 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSphereUFormer: A U-Shaped Transformer for Spherical 360 Perception
Dec 09, 2024



This paper proposes a novel method for omnidirectional 360$\degree$ perception. Most common previous methods relied on equirectangular projection. This representation is easily applicable to 2D operation layers but introduces distortions into the image. Other methods attempted to remove the distortions by maintaining a sphere representation but relied on complicated convolution kernels that failed to show competitive results. In this work, we introduce a transformer-based architecture that, by incorporating a novel ``Spherical Local Self-Attention'' and other spherically-oriented modules, successfully operates in the spherical domain and outperforms the state-of-the-art in 360$\degree$ perception benchmarks for depth estimation and semantic segmentation.
Dynamic Dual-Output Diffusion Models
Mar 15, 2022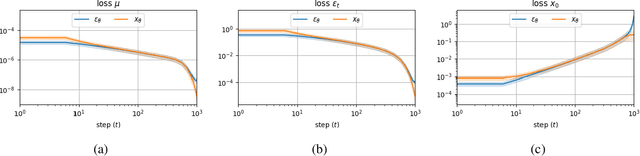
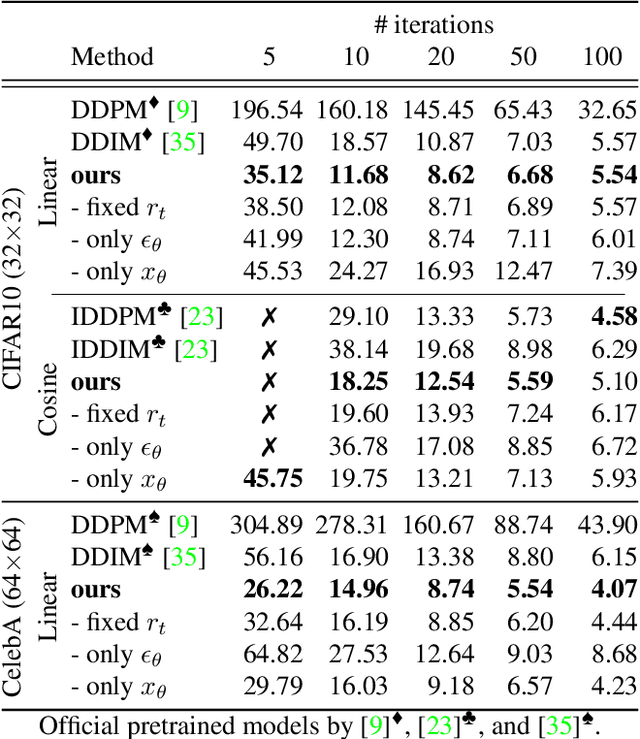
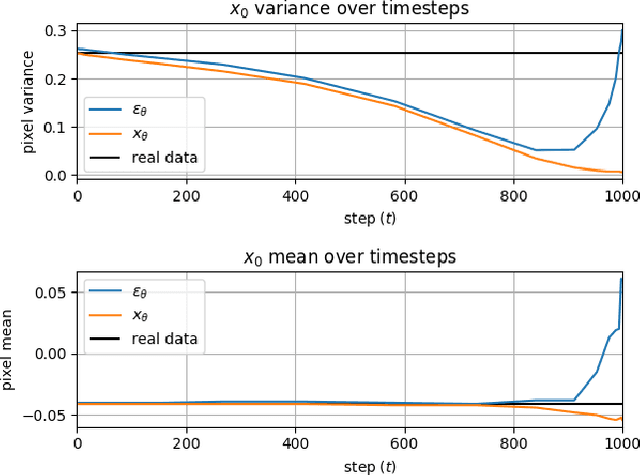
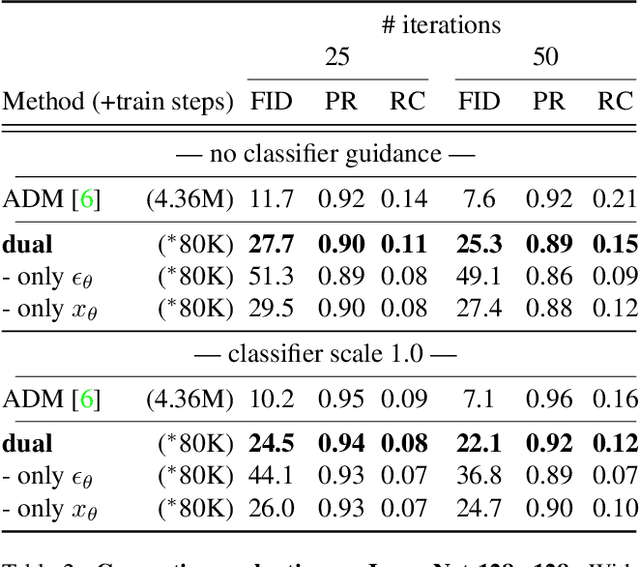
Iterative denoising-based generation, also known as denoising diffusion models, has recently been shown to be comparable in quality to other classes of generative models, and even surpass them. Including, in particular, Generative Adversarial Networks, which are currently the state of the art in many sub-tasks of image generation. However, a major drawback of this method is that it requires hundreds of iterations to produce a competitive result. Recent works have proposed solutions that allow for faster generation with fewer iterations, but the image quality gradually deteriorates with increasingly fewer iterations being applied during generation. In this paper, we reveal some of the causes that affect the generation quality of diffusion models, especially when sampling with