 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenging Instances are Worth Learning: Generating Valuable Negative Samples for Response Selection Training
Sep 14, 2021
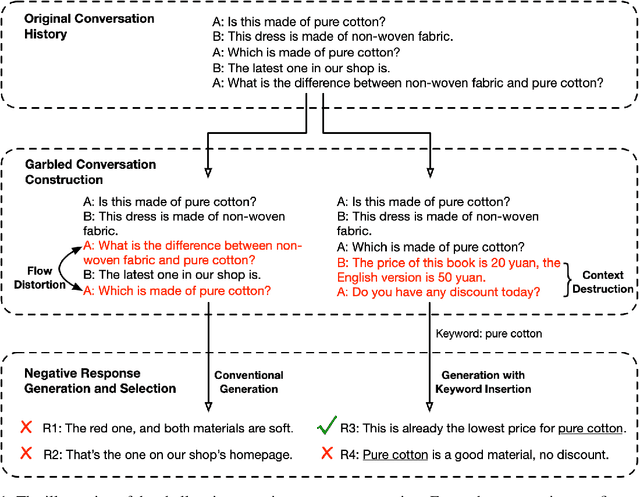

Retrieval-based chatbot selects the appropriate response from candidates according to the context, which heavily depends on a response selection module. A response selection module is generally a scoring model to evaluate candidates and is usually trained on the annotated positive response and sampled negative responses. Sampling negative responses lead to two risks: a). The sampled negative instances, especially that from random sampling methods, are mostly irrelevant to the dialogue context and too easy to be fitted at the training stage while causing a weak model in the real scenario. b). The so-called negative instances may be positive, which is known as the fake negative problem. To address the above issue, we employ pre-trained language models, such as the DialoGPT to construct more challenging negative instances to enhance the model robustness. Specifically, we provide garbled context to the pre-trained model to generate responses and filter the fake negative ones. In this way, our negative instances are fluent, context-related, and more challenging for the model to learn, while can not be positive. Extensive experiments show that our method brings significant and stable improvements on the dialogue response selection capacity.
Improving Gradient-based Adversarial Training for Text Classification by Contrastive Learning and Auto-Encoder
Sep 14, 2021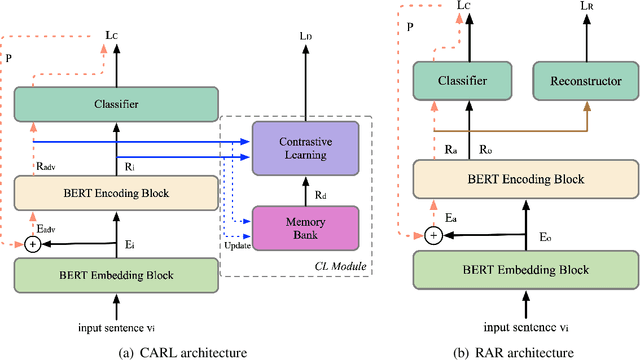

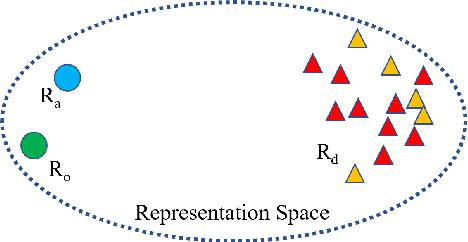

Recent work has proposed several efficient approaches for generating gradient-based adversarial perturbations on embeddings and proved that the model's performance and robustness can be improved when they are trained with these contaminated embeddings. While they paid little attention to how to help the model to learn these adversarial samples more efficiently. In this work, we focus on enhancing the model's ability to defend gradient-based adversarial attack during the model's training process and propose two novel adversarial training approaches: (1) CARL narrows the original sample and its adversarial sample in the representation space while enlarging their distance from different labeled samples. (2) RAR forces the model to reconstruct the original sample from its adversarial representation. Experiments show that the proposed two approaches outperform strong baselines on various text classification datasets. Analysis experiments find that when using our approaches, the semantic representation of the input sentence won't be significantly affected by adversarial perturbations, and the model's performance drops less under adversarial attack. That is to say, our approaches can effectively improve the robustness of the model. Besides, RAR can also be used to generate text-form adversarial samples.
Different Strokes for Different Folks: Investigating Appropriate Further Pre-training Approaches for Diverse Dialogue Tasks
Sep 14, 2021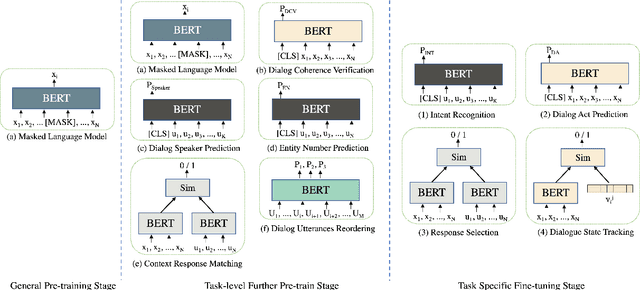
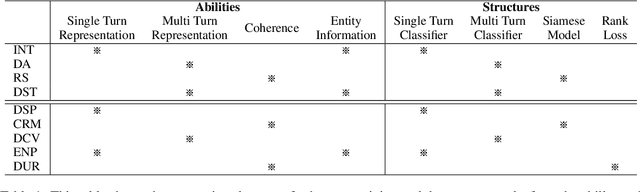


