 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning
May 20, 2018
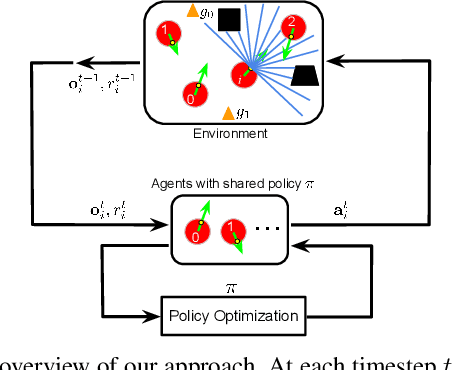
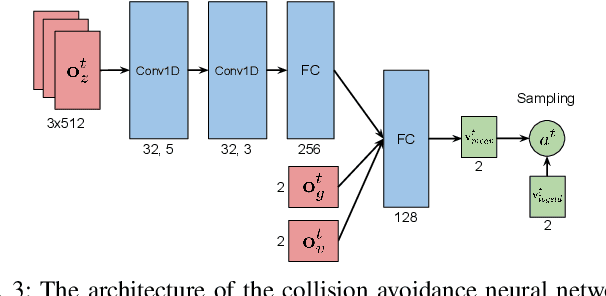
Developing a safe and efficient collision avoidance policy for multiple robots is challenging in the decentralized scenarios where each robot generate its paths without observing other robots' states and intents. While other distributed multi-robot collision avoidance systems exist, they often require extracting agent-level features to plan a local collision-free action, which can be computationally prohibitive and not robust. More importantly, in practice the performance of these methods are much lower than their centralized counterparts. We present a decentralized sensor-level collision avoidance policy for multi-robot systems, which directly maps raw sensor measurements to an agent's steering commands in terms of movement velocity. As a first step toward reducing the performance gap between decentralized and centralized methods, we present a multi-scenario multi-stage training framework to find an optimal policy which is trained over a large number of robots on rich, complex environments simultaneously using a policy gradient based reinforcement learning algorithm. We validate the learned sensor-level collision avoidance policy in a variety of simulated scenarios with thorough performance evaluations and show that the final learned policy is able to find time efficient, collision-free paths for a large-scale robot system. We also demonstrate that the learned policy can be well generalized to new scenarios that do not appear in the entire training period, including navigating a heterogeneous group of robots and a large-scale scenario with 100 robots. Videos are available at https://sites.google.com/view/drlmaca