 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint MIMO Transceiver and Reflector Design for Reconfigurable Intelligent Surface-Assisted Communication
May 27, 2024



In this paper, we consider a reconfigurable intelligent surface (RIS)-assisted multiple-input multiple-output communication system with multiple antennas at both the base station (BS) and the user. We plan to maximize the achievable rate through jointly optimizing the transmit precoding matrix, the receive combining matrix, and the RIS reflection matrix under the constraints of the transmit power at the BS and the unit-modulus reflection at the RIS. Regarding the non-trivial problem form, we initially reformulate it into an considerable problem to make it tractable by utilizing the relationship between the achievable rate and the weighted minimum mean squared error. Next, the transmit precoding matrix, the receive combining matrix, and the RIS reflection matrix are alternately optimized. In particular, the optimal transmit precoding matrix and receive combining matrix are obtained in closed forms. Furthermore, a pair of computationally efficient methods are proposed for the RIS reflection matrix, namely the semi-definite relaxation (SDR) method and the successive closed form (SCF) method. We theoretically prove that both methods are ensured to converge, and the SCF-based algorithm is able to converges to a Karush-Kuhn-Tucker point of the problem.
Distributed and Joint Optimization of Precoding and Power for User-Centric Cell-Free Massive MIMO
May 18, 2022
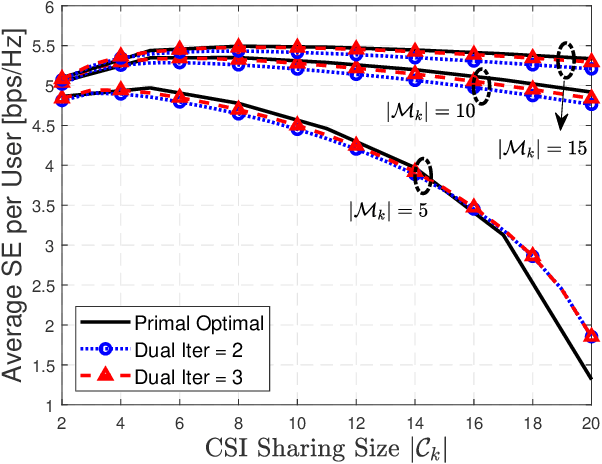
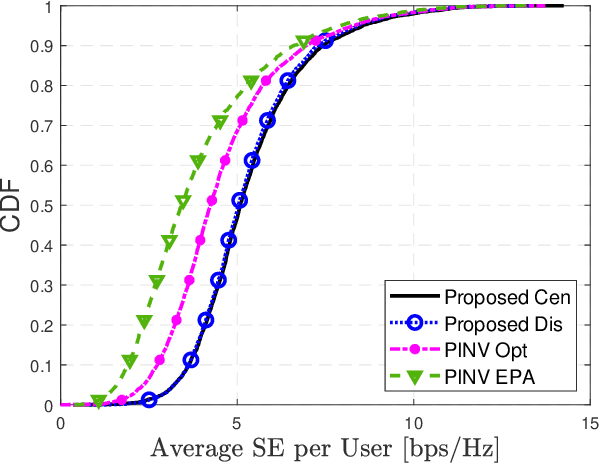
In the cell-free massive multiple-input multiple-output (CF mMIMO) system, the centralized transmission scheme is widely adopted to manage the inter-user interference. Unfortunately, its implementation is limited by the extensive signaling overhead between the central process unit (CPU) and the access points (APs). In this letter, we study the downlink transmission scheme in a distributed approach. First, we propose a reduced channel state information (CSI) exchange mechanism, where only the CSI of a portion of users is shared among neighboring APs. Base on this, the dual decomposition method is adopted to jointly optimize the precoder and power control. The precoding vector can be independently calculated by each AP cluster with closed-form expression. With very few iterations, the proposed distributed scheme achieves the same performance as the centralized one. Moreover, it significantly reduces the information exchange to the CPU.