Loading models pre-trained on the large-scale corpus in the general domain and fine-tuning them on specific downstream tasks is gradually becoming a paradigm in Natural Language Processing. Previous investigations prove that introducing a further pre-training phase between pre-training and fine-tuning phases to adapt the model on the domain-specific unlabeled data can bring positive effects. However, most of these further pre-training works just keep running the conventional pre-training task, e.g., masked language model, which can be regarded as the domain adaptation to bridge the data distribution gap. After observing diverse downstream tasks, we suggest that different tasks may also need a further pre-training phase with appropriate training tasks to bridge the task formulation gap. To investigate this, we carry out a study for improving multiple task-oriented dialogue downstream tasks through designing various tasks at the further pre-training phase. The experiment shows that different downstream tasks prefer different further pre-training tasks, which have intrinsic correlation and most further pre-training tasks significantly improve certain target tasks rather than all. Our investigation indicates that it is of great importance and effectiveness to design appropriate further pre-training tasks modeling specific information that benefit downstream tasks. Besides, we present multiple constructive empirical conclusions for enhancing task-oriented dialogues.
Structure-Enhanced Pop Music Generation via Harmony-Aware Learning
Sep 14, 2021



Automatically composing pop music with a satisfactory structure is an attractive but challenging topic. Although the musical structure is easy to be perceived by human, it is difficult to be described clearly and defined accurately. And it is still far from being solved that how we should model the structure in pop music generation. In this paper, we propose to leverage harmony-aware learning for structure-enhanced pop music generation. On the one hand, one of the participants of harmony, chord, represents the harmonic set of multiple notes, which is integrated closely with the spatial structure of music, texture. On the other hand, the other participant of harmony, chord progression, usually accompanies with the development of the music, which promotes the temporal structure of music, form. Besides, when chords evolve into chord progression, the texture and the form can be bridged by the harmony naturally, which contributes to the joint learning of the two structures. Furthermore, we propose the Harmony-Aware Hierarchical Music Transformer (HAT), which can exploit the structure adaptively from the music, and interact on the music tokens at multiple levels to enhance the signals of the structure in various musical elements. Results of subjective and objective evaluations demonstrate that HAT significantly improves the quality of generated music, especially in the structureness.
Guiding Topic Flows in the Generative Chatbot by Enhancing the ConceptNet with the Conversation Corpora
Sep 14, 2021

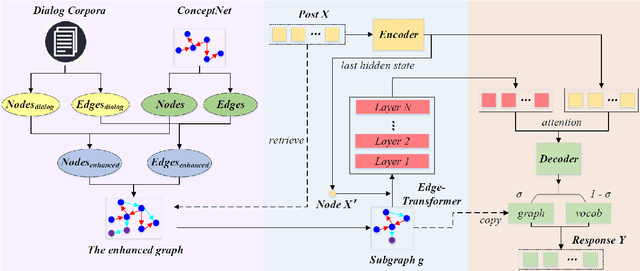
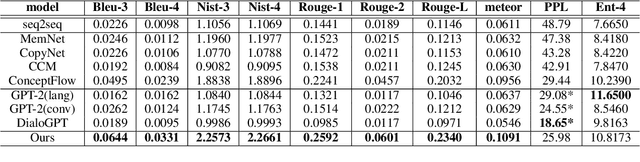
Human conversations consist of reasonable and natural topic flows, which are observed as the shifts of the mentioned concepts across utterances. Previous chatbots that incorporate the external commonsense knowledge graph prove that modeling the concept shifts can effectively alleviate the dull and uninformative response dilemma. However, there still exists a gap between the concept relations in the natural conversation and those in the external commonsense knowledge graph, which is an issue to solve. Specifically, the concept relations in the external commonsense knowledge graph are not intuitively built from the conversational scenario but the world knowledge, which makes them insufficient for the chatbot construction. To bridge the above gap, we propose the method to supply more concept relations extracted from the conversational corpora and reconstruct an enhanced concept graph for the chatbot construction. In addition, we present a novel, powerful, and fast graph encoding architecture named the Edge-Transformer to replace the traditional GNN architecture. Experimental results on the Reddit conversation dataset indicate our proposed method significantly outperforms strong baseline systems and achieves new SOTA results. Further analysis individually proves the effectiveness of the enhanced concept graph and the Edge-Transformer architecture.