 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Emotional Resonance Embedding: A Semi-Supervised Paradigm for Cross-Lingual Speech Emotion Recognition
Apr 08, 2026Cross-lingual Speech Emotion Recognition (CLSER) aims to identify emotional states in unseen languages. However, existing methods heavily rely on the semantic synchrony of complete labels and static feature stability, hindering low-resource languages from reaching high-resource performance. To address this, we propose a semi-supervised framework based on Semantic-Emotional Resonance Embedding (SERE), a cross-lingual dynamic feature paradigm that requires neither target language labels nor translation alignment. Specifically, SERE constructs an emotion-semantic structure using a small number of labeled samples. It learns human emotional experiences through an Instantaneous Resonance Field (IRF), enabling unlabeled samples to self-organize into this structure. This achieves semi-supervised semantic guidance and structural discovery. Additionally, we design a Triple-Resonance Interaction Chain (TRIC) loss to enable the model to reinforce the interaction and embedding capabilities between labeled and unlabeled samples during emotional highlights. Extensive experiments across multiple languages demonstrate the effectiveness of our method, requiring only 5-shot labeling in the source language.
Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
Nov 26, 2019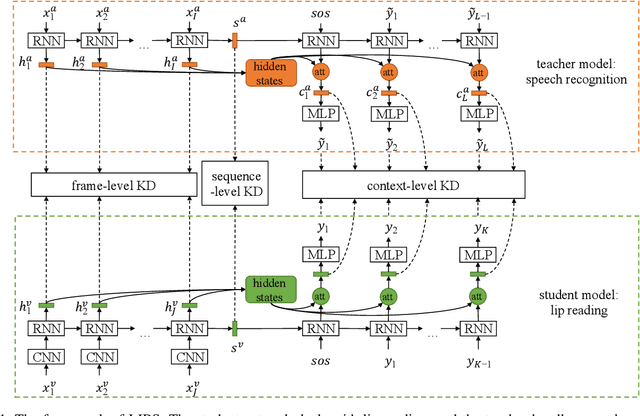

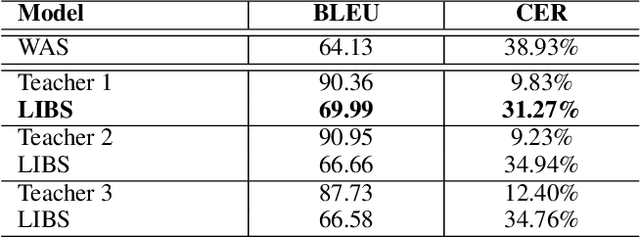

Lip reading has witnessed unparalleled development in recent years thanks to deep learning and the availability of large-scale datasets. Despite the encouraging results achieved, the performance of lip reading, unfortunately, remains inferior to the one of its counterpart speech recognition, due to the ambiguous nature of its actuations that makes it challenging to extract discriminant features from the lip movement videos. In this paper, we propose a new method, termed as Lip by Speech (LIBS), of which the goal is to strengthen lip reading by learning from speech recognizers. The rationale behind our approach is that the features extracted from speech recognizers may provide complementary and discriminant clues, which are formidable to be obtained from the subtle movements of the lips, and consequently facilitate the training of lip readers. This is achieved, specifically, by distilling multi-granularity knowledge from speech recognizers to lip readers. To conduct this cross-modal knowledge distillation, we utilize an efficacious alignment scheme to handle the inconsistent lengths of the audios and videos, as well as an innovative filtering strategy to refine the speech recognizer's prediction. The proposed method achieves the new state-of-the-art performance on the CMLR and LRS2 datasets, outperforming the baseline by a margin of 7.66% and 2.75% in character error rate, respectively.
