 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Choice Analysis with Machine Learning Capabilities
Paper and Code
Jan 21, 2021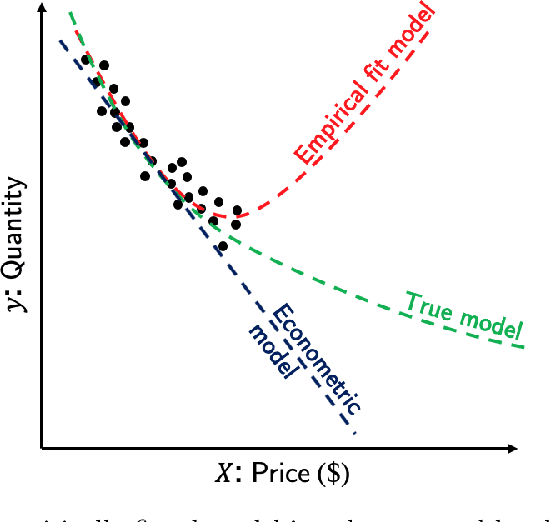
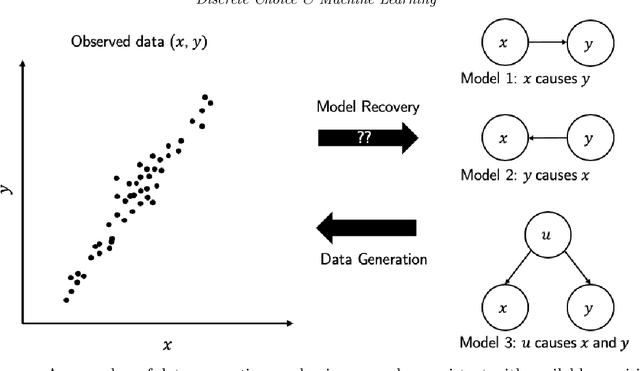
This paper discusses capabilities that are essential to models applied in policy analysis settings and the limitations of direct applications of off-the-shelf machine learning methodologies to such settings. Traditional econometric methodologies for building discrete choice models for policy analysis involve combining data with modeling assumptions guided by subject-matter considerations. Such considerations are typically most useful in specifying the systematic component of random utility discrete choice models but are typically of limited aid in determining the form of the random component. We identify an area where machine learning paradigms can be leveraged, namely in specifying and systematically selecting the best specification of the random component of the utility equations. We review two recent novel applications where mixed-integer optimization and cross-validation are used to algorithmically select optimal specifications for the random utility components of nested logit and logit mixture models subject to interpretability constraints.