 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph to Image Generation with Contextualized Object Layout Refinement
Sep 24, 2020

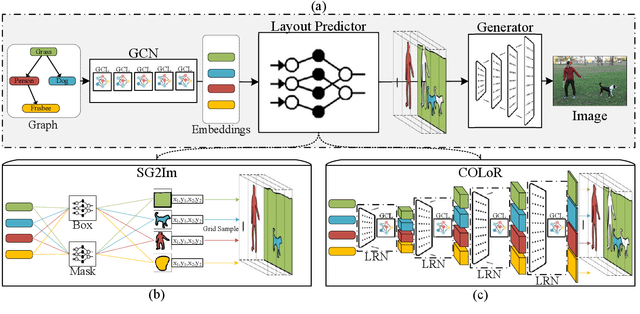
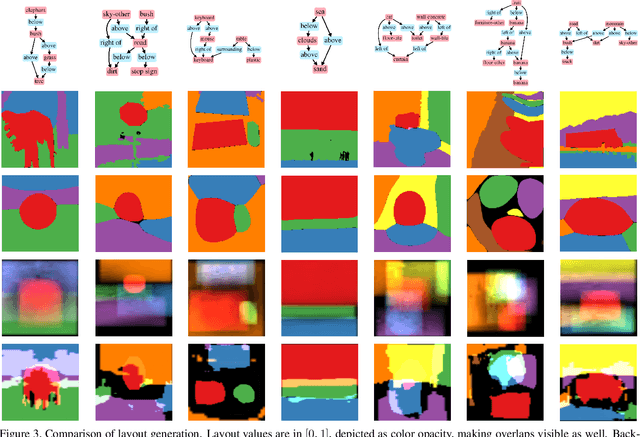
Generating high-quality images from scene graphs, that is, graphs that describe multiple entities in complex relations, is a challenging task that attracted substantial interest recently. Prior work trained such models by using supervised learning, where the goal is to produce the exact target image layout for each scene graph. It relied on predicting object locations and shapes independently and in parallel. However, scene graphs are underspecified, and thus the same scene graph often occurs with many target images in the training data. This leads to generated images with high inter-object overlap, empty areas, blurry objects, and overall compromised quality. In this work, we propose a method that alleviates these issues by generating all object layouts together and reducing the reliance on such supervision. Our model predicts layouts directly from embeddings (without predicting intermediate boxes) by gradually upsampling, refining and contextualizing object layouts. It is trained with a novel adversarial loss, that optimizes the interaction between object pairs. This improves coverage and removes overlaps, while maintaining sensible contours and respecting objects relations. We empirically show on the COCO-STUFF dataset that our proposed approach substantially improves the quality of generated layouts as well as the overall image quality. Our evaluation shows that we improve layout coverage by almost 20 points, and drop object overlap to negligible amounts. This leads to better image generation, relation fulfillment and objects quality.