 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttriHuman-3D: Editable 3D Human Avatar Generation with Attribute Decomposition and Indexing
Dec 06, 2023

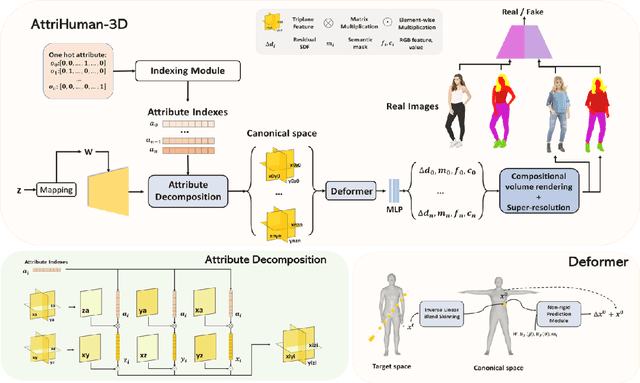

Editable 3D-aware generation, which supports user-interacted editing, has witnessed rapid development recently. However, existing editable 3D GANs either fail to achieve high-accuracy local editing or suffer from huge computational costs. We propose AttriHuman-3D, an editable 3D human generation model, which address the aforementioned problems with attribute decomposition and indexing. The core idea of the proposed model is to generate all attributes (e.g. human body, hair, clothes and so on) in an overall attribute space with six feature planes, which are then decomposed and manipulated with different attribute indexes. To precisely extract features of different attributes from the generated feature planes, we propose a novel attribute indexing method as well as an orthogonal projection regularization to enhance the disentanglement. We also introduce a hyper-latent training strategy and an attribute-specific sampling strategy to avoid style entanglement and misleading punishment from the discriminator. Our method allows users to interactively edit selected attributes in the generated 3D human avatars while keeping others fixed. Both qualitative and quantitative experiments demonstrate that our model provides a strong disentanglement between different attributes, allows fine-grained image editing and generates high-quality 3D human avatars.
Few-shot Image Generation via Style Adaptation and Content Preservation
Nov 30, 2023Training a generative model with limited data (e.g., 10) is a very challenging task. Many works propose to fine-tune a pre-trained GAN model. However, this can easily result in overfitting. In other words, they manage to adapt the style but fail to preserve the content, where \textit{style} denotes the specific properties that defines a domain while \textit{content} denotes the domain-irrelevant information that represents diversity. Recent works try to maintain a pre-defined correspondence to preserve the content, however, the diversity is still not enough and it may affect style adaptation. In this work, we propose a paired image reconstruction approach for content preservation. We propose to introduce an image translation module to GAN transferring, where the module teaches the generator to separate style and content, and the generator provides training data to the translation module in return. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.