 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE: SeMantic Ids Enhanced CoLd Item Representation for Click-through Rate Prediction in E-commerce SEarch
Oct 14, 2025



With the rise of modern search and recommendation platforms, insufficient collaborative information of cold-start items exacerbates the Matthew effect of existing platform items, challenging platform diversity and becoming a longstanding issue. Existing methods align items' side content with collaborative information to transfer collaborative signals from high-popularity items to cold-start items. However, these methods fail to account for the asymmetry between collaboration and content, nor the fine-grained differences among items. To address these issues, we propose SMILE, an item representation enhancement approach based on fused alignment of semantic IDs. Specifically, we use RQ-OPQ encoding to quantize item content and collaborative information, followed by a two-step alignment: RQ encoding transfers shared collaborative signals across items, while OPQ encoding learns differentiated information of items. Comprehensive offline experiments on large-scale industrial datasets demonstrate superiority of SMILE, and rigorous online A/B tests confirm statistically significant improvements: item CTR +1.66%, buyers +1.57%, and order volume +2.17%.
DiffusionGS: Generative Search with Query Conditioned Diffusion in Kuaishou
Aug 25, 2025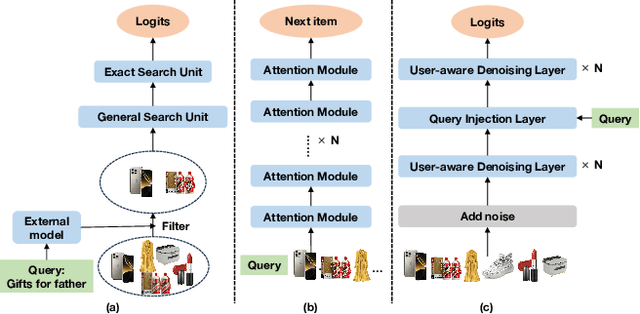
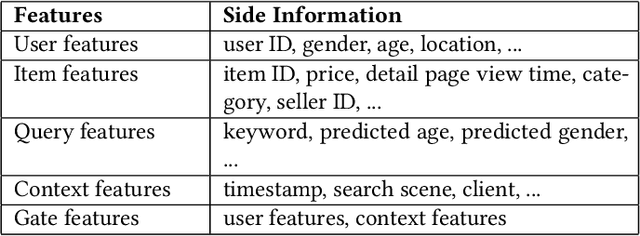
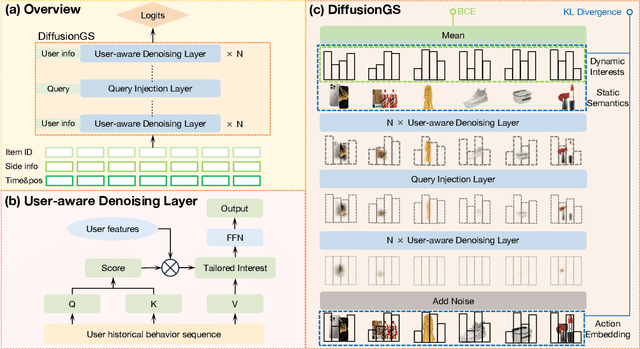
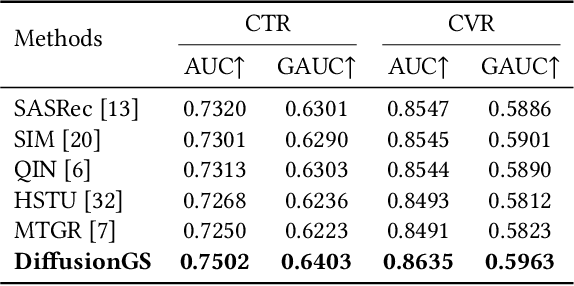
Personalized search ranking systems are critical for driving engagement and revenue in modern e-commerce and short-video platforms. While existing methods excel at estimating users' broad interests based on the filtered historical behaviors, they typically under-exploit explicit alignment between a user's real-time intent (represented by the user query) and their past actions. In this paper, we propose DiffusionGS, a novel and scalable approach powered by generative models. Our key insight is that user queries can serve as explicit intent anchors to facilitate the extraction of users' immediate interests from long-term, noisy historical behaviors. Specifically, we formulate interest extraction as a conditional denoising task, where the user's query guides a conditional diffusion process to produce a robust, user intent-aware representation from their behavioral sequence. We propose the User-aware Denoising Layer (UDL) to incorporate user-specific profiles into the optimization of attention distribution on the user's past actions. By reframing queries as intent priors and leveraging diffusion-based denoising, our method provides a powerful mechanism for capturing dynamic user interest shifts. Extensive offline and online experiments demonstrate the superiority of DiffusionGS over state-of-the-art methods.
Delving into E-Commerce Product Retrieval with Vision-Language Pre-training
Apr 17, 2023



