 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion
Oct 08, 2024



As remote sensing imaging technology continues to advance and evolve, processing high-resolution and diversified satellite imagery to improve segmentation accuracy and enhance interpretation efficiency emerg as a pivotal area of investigation within the realm of remote sensing. Although segmentation algorithms based on CNNs and Transformers achieve significant progress in performance, balancing segmentation accuracy and computational complexity remains challenging, limiting their wide application in practical tasks. To address this, this paper introduces state space model (SSM) and proposes a novel hybrid semantic segmentation network based on vision Mamba (CVMH-UNet). This method designs a cross-scanning visual state space block (CVSSBlock) that uses cross 2D scanning (CS2D) to fully capture global information from multiple directions, while by incorporating convolutional neural network branches to overcome the constraints of Vision Mamba (VMamba) in acquiring local information, this approach facilitates a comprehensive analysis of both global and local features. Furthermore, to address the issue of limited discriminative power and the difficulty in achieving detailed fusion with direct skip connections, a multi-frequency multi-scale feature fusion block (MFMSBlock) is designed. This module introduces multi-frequency information through 2D discrete cosine transform (2D DCT) to enhance information utilization and provides additional scale local detail information through point-wise convolution branches. Finally, it aggregates multi-scale information along the channel dimension, achieving refined feature fusion. Findings from experiments conducted on renowned datasets of remote sensing imagery demonstrate that proposed CVMH-UNet achieves superior segmentation performance while maintaining low computational complexity, outperforming surpassing current leading-edge segmentation algorithms.
Multi-frequency PolSAR Image Fusion Classification Based on Semantic Interactive Information and Topological Structure
Sep 05, 2022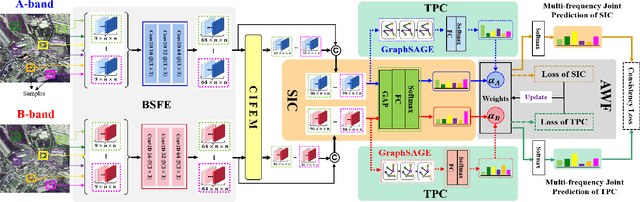
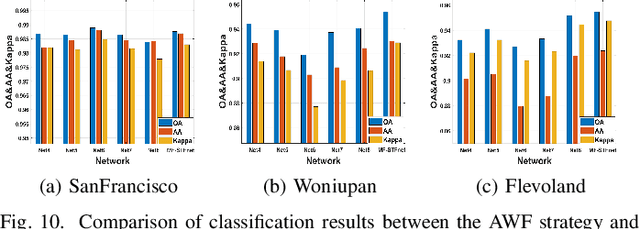
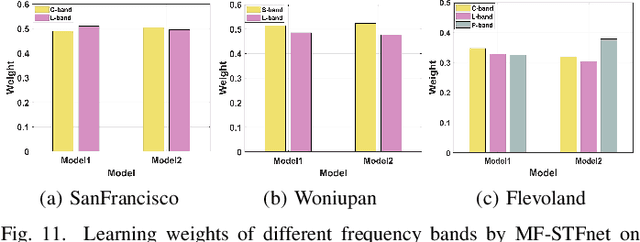
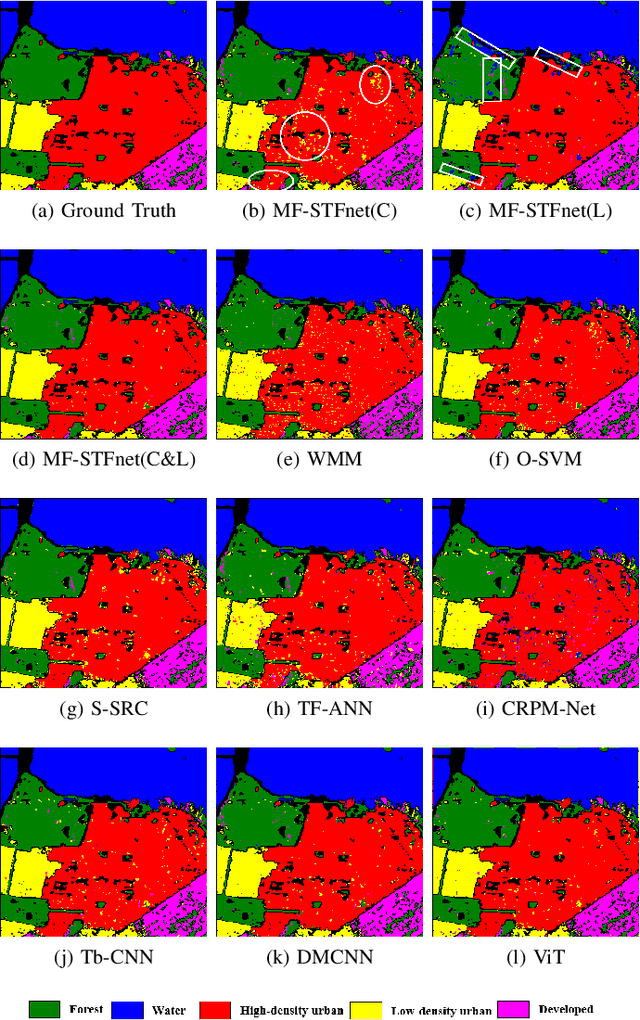
Compared with the rapid development of single-frequency multi-polarization SAR image classification technology, there is less research on the land cover classification of multifrequency polarimetric SAR (MF-PolSAR) images. In addition, the current deep learning methods for MF-PolSAR classification are mainly based on convolutional neural networks (CNNs), only local spatiality is considered but the nonlocal relationship is ignored. Therefore, based on semantic interaction and nonlocal topological structure, this paper proposes the MF semantics and topology fusion network (MF-STFnet) to improve MF-PolSAR classification performance. In MF-STFnet, two kinds of classification are implemented for each band, semantic information-based (SIC) and topological property-based (TPC). They work collaboratively during MF-STFnet