few iterations, and come up with a simple, yet effective, solution to mitigate them. We consider two opposite equations for the iterative denoising, the first predicts the applied noise, and the second predicts the image directly. Our solution takes the two options and learns to dynamically alternate between them through the denoising process. Our proposed solution is general and can be applied to any existing diffusion model. As we show, when applied to various SOTA architectures, our solution immediately improves their generation quality, with negligible added complexity and parameters. We experiment on multiple datasets and configurations and run an extensive ablation study to support these findings.
Generating Correct Answers for Progressive Matrices Intelligence Tests
Nov 01, 2020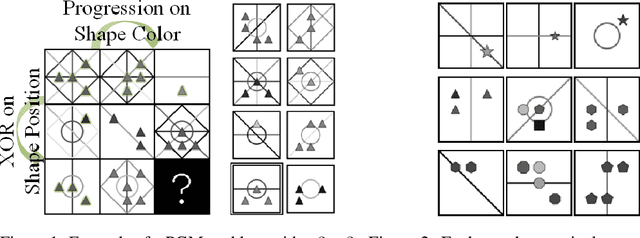
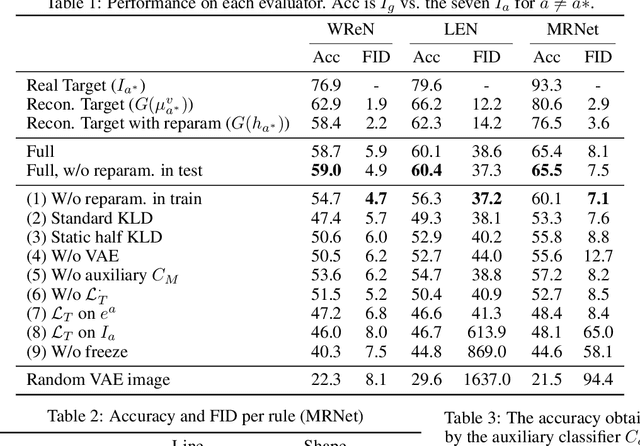
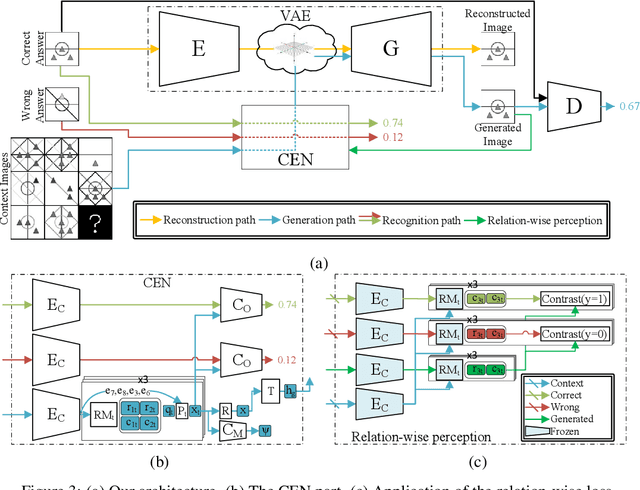
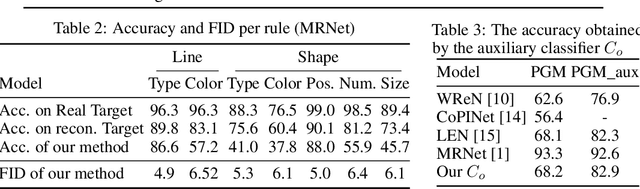
Raven's Progressive Matrices are multiple-choice intelligence tests, where one tries to complete the missing location in a $3\times 3$ grid of abstract images. Previous attempts to address this test have focused solely on selecting the right answer out of the multiple choices. In this work, we focus, instead, on generating a correct answer given the grid, without seeing the choices, which is a harder task, by definition. The proposed neural model combines multiple advances in generative models, including employing multiple pathways through the same network, using the reparameterization trick along two pathways to make their encoding compatible, a dynamic application of variational losses, and a complex perceptual loss that is coupled with a selective backpropagation procedure. Our algorithm is able not only to generate a set of plausible answers, but also to be competitive to the state of the art methods in multiple-choice tests.
