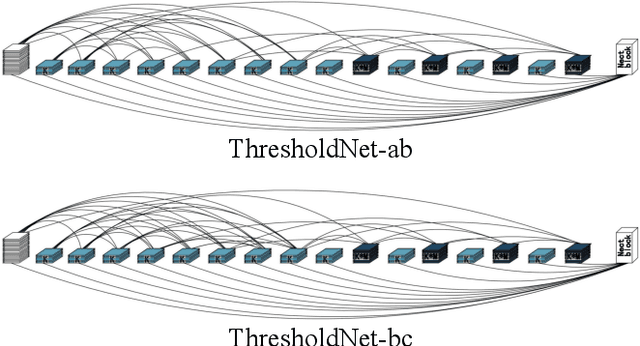
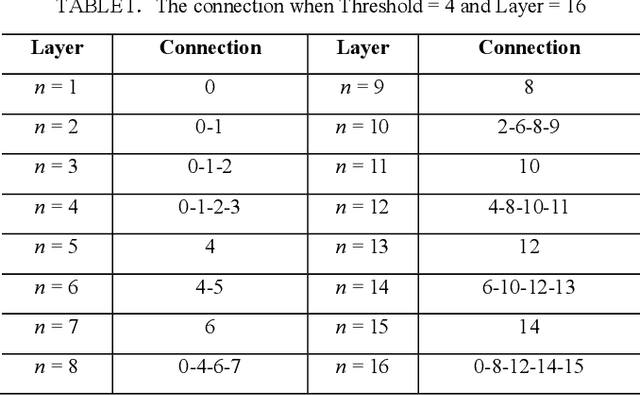
Deep neural networks have made significant progress in the field of computer vision. Recent studies have shown that depth, width and shortcut connections of neural network architectures play a crucial role in their performance. One of the most advanced neural network architectures, DenseNet, has achieved excellent convergence rates through dense connections. However, it still has obvious shortcomings in the usage of amount of memory. In this paper, we introduce a new type of pruning tool, threshold, which refers to the principle of the threshold voltage in MOSFET. This work employs this method to connect blocks of different depths in different ways to reduce the usage of memory. It is denoted as ThresholdNet. We evaluate ThresholdNet and other different networks on datasets of CIFAR10. Experiments show that HarDNet is twice as fast as DenseNet, and on this basis, ThresholdNet is 10% faster and 10% lower error rate than HarDNet.