training, which can not only fully leverage the complementarity of bands, but also combine local and nonlocal spatial information to improve the discrimination between different categories. For SIC, the designed crossband interactive feature extraction module (CIFEM) is embedded to explicitly model the deep semantic correlation among bands, thereby leveraging the complementarity of bands to make ground objects more separable. For TPC, the graph sample and aggregate network (GraphSAGE) is employed to dynamically capture the representation of nonlocal topological relations between land cover categories. In this way, the robustness of classification can be further improved by combining nonlocal spatial information. Finally, an adaptive weighting fusion (AWF) strategy is proposed to merge inference from different bands, so as to make the MF joint classification decisions of SIC and TPC. The comparative experiments show that MF-STFnet can achieve more competitive classification performance than some state-of-the-art methods.
A Feature Fusion-Net Using Deep Spatial Context Encoder and Nonstationary Joint Statistical Model for High Resolution SAR Image Classification
May 11, 2021
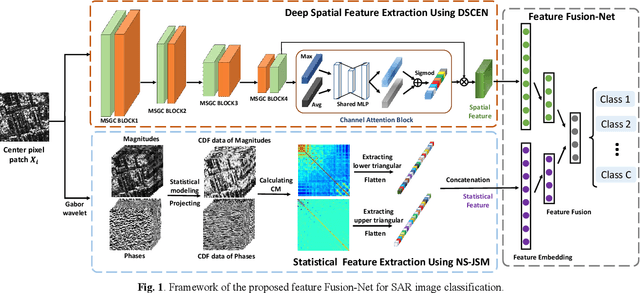
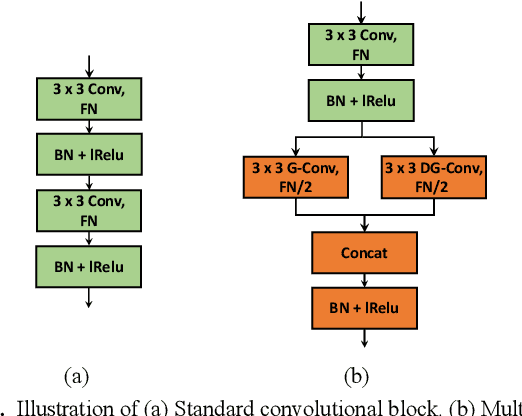
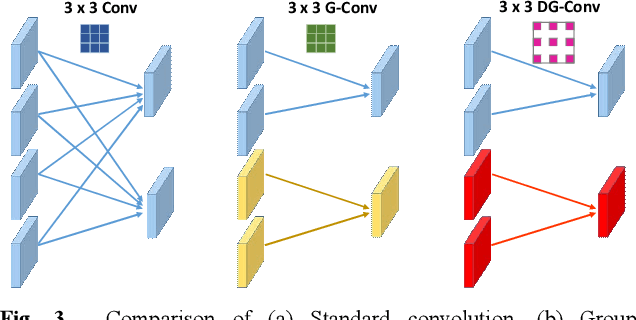
Convolutional neural networks (CNNs) have been applied to learn spatial features for high-resolution (HR) synthetic aperture radar (SAR) image classification. However, there has been little work on integrating the unique statistical distributions of SAR images which can reveal physical properties of terrain objects, into CNNs in a supervised feature learning framework. To address this problem, a novel end-to-end supervised classification method is proposed for HR SAR images by considering both spatial context and statistical features. First, to extract more effective spatial features from SAR images, a new deep spatial context encoder network (DSCEN) is proposed, which is a lightweight structure and can be effectively trained with a small number of samples. Meanwhile, to enhance the diversity of statistics, the nonstationary joint statistical model (NS-JSM) is adopted to form the global statistical features. Specifically, SAR images are transformed into the Gabor wavelet domain and the produced multi-subbands magnitudes and phases are modeled by the log-normal and uniform distribution. The covariance matrix is further utilized to capture the inter-scale and intra-scale nonstationary correlation between the statistical subbands and make the joint statistical features more compact and distinguishable. Considering complementary advantages, a feature fusion network (Fusion-Net) base on group compression and smooth normalization is constructed to embed the statistical features into the spatial features and optimize the fusion feature representation. As a result, our model can learn the discriminative features and improve the final classification performance. Experiments on four HR SAR images validate the superiority of the proposed method over other related algorithms.