Scene Graph to Image Generation with Contextualized Object Layout Refinement
Sep 24, 2020

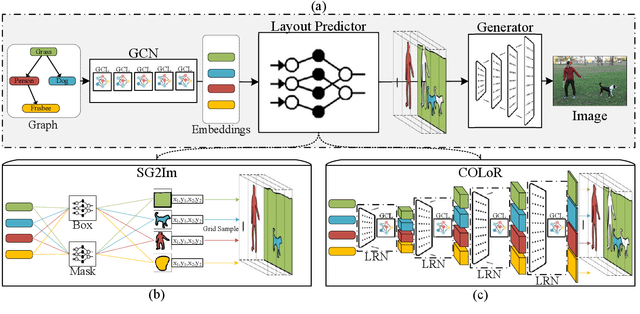
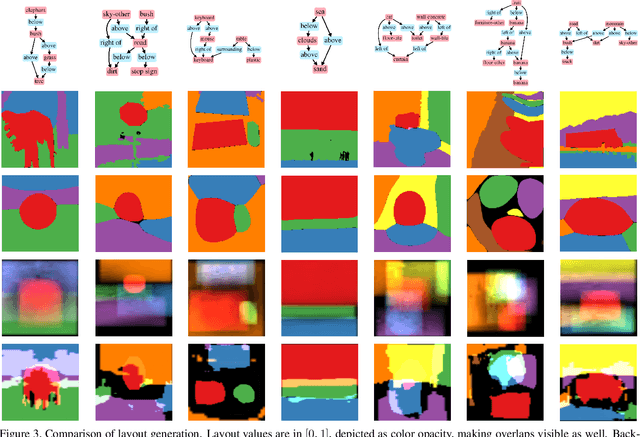
Generating high-quality images from scene graphs, that is, graphs that describe multiple entities in complex relations, is a challenging task that attracted substantial interest recently. Prior work trained such models by using supervised learning, where the goal is to produce the exact target image layout for each scene graph. It relied on predicting object locations and shapes independently and in parallel. However, scene graphs are underspecified, and thus the same scene graph often occurs with many target images in the training data. This leads to generated images with high inter-object overlap, empty areas, blurry objects, and overall compromised quality. In this work, we propose a method that alleviates these issues by generating all object layouts together and reducing the reliance on such supervision. Our model predicts layouts directly from embeddings (without predicting intermediate boxes) by gradually upsampling, refining and contextualizing object layouts. It is trained with a novel adversarial loss, that optimizes the interaction between object pairs. This improves coverage and removes overlaps, while maintaining sensible contours and respecting objects relations. We empirically show on the COCO-STUFF dataset that our proposed approach substantially improves the quality of generated layouts as well as the overall image quality. Our evaluation shows that we improve layout coverage by almost 20 points, and drop object overlap to negligible amounts. This leads to better image generation, relation fulfillment and objects quality.
