 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalse: False Negative Samples Aware Contrastive Learning for Semantic Segmentation of High-Resolution Remote Sensing Image
Nov 15, 2022



The existing SSCL of RSI is built based on constructing positive and negative sample pairs. However, due to the richness of RSI ground objects and the complexity of the RSI contextual semantics, the same RSI patches have the coexistence and imbalance of positive and negative samples, which causing the SSCL pushing negative samples far away while pushing positive samples far away, and vice versa. We call this the sample confounding issue (SCI). To solve this problem, we propose a False negAtive sampLes aware contraStive lEarning model (FALSE) for the semantic segmentation of high-resolution RSIs. Since the SSCL pretraining is unsupervised, the lack of definable criteria for false negative sample (FNS) leads to theoretical undecidability, we designed two steps to implement the FNS approximation determination: coarse determination of FNS and precise calibration of FNS. We achieve coarse determination of FNS by the FNS self-determination (FNSD) strategy and achieve calibration of FNS by the FNS confidence calibration (FNCC) loss function. Experimental results on three RSI semantic segmentation datasets demonstrated that the FALSE effectively improves the accuracy of the downstream RSI semantic segmentation task compared with the current three models, which represent three different types of SSCL models. The mean Intersection-over-Union on ISPRS Potsdam dataset is improved by 0.7\% on average; on CVPR DGLC dataset is improved by 12.28\% on average; and on Xiangtan dataset this is improved by 1.17\% on average. This indicates that the SSCL model has the ability to self-differentiate FNS and that the FALSE effectively mitigates the SCI in self-supervised contrastive learning. The source code is available at https://github.com/GeoX-Lab/FALSE.
SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images
Dec 19, 2019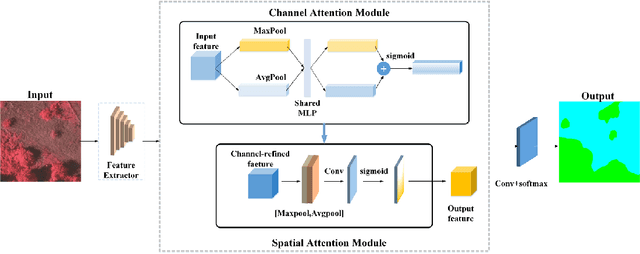

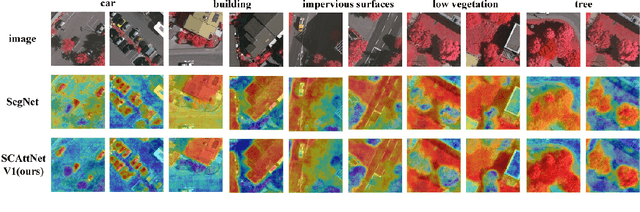
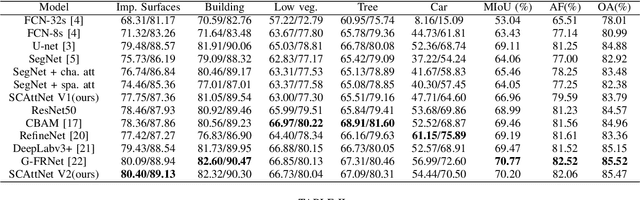
High-resolution remote sensing images (HRRSIs) contain substantial ground object information, such as texture, shape, and spatial location. Semantic segmentation, which is an important method for element extraction, has been widely used in processing mass HRRSIs. However, HRRSIs often exhibit large intraclass variance and small interclass variance due to the diversity and complexity of ground objects, thereby bringing great challenges to a semantic segmentation task. In this study, we propose a new end-to-end semantic segmentation network, which integrates two lightweight attention mechanisms that can refine features adaptively. We compare our method with several previous advanced networks on the ISPRS Vaihingen and Potsdam datasets. Experimental results show that our method can achieve better semantic segmentation results compared with other works. The source codes are available at https://github.com/lehaifeng/SCAttNet.
MAP-Net: Multi Attending Path Neural Network for Building Footprint Extraction from Remote Sensed Imagery
Oct 26, 2019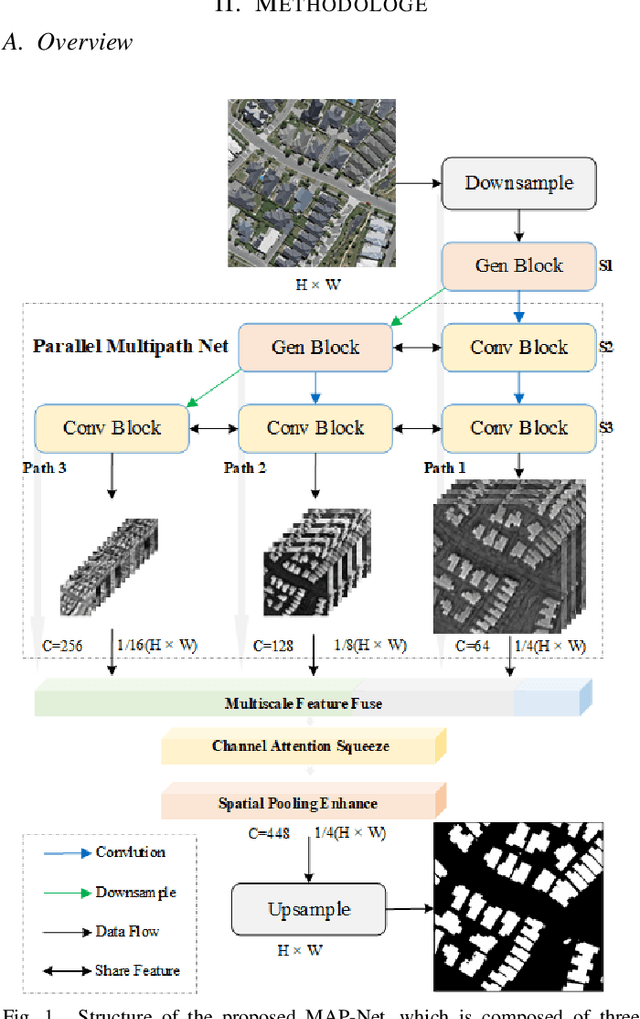

