 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Choice Analysis with Machine Learning Capabilities
Jan 21, 2021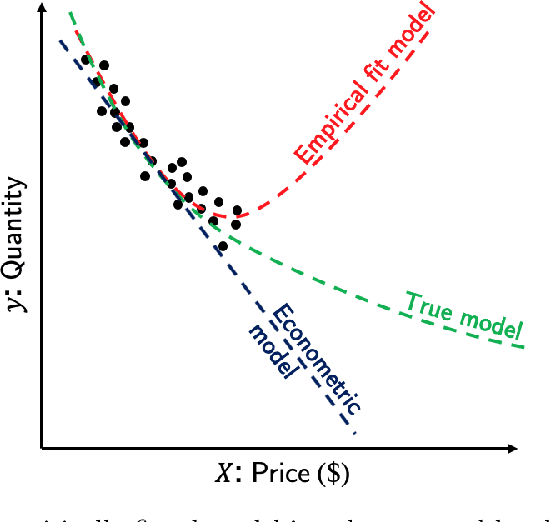
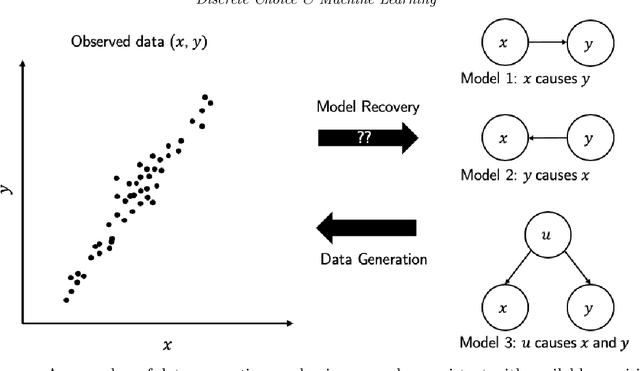
This paper discusses capabilities that are essential to models applied in policy analysis settings and the limitations of direct applications of off-the-shelf machine learning methodologies to such settings. Traditional econometric methodologies for building discrete choice models for policy analysis involve combining data with modeling assumptions guided by subject-matter considerations. Such considerations are typically most useful in specifying the systematic component of random utility discrete choice models but are typically of limited aid in determining the form of the random component. We identify an area where machine learning paradigms can be leveraged, namely in specifying and systematically selecting the best specification of the random component of the utility equations. We review two recent novel applications where mixed-integer optimization and cross-validation are used to algorithmically select optimal specifications for the random utility components of nested logit and logit mixture models subject to interpretability constraints.
Learning Structure in Nested Logit Models
Aug 18, 2020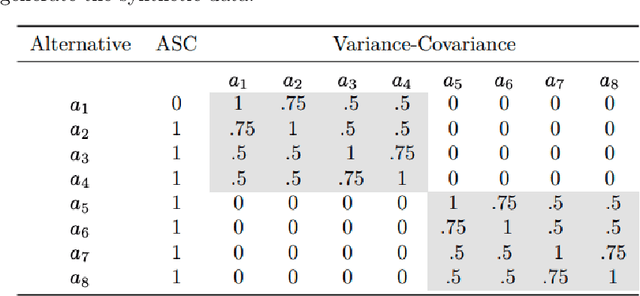
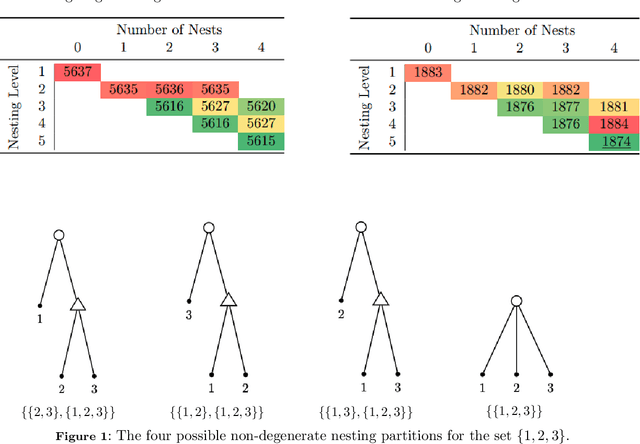
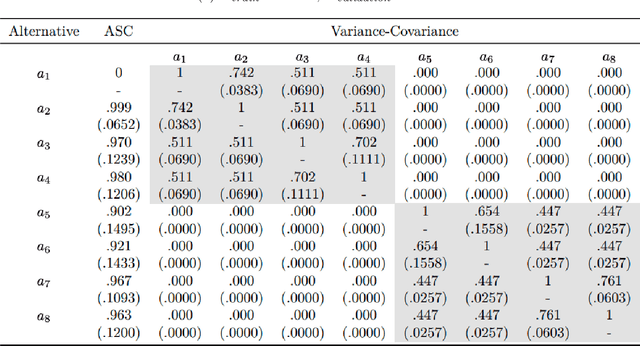
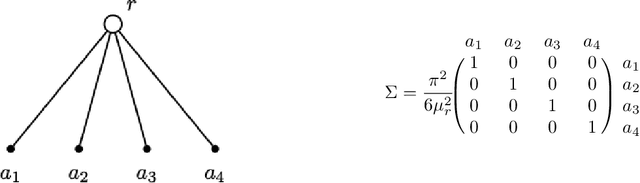
This paper introduces a new data-driven methodology for nested logit structure discovery. Nested logit models allow the modeling of positive correlations between the error terms of the utility specifications of the different alternatives in a discrete choice scenario through the specification of a nesting structure. Current nested logit model estimation practices require an a priori specification of a nesting structure by the modeler. In this we work we optimize over all possible specifications of the nested logit model that are consistent with rational utility maximization. We formulate the problem of learning an optimal nesting structure from the data as a mixed integer nonlinear programming (MINLP) optimization problem and solve it using a variant of the linear outer approximation algorithm. We exploit the tree structure of the problem and utilize the latest advances in integer optimization to bring practical tractability to the optimization problem we introduce. We demonstrate the ability of our algorithm to correctly recover the true nesting structure from synthetic data in a Monte Carlo experiment. In an empirical illustration using a stated preference survey on modes of transportation in the U.S. state of Massachusetts, we use our algorithm to obtain an optimal nesting tree representing the correlations between the unobserved effects of the different travel mode choices. We provide our implementation as a customizable and open-source code base written in the Julia programming language.