E-commerce search engines comprise a retrieval phase and a ranking phase, where the first one returns a candidate product set given user queries. Recently, vision-language pre-training, combining textual information with visual clues, has been popular in the application of retrieval tasks. In this paper, we propose a novel V+L pre-training method to solve the retrieval problem in Taobao Search. We design a visual pre-training task based on contrastive learning, outperforming common regression-based visual pre-training tasks. In addition, we adopt two negative sampling schemes, tailored for the large-scale retrieval task. Besides, we introduce the details of the online deployment of our proposed method in real-world situations. Extensive offline/online experiments demonstrate the superior performance of our method on the retrieval task. Our proposed method is employed as one retrieval channel of Taobao Search and serves hundreds of millions of users in real time.
MAKE: Product Retrieval with Vision-Language Pre-training in Taobao Search
Jan 30, 2023



Taobao Search consists of two phases: the retrieval phase and the ranking phase. Given a user query, the retrieval phase returns a subset of candidate products for the following ranking phase. Recently, the paradigm of pre-training and fine-tuning has shown its potential in incorporating visual clues into retrieval tasks. In this paper, we focus on solving the problem of text-to-multimodal retrieval in Taobao Search. We consider that users' attention on titles or images varies on products. Hence, we propose a novel Modal Adaptation module for cross-modal fusion, which helps assigns appropriate weights on texts and images across products. Furthermore, in e-commerce search, user queries tend to be brief and thus lead to significant semantic imbalance between user queries and product titles. Therefore, we design a separate text encoder and a Keyword Enhancement mechanism to enrich the query representations and improve text-to-multimodal matching. To this end, we present a novel vision-language (V+L) pre-training methods to exploit the multimodal information of (user query, product title, product image). Extensive experiments demonstrate that our retrieval-specific pre-training model (referred to as MAKE) outperforms existing V+L pre-training methods on the text-to-multimodal retrieval task. MAKE has been deployed online and brings major improvements on the retrieval system of Taobao Search.
Weakly-Supervised Saliency Detection via Salient Object Subitizing
Jan 04, 2021
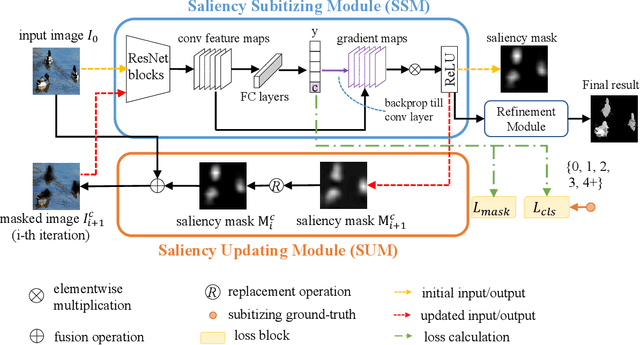

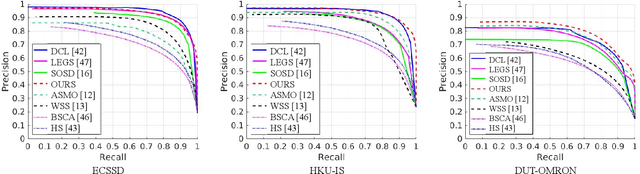
Salient object detection aims at detecting the most visually distinct objects and producing the corresponding masks. As the cost of pixel-level annotations is high, image tags are usually used as weak supervisions. However, an image tag can only be used to annotate one class of objects. In this paper, we introduce saliency subitizing as the weak supervision since it is class-agnostic. This allows the supervision to be aligned with the property of saliency detection, where the salient objects of an image could be from more than one class. To this end, we propose a model with two modules, Saliency Subitizing Module (SSM) and Saliency Updating Module (SUM). While SSM learns to generate the initial saliency masks using the subitizing information, without the need for any unsupervised methods or some random seeds, SUM helps iteratively refine the generated saliency masks. We conduct extensive experiments on five benchmark datasets. The experimental results show that our method outperforms other weakly-supervised methods and even performs comparably to some fully-supervised methods.