 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripleNet: A Low Computing Power Platform of Low-Parameter Network
Apr 02, 2022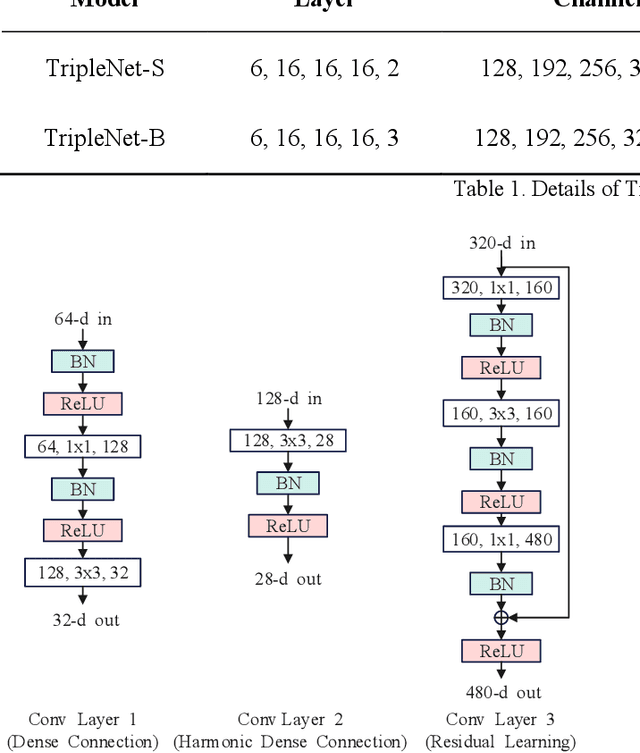

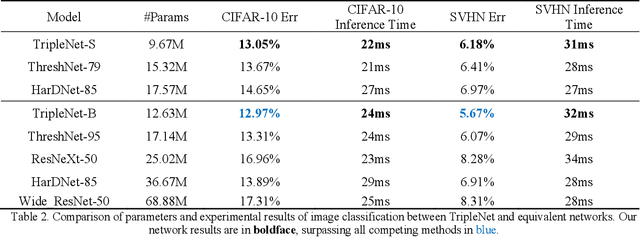
With the excellent performance of deep learning technology in the field of computer vision, convolutional neural network (CNN) architecture has become the main backbone of computer vision task technology. With the widespread use of mobile devices, neural network models based on platforms with low computing power are gradually being paid attention. This paper proposes a lightweight convolutional neural network model, TripleNet, an improved convolutional neural network based on HarDNet and ThreshNet, inheriting the advantages of small memory usage and low power consumption of the mentioned two models. TripleNet uses three different convolutional layers combined into a new model architecture, which has less number of parameters than that of HarDNet and ThreshNet. CIFAR-10 and SVHN datasets were used for image classification by employing HarDNet, ThreshNet, and our proposed TripleNet for verification. Experimental results show that, compared with HarDNet, TripleNet's parameters are reduced by 66% and its accuracy rate is increased by 18%; compared with ThreshNet, TripleNet's parameters are reduced by 37% and its accuracy rate is increased by 5%.
Aggregated Pyramid Vision Transformer: Split-transform-merge Strategy for Image Recognition without Convolutions
Mar 02, 2022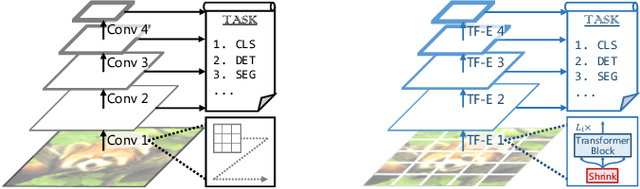
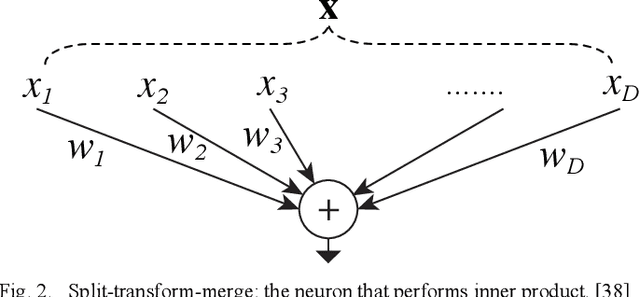


With the achievements of Transformer in the field of natural language processing, the encoder-decoder and the attention mechanism in Transformer have been applied to computer vision. Recently, in multiple tasks of computer vision (image classification, object detection, semantic segmentation, etc.), state-of-the-art convolutional neural networks have introduced some concepts of Transformer. This proves that Transformer has a good prospect in the field of image recognition. After Vision Transformer was proposed, more and more works began to use self-attention to completely replace the convolutional layer. This work is based on Vision Transformer, combined with the pyramid architecture, using Split-transform-merge to propose the group encoder and name the network architecture Aggregated Pyramid Vision Transformer (APVT). We perform image classification tasks on the CIFAR-10 dataset and object detection tasks on the COCO 2017 dataset. Compared with other network architectures that use Transformer as the backbone, APVT has excellent results while reducing the computational cost. We hope this improved strategy can provide a reference for future Transformer research in computer vision.
