 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenging Instances are Worth Learning: Generating Valuable Negative Samples for Response Selection Training
Paper and Code

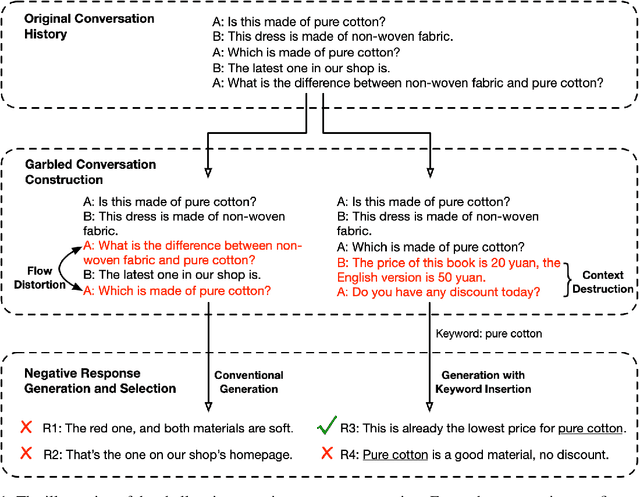
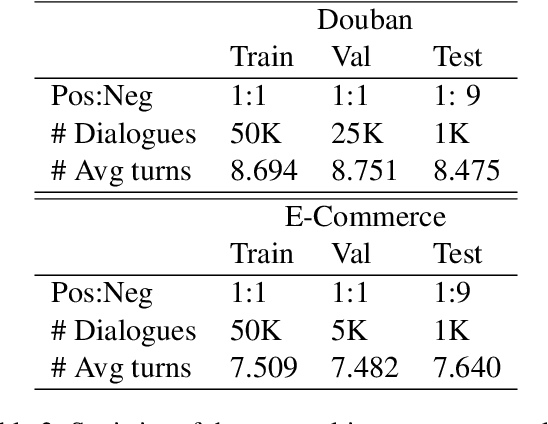

Retrieval-based chatbot selects the appropriate response from candidates according to the context, which heavily depends on a response selection module. A response selection module is generally a scoring model to evaluate candidates and is usually trained on the annotated positive response and sampled negative responses. Sampling negative responses lead to two risks: a). The sampled negative instances, especially that from random sampling methods, are mostly irrelevant to the dialogue context and too easy to be fitted at the training stage while causing a weak model in the real scenario. b). The so-called negative instances may be positive, which is known as the fake negative problem. To address the above issue, we employ pre-trained language models, such as the DialoGPT to construct more challenging negative instances to enhance the model robustness. Specifically, we provide garbled context to the pre-trained model to generate responses and filter the fake negative ones. In this way, our negative instances are fluent, context-related, and more challenging for the model to learn, while can not be positive. Extensive experiments show that our method brings significant and stable improvements on the dialogue response selection capacity.