Scale-Localized Abstract Reasoning
Sep 20, 2020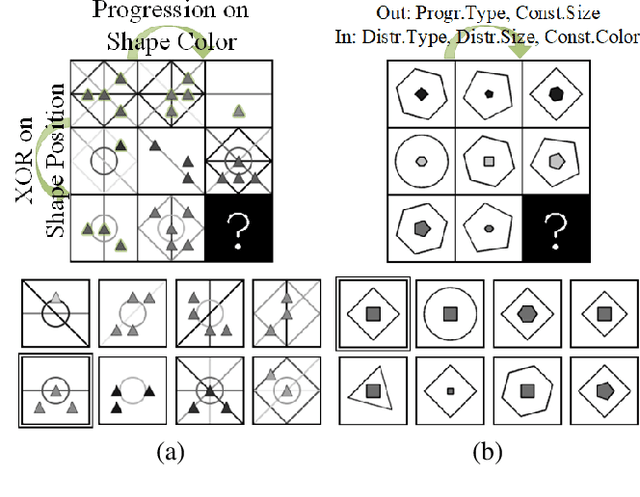
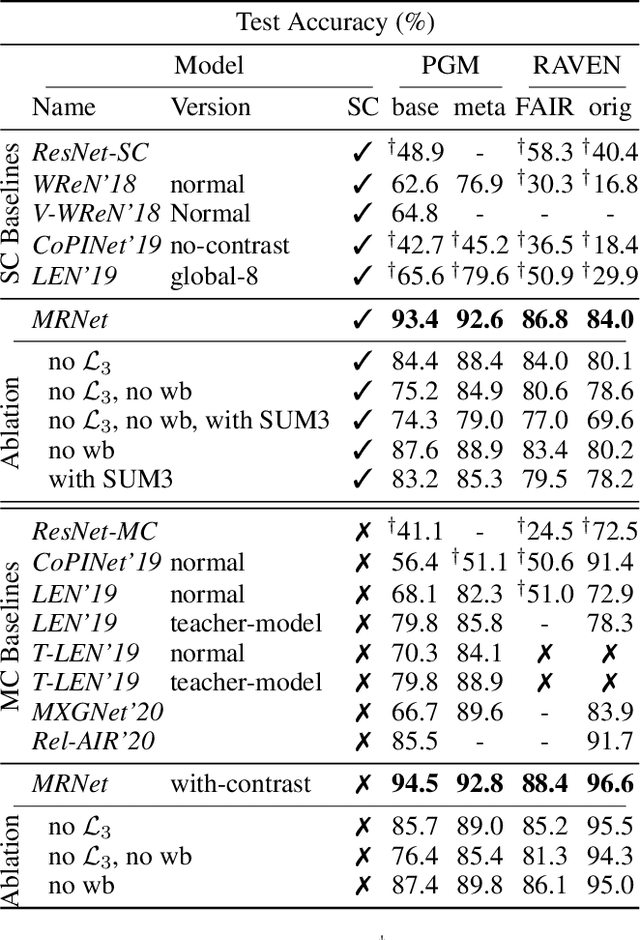
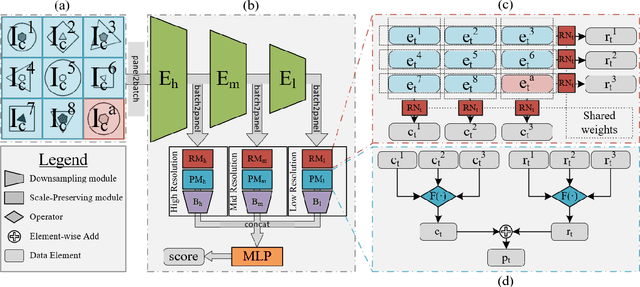
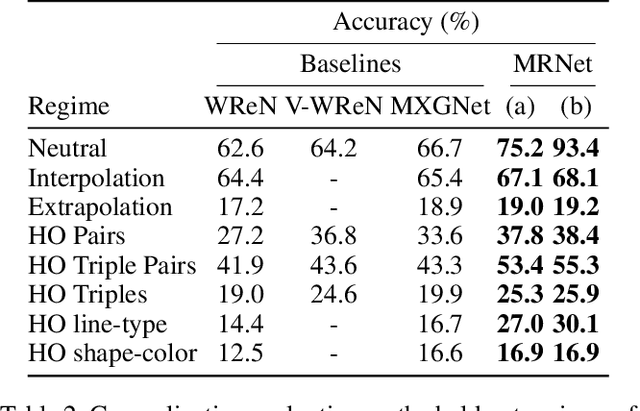
We consider the abstract relational reasoning task, which is commonly used as an intelligence test. Since some patterns have spatial rationales, while others are only semantic, we propose a multi-scale architecture that processes each query in multiple resolutions. We show that indeed different rules are solved by different resolutions and a combined multi-scale approach outperforms the existing state of the art in this task on all benchmarks by 5-54%. The success of our method is shown to arise from multiple novelties. First, it searches for relational patterns in multiple resolutions, which allows it to readily detect visual relations, such as location, in higher resolution, while allowing the lower resolution module to focus on semantic relations, such as shape type. Second, we optimize the reasoning network of each resolution proportionally to its performance, hereby we motivate each resolution to specialize on the rules for which it performs better than the others and ignore cases that are already solved by the other resolutions. Third, we propose a new way to pool information along the rows and the columns of the illustration-grid of the query. Our work also analyses the existing benchmarks, demonstrating that the RAVEN dataset selects the negative examples in a way that is easily exploited. We, therefore, propose a modified version of the RAVEN dataset, named RAVEN-FAIR. Our code and pretrained models are available at https://github.com/yanivbenny/MRNet. The dataset of RAVEN-FAIR is available at https://github.com/yanivbenny/RAVEN_FAIR.