ThreshNet: An Efficient DenseNet using Threshold Mechanism to Reduce Connections
Jan 09, 2022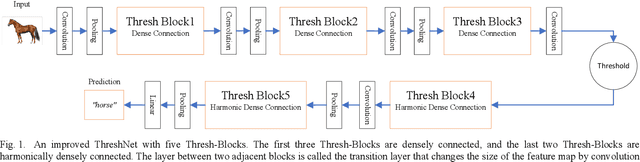
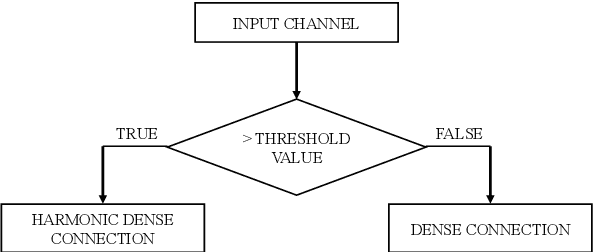
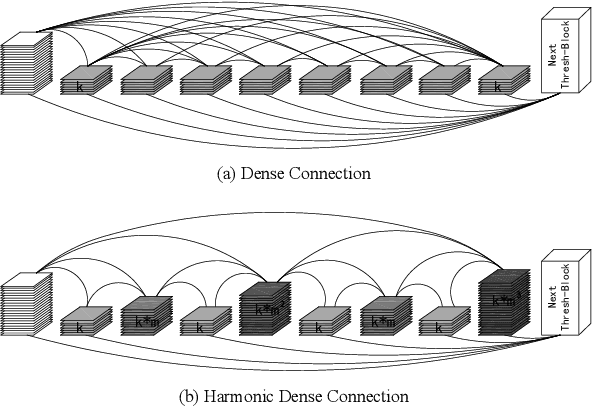
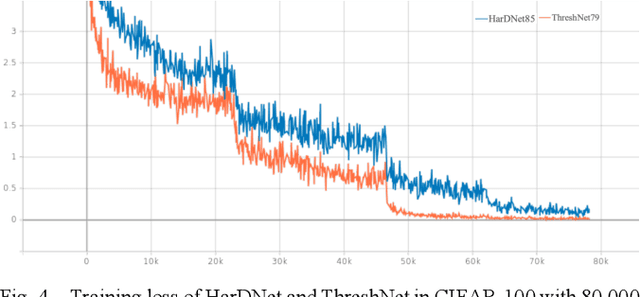
With the continuous development of neural networks in computer vision tasks, more and more network architectures have achieved outstanding success. As one of the most advanced neural network architectures, DenseNet shortcuts all feature maps to solve the problem of model depth. Although this network architecture has excellent accuracy at low MACs (multiplications and accumulations), it takes excessive inference time. To solve this problem, HarDNet reduces the connections between feature maps, making the remaining connections resemble harmonic waves. However, this compression method may result in decreasing model accuracy and increasing MACs and model size. This network architecture only reduces the memory access time, its overall performance still needs to be improved. Therefore, we propose a new network architecture using threshold mechanism to further optimize the method of connections. Different numbers of connections for different convolutional layers are discarded to compress the feature maps in ThreshNet. The proposed network architecture used three datasets, CIFAR-10, CIFAR-100, and SVHN, to evaluate the performance for image classifications. Experimental results show that ThreshNet achieves up to 60% reduction in inference time compared to DenseNet, and up to 35% faster training speed and 20% reduction in error rate compared to HarDNet on these datasets.