 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying outliers in astronomical images with unsupervised machine learning
May 19, 2022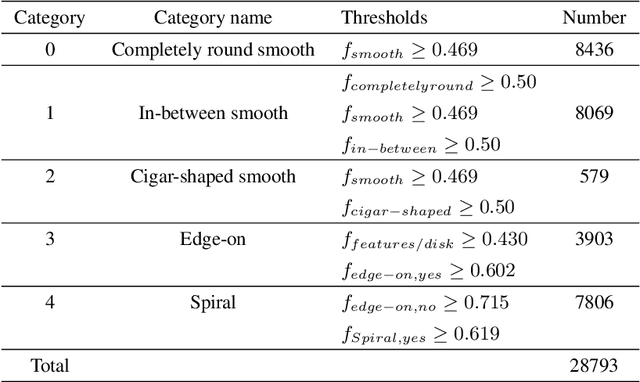
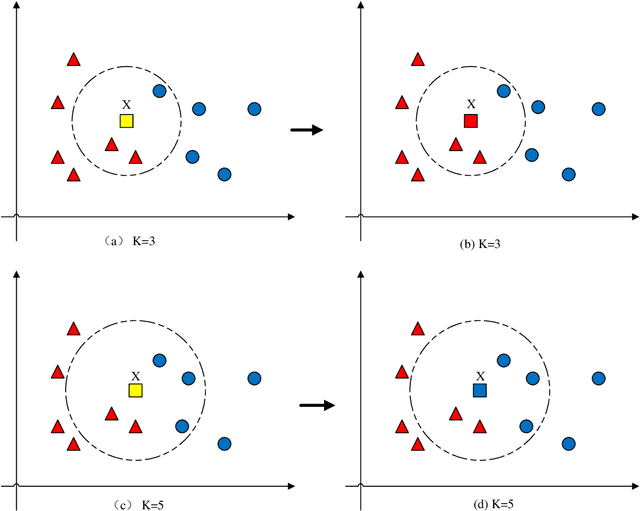
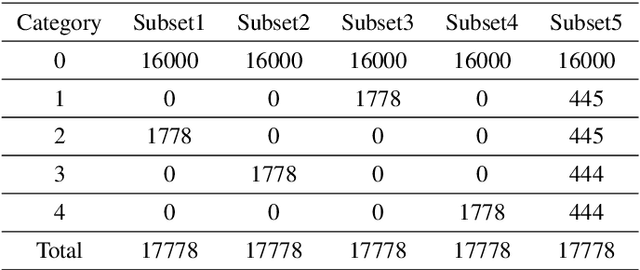
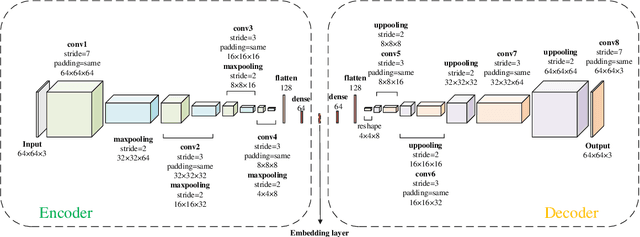
Astronomical outliers, such as unusual, rare or unknown types of astronomical objects or phenomena, constantly lead to the discovery of genuinely unforeseen knowledge in astronomy. More unpredictable outliers will be uncovered in principle with the increment of the coverage and quality of upcoming survey data. However, it is a severe challenge to mine rare and unexpected targets from enormous data with human inspection due to a significant workload. Supervised learning is also unsuitable for this purpose since designing proper training sets for unanticipated signals is unworkable. Motivated by these challenges, we adopt unsupervised machine learning approaches to identify outliers in the data of galaxy images to explore the paths for detecting astronomical outliers. For comparison, we construct three methods, which are built upon the k-nearest neighbors (KNN), Convolutional Auto-Encoder (CAE)+ KNN, and CAE + KNN + Attention Mechanism (attCAE KNN) separately. Testing sets are created based on the Galaxy Zoo image data published online to evaluate the performance of the above methods. Results show that attCAE KNN achieves the best recall (78%), which is 53% higher than the classical KNN method and 22% higher than CAE+KNN. The efficiency of attCAE KNN (10 minutes) is also superior to KNN (4 hours) and equal to CAE+KNN(10 minutes) for accomplishing the same task. Thus, we believe it is feasible to detect astronomical outliers in the data of galaxy images in an unsupervised manner. Next, we will apply attCAE KNN to available survey datasets to assess its applicability and reliability.
The MSXF TTS System for ICASSP 2022 ADD Challenge
Jan 27, 2022
This paper presents our MSXF TTS system for Task 3.1 of the Audio Deep Synthesis Detection (ADD) Challenge 2022. We use an end to end text to speech system, and add a constraint loss to the system when training stage. The end to end TTS system is VITS, and the pre-training self-supervised model is wav2vec 2.0. And we also explore the influence of the speech speed and volume in spoofing. The faster speech means the less the silence part in audio, the easier to fool the detector. We also find the smaller the volume, the better spoofing ability, though we normalize volume for submission. Our team is identified as C2, and we got the fourth place in the challenge.
Beijing ZKJ-NPU Speaker Verification System for VoxCeleb Speaker Recognition Challenge 2021
Sep 08, 2021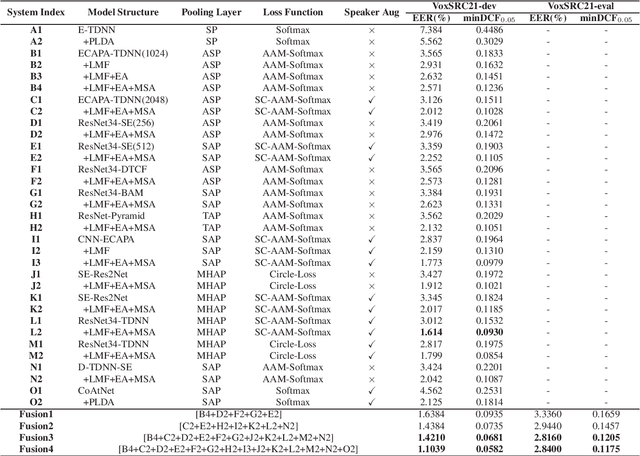
In this report, we describe the Beijing ZKJ-NPU team submission to the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). We participated in the fully supervised speaker verification track 1 and track 2. In the challenge, we explored various kinds of advanced neural network structures with different pooling layers and objective loss functions. In addition, we introduced the ResNet-DTCF, CoAtNet and PyConv networks to advance the performance of CNN-based speaker embedding model. Moreover, we applied embedding normalization and score normalization at the evaluation stage. By fusing 11 and 14 systems, our final best performances (minDCF/EER) on the evaluation trails are 0.1205/2.8160% and 0.1175/2.8400% respectively for track 1 and 2. With our submission, we came to the second place in the challenge for both tracks.