Evaluation Metrics for Conditional Image Generation
Apr 26, 2020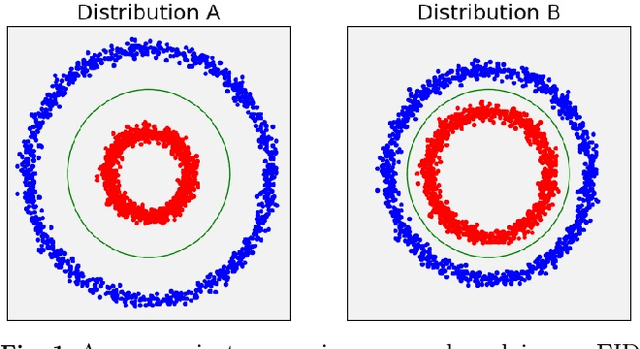
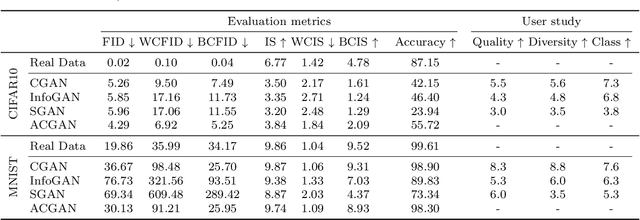
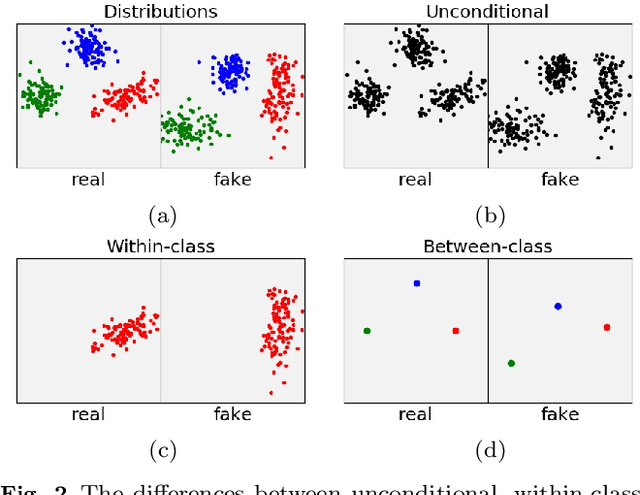
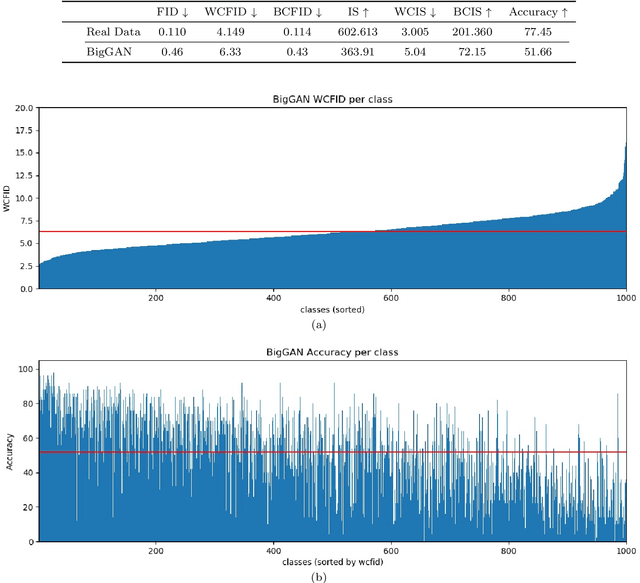
We present two new metrics for evaluating generative models in the class-conditional image generation setting. These metrics are obtained by generalizing the two most popular unconditional metrics: the Inception Score (IS) and the Fr\'{e}chet Inception Distance (FID). A theoretical analysis shows the motivation behind each proposed metric and links the novel metrics to their unconditional counterparts. The link takes the form of a product in the case of IS or an upper bound in the FID case. We provide an extensive empirical evaluation, comparing the metrics to their unconditional variants and to other metrics, and utilize them to analyze existing generative models, thus providing additional insights about their performance, from unlearned classes to mode collapse.