A Cascade Sequence-to-Sequence Model for Chinese Mandarin Lip Reading
Aug 14, 2019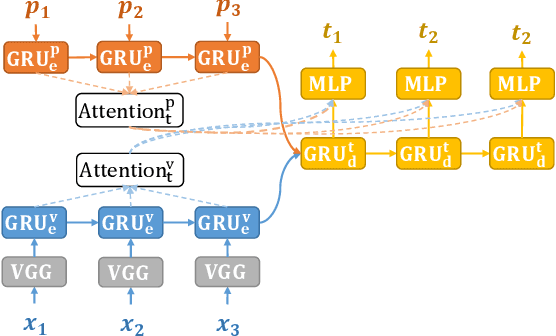
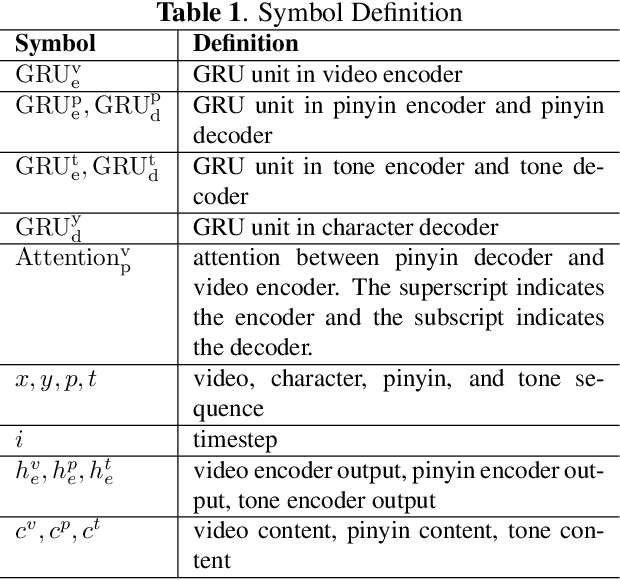
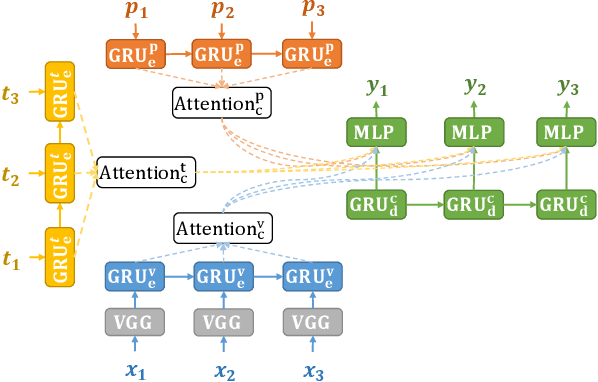
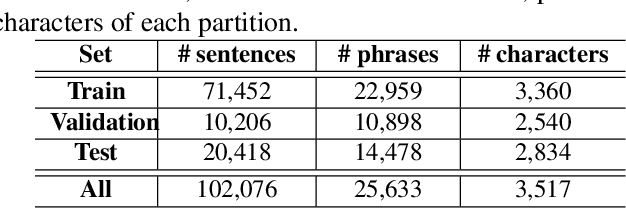
Lip reading aims at decoding texts from the movement of a speaker's mouth. In recent years, lip reading methods have made great progress for English, at both word-level and sentence-level. Unlike English, however, Chinese Mandarin is a tone-based language and relies on pitches to distinguish lexical or grammatical meaning, which significantly increases the ambiguity for the lip reading task. In this paper, we propose a Cascade Sequence-to-Sequence Model for Chinese Mandarin (CSSMCM) lip reading, which explicitly models tones when predicting sentence. Tones are modeled based on visual information and syntactic structure, and are used to predict sentence along with visual information and syntactic structure. In order to evaluate CSSMCM, a dataset called CMLR (Chinese Mandarin Lip Reading) is collected and released, consisting of over 100,000 natural sentences from China Network Television website. When trained on CMLR dataset, the proposed CSSMCM surpasses the performance of state-of-the-art lip reading frameworks, which confirms the effectiveness of explicit modeling of tones for Chinese Mandarin lip reading.