 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA large language model for predicting T cell receptor-antigen binding specificity
Jun 24, 2024The human immune response depends on the binding of T-cell receptors (TCRs) to antigens (pTCR), which elicits the T cells to eliminate viruses, tumor cells, and other pathogens. The ability of human immunity system responding to unknown viruses and bacteria stems from the TCR diversity. However, this vast diversity poses challenges on the TCR-antigen binding prediction methods. In this study, we propose a Masked Language Model (MLM), referred to as tcrLM, to overcome limitations in model generalization. Specifically, we randomly masked sequence segments and train tcrLM to infer the masked segment, thereby extract expressive feature from TCR sequences. Meanwhile, we introduced virtual adversarial training techniques to enhance the model's robustness. We built the largest TCR CDR3 sequence dataset to date (comprising 2,277,773,840 residuals), and pre-trained tcrLM on this dataset. Our extensive experimental results demonstrate that tcrLM achieved AUC values of 0.937 and 0.933 on independent test sets and external validation sets, respectively, which remarkably outperformed four previously published prediction methods. On a large-scale COVID-19 pTCR binding test set, our method outperforms the current state-of-the-art method by at least 8%, highlighting the generalizability of our method. Furthermore, we validated that our approach effectively predicts immunotherapy response and clinical outcomes on a clinical cohorts. These findings clearly indicate that tcrLM exhibits significant potential in predicting antigenic immunogenicity.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Modeling Multivariate Cyber Risks: Deep Learning Dating Extreme Value Theory
Mar 15, 2021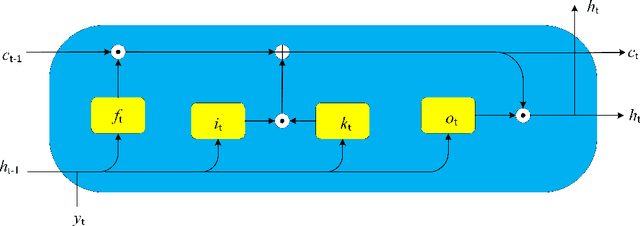

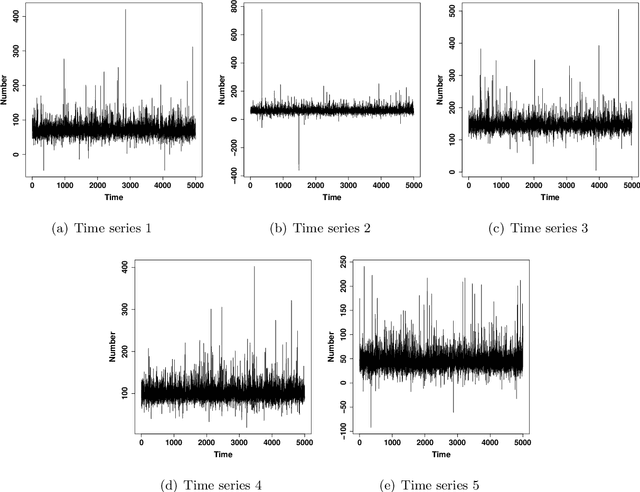

Modeling cyber risks has been an important but challenging task in the domain of cyber security. It is mainly because of the high dimensionality and heavy tails of risk patterns. Those obstacles have hindered the development of statistical modeling of the multivariate cyber risks. In this work, we propose a novel approach for modeling the multivariate cyber risks which relies on the deep learning and extreme value theory. The proposed model not only enjoys the high accurate point predictions via deep learning but also can provide the satisfactory high quantile prediction via extreme value theory. The simulation study shows that the proposed model can model the multivariate cyber risks very well and provide satisfactory prediction performances. The empirical evidence based on real honeypot attack data also shows that the proposed model has very satisfactory prediction performances.