 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Static and Dynamic Attention Framework for Multi Turn Dialogue Generation
Oct 28, 2024



Recently, research on open domain dialogue systems have attracted extensive interests of academic and industrial researchers. The goal of an open domain dialogue system is to imitate humans in conversations. Previous works on single turn conversation generation have greatly promoted the research of open domain dialogue systems. However, understanding multiple single turn conversations is not equal to the understanding of multi turn dialogue due to the coherent and context dependent properties of human dialogue. Therefore, in open domain multi turn dialogue generation, it is essential to modeling the contextual semantics of the dialogue history, rather than only according to the last utterance. Previous research had verified the effectiveness of the hierarchical recurrent encoder-decoder framework on open domain multi turn dialogue generation. However, using RNN-based model to hierarchically encoding the utterances to obtain the representation of dialogue history still face the problem of a vanishing gradient. To address this issue, in this paper, we proposed a static and dynamic attention-based approach to model the dialogue history and then generate open domain multi turn dialogue responses. Experimental results on Ubuntu and Opensubtitles datasets verify the effectiveness of the proposed static and dynamic attention-based approach on automatic and human evaluation metrics in various experimental settings. Meanwhile, we also empirically verify the performance of combining the static and dynamic attentions on open domain multi turn dialogue generation.
* published as a journal paper at ACM Transactions on Information Systems 2023. 30 pages, 6 figures
Neural Personalized Response Generation as Domain Adaptation
Jan 09, 2017
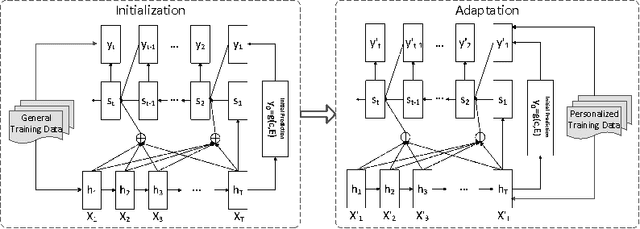

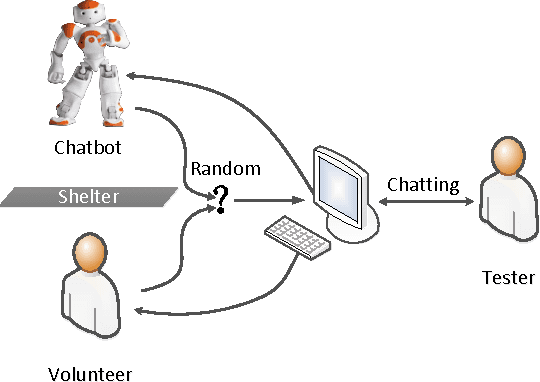
In this paper, we focus on the personalized response generation for conversational systems. Based on the sequence to sequence learning, especially the encoder-decoder framework, we propose a two-phase approach, namely initialization then adaptation, to model the responding style of human and then generate personalized responses. For evaluation, we propose a novel human aided method to evaluate the performance of the personalized response generation models by online real-time conversation and offline human judgement. Moreover, the lexical divergence of the responses generated by the 5 personalized models indicates that the proposed two-phase approach achieves good results on modeling the responding style of human and generating personalized responses for the conversational systems.