 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Convolutional Neural Network Architecture via Information Field
Sep 11, 2020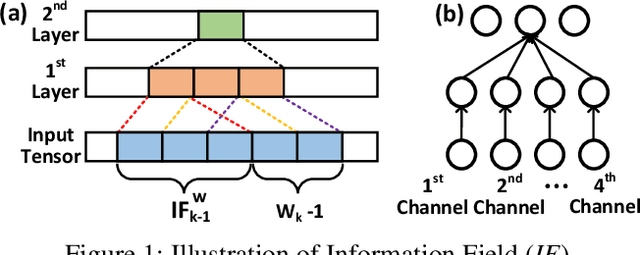



CNN architecture design has attracted tremendous attention of improving model accuracy or reducing model complexity. However, existing works either introduce repeated training overhead in the search process or lack an interpretable metric to guide the design. To clear the hurdles, we propose Information Field (IF), an explainable and easy-to-compute metric, to estimate the quality of a CNN architecture and guide the search process of designs. To validate the effectiveness of IF, we build a static optimizer to improve the CNN architectures at both the stage level and the kernel level. Our optimizer not only provides a clear and reproducible procedure but also mitigates unnecessary training efforts in the architecture search process. Experiments show that the models generated by our optimizer can achieve up to 5.47% accuracy improvement and up to 65.38% parameters deduction, compared with state-of-the-art CNN structures like MobileNet and ResNet.
SGQuant: Squeezing the Last Bit on Graph Neural Networks with Specialized Quantization
Jul 09, 2020

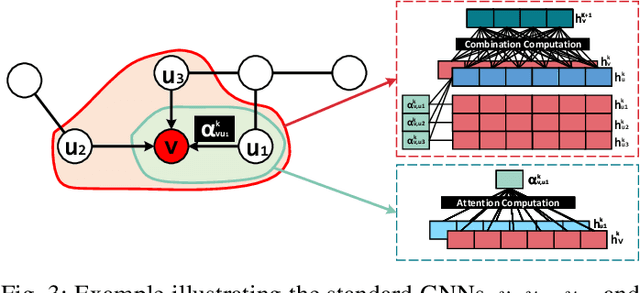

With the increasing popularity of graph-based learning, Graph Neural Networks (GNNs) win lots of attention from the research and industry field because of their high accuracy. However, existing GNNs suffer from high memory footprints (e.g., node embedding features). This high memory footprint hurdles the potential applications towards memory-constrained devices, such as the widely-deployed IoT devices. To this end, we propose a specialized GNN quantization scheme, SGQuant, to systematically reduce the GNN memory consumption. Specifically, we first propose a GNN-tailored quantization algorithm design and a GNN quantization fine-tuning scheme to reduce memory consumption while maintaining accuracy. Then, we investigate the multi-granularity quantization strategy that operates at different levels (components, graph topology, and layers) of GNN computation. Moreover, we offer an automatic bit-selecting (ABS) to pinpoint the most appropriate quantization bits for the above multi-granularity quantizations. Intensive experiments show that SGQuant can effectively reduce the memory footprint from 4.25x to 31.9x compared with the original full-precision GNNs while limiting the accuracy drop to 0.4% on average.