Pixel-Wise PolSAR Image Classification via a Novel Complex-Valued Deep Fully Convolutional Network
Sep 29, 2019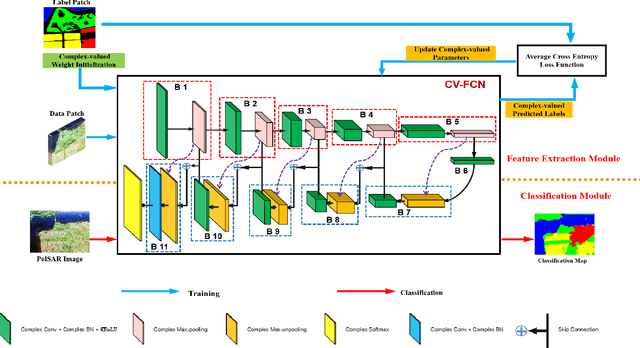
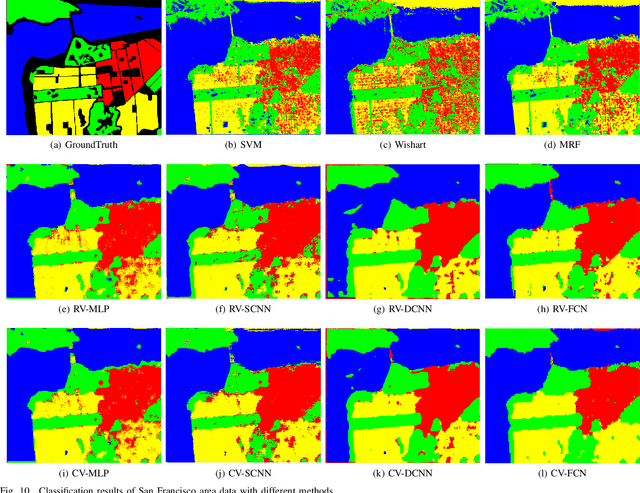
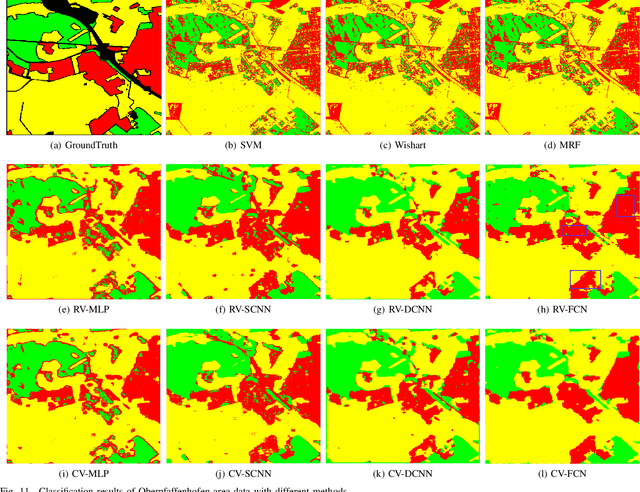
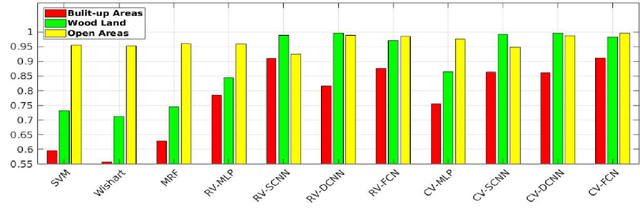
Although complex-valued (CV) neural networks have shown better classification results compared to their real-valued (RV) counterparts for polarimetric synthetic aperture radar (PolSAR) classification, the extension of pixel-level RV networks to the complex domain has not yet thoroughly examined. This paper presents a novel complex-valued deep fully convolutional neural network (CV-FCN) designed for PolSAR image classification. Specifically, CV-FCN uses PolSAR CV data that includes the phase information and utilizes the deep FCN architecture that performs pixel-level labeling. It integrates the feature extraction module and the classification module in a united framework. Technically, for the particularity of PolSAR data, a dedicated complex-valued weight initialization scheme is defined to initialize CV-FCN. It considers the distribution of polarization data to conduct CV-FCN training from scratch in an efficient and fast manner. CV-FCN employs a complex downsampling-then-upsampling scheme to extract dense features. To enrich discriminative information, multi-level CV features that retain more polarization information are extracted via the complex downsampling scheme. Then, a complex upsampling scheme is proposed to predict dense CV labeling. It employs complex max-unpooling layers to greatly capture more spatial information for better robustness to speckle noise. In addition, to achieve faster convergence and obtain more precise classification results, a novel average cross-entropy loss function is derived for CV-FCN optimization. Experiments on real PolSAR datasets demonstrate that CV-FCN achieves better classification performance than other state-of-art methods.