 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOWDR: Pathology-preserving Outpainting with Wavelet Diffusion for 3D MRI
Jan 14, 2026Medical imaging datasets often suffer from class imbalance and limited availability of pathology-rich cases, which constrains the performance of machine learning models for segmentation, classification, and vision-language tasks. To address this challenge, we propose POWDR, a pathology-preserving outpainting framework for 3D MRI based on a conditioned wavelet diffusion model. Unlike conventional augmentation or unconditional synthesis, POWDR retains real pathological regions while generating anatomically plausible surrounding tissue, enabling diversity without fabricating lesions. Our approach leverages wavelet-domain conditioning to enhance high-frequency detail and mitigate blurring common in latent diffusion models. We introduce a random connected mask training strategy to overcome conditioning-induced collapse and improve diversity outside the lesion. POWDR is evaluated on brain MRI using BraTS datasets and extended to knee MRI to demonstrate tissue-agnostic applicability. Quantitative metrics (FID, SSIM, LPIPS) confirm image realism, while diversity analysis shows significant improvement with random-mask training (cosine similarity reduced from 0.9947 to 0.9580; KL divergence increased from 0.00026 to 0.01494). Clinically relevant assessments reveal gains in tumor segmentation performance using nnU-Net, with Dice scores improving from 0.6992 to 0.7137 when adding 50 synthetic cases. Tissue volume analysis indicates no significant differences for CSF and GM compared to real images. These findings highlight POWDR as a practical solution for addressing data scarcity and class imbalance in medical imaging. The method is extensible to multiple anatomies and offers a controllable framework for generating diverse, pathology-preserving synthetic data to support robust model development.
Automated MRI Field of View Prescription from Region of Interest Prediction by Intra-stack Attention Neural Network
Nov 09, 2022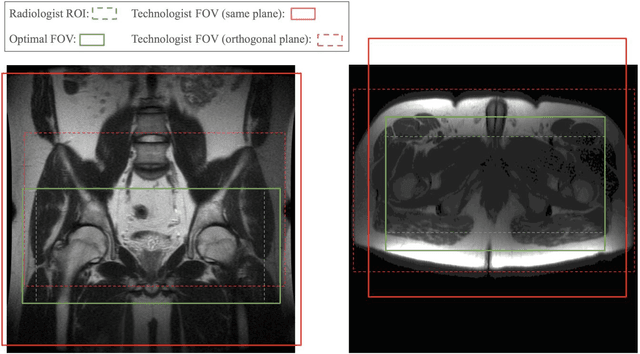
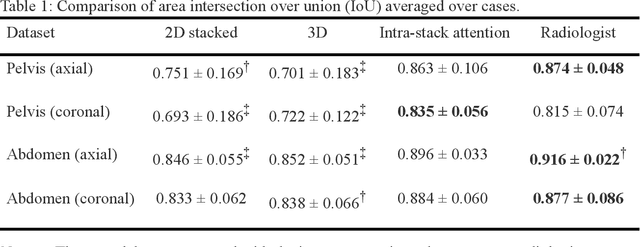
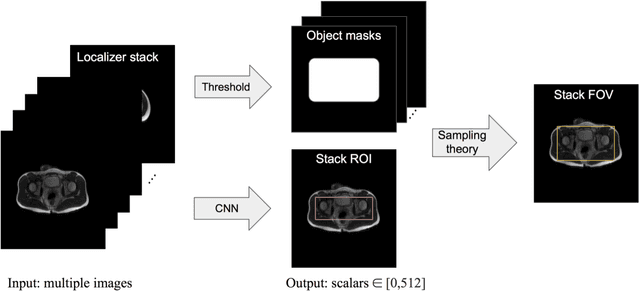
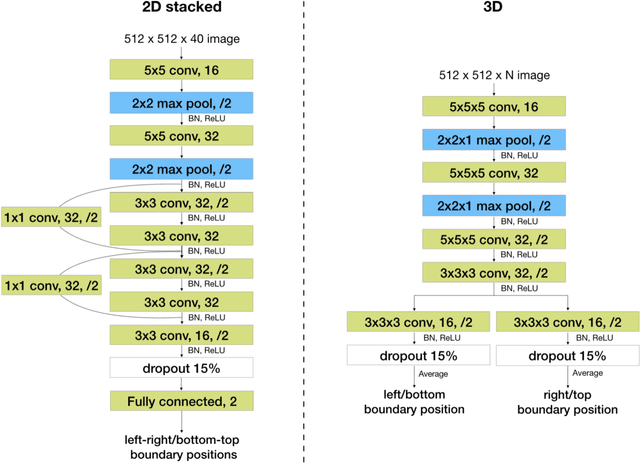
Manual prescription of the field of view (FOV) by MRI technologists is variable and prolongs the scanning process. Often, the FOV is too large or crops critical anatomy. We propose a deep-learning framework, trained by radiologists' supervision, for automating FOV prescription. An intra-stack shared feature extraction network and an attention network are used to process a stack of 2D image inputs to generate output scalars defining the location of a rectangular region of interest (ROI). The attention mechanism is used to make the model focus on the small number of informative slices in a stack. Then the smallest FOV that makes the neural network predicted ROI free of aliasing is calculated by an algebraic operation derived from MR sampling theory. We retrospectively collected 595 cases between February 2018 and February 2022. The framework's performance is examined quantitatively with intersection over union (IoU) and pixel error on position, and qualitatively with a reader study. We use the t-test for comparing quantitative results from all models and a radiologist. The proposed model achieves an average IoU of 0.867 and average ROI position error of 9.06 out of 512 pixels on 80 test cases, significantly better (P<0.05) than two baseline models and not significantly different from a radiologist (P>0.12). Finally, the FOV given by the proposed framework achieves an acceptance rate of 92% from an experienced radiologist.