OneGAN: Simultaneous Unsupervised Learning of Conditional Image Generation, Foreground Segmentation, and Fine-Grained Clustering
Dec 31, 2019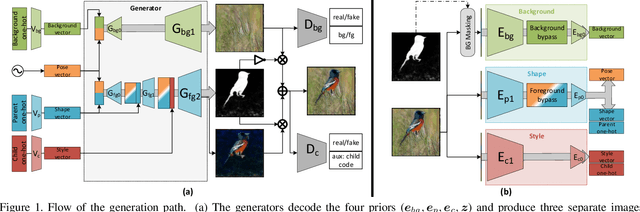
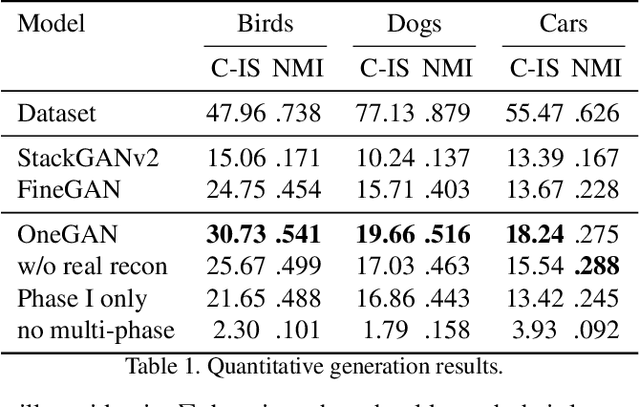
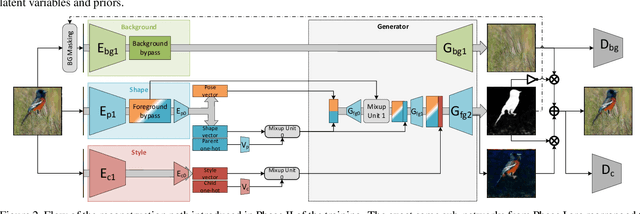
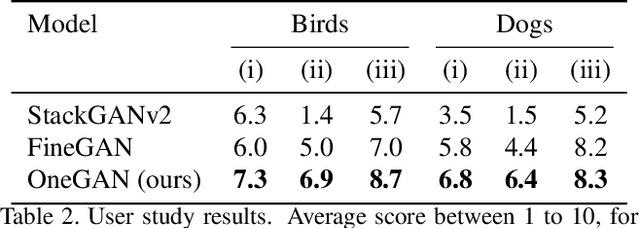
We present a method for simultaneously learning, in an unsupervised manner, (i) a conditional image generator, (ii) foreground extraction and segmentation, (iii) clustering into a two-level class hierarchy, and (iv) object removal and background completion, all done without any use of annotation. The method combines a generative adversarial network and a variational autoencoder, with multiple encoders, generators and discriminators, and benefits from solving all tasks at once. The input to the training scheme is a varied collection of unlabeled images from the same domain, as well as a set of background images without a foreground object. In addition, the image generator can mix the background from one image, with a foreground that is conditioned either on that of a second image or on the index of a desired cluster. The method obtains state of the art results in comparison to the literature methods, when compared to the current state of the art in each of the tasks.