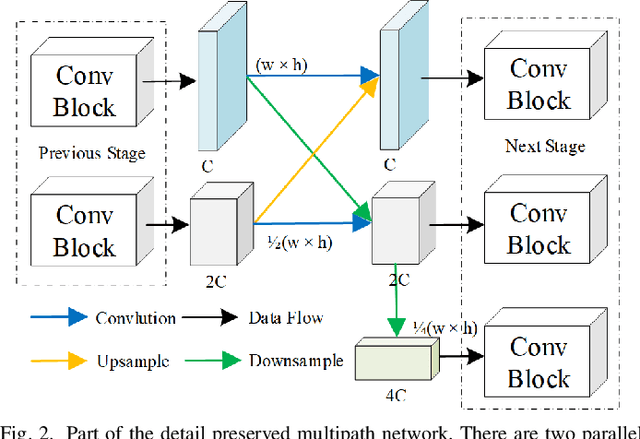
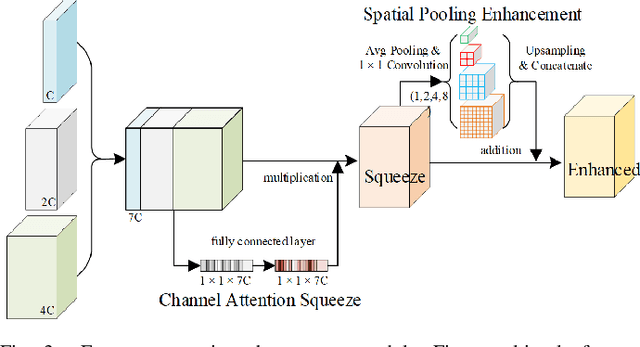
Accurately and efficiently extracting building footprints from a wide range of remote sensed imagery remains a challenge due to their complex structure, variety of scales and diverse appearances. Existing convolutional neural network (CNN)-based building extraction methods are complained that they cannot detect the tiny buildings because the spatial information of CNN feature maps are lost during repeated pooling operations of the CNN, and the large buildings still have inaccurate segmentation edges. Moreover, features extracted by a CNN are always partial which restricted by the size of the respective field, and large-scale buildings with low texture are always discontinuous and holey when extracted. This paper proposes a novel multi attending path neural network (MAP-Net) for accurately extracting multiscale building footprints and precise boundaries. MAP-Net learns spatial localization-preserved multiscale features through a multi-parallel path in which each stage is gradually generated to extract high-level semantic features with fixed resolution. Then, an attention module adaptively squeezes channel-wise features from each path for optimization, and a pyramid spatial pooling module captures global dependency for refining discontinuous building footprints. Experimental results show that MAP-Net outperforms state-of-the-art (SOTA) algorithms in boundary localization accuracy as well as continuity of large buildings. Specifically, our method achieved 0.68\%, 1.74\%, 1.46\% precision, and 1.50\%, 1.53\%, 0.82\% IoU score improvement without increasing computational complexity compared with the latest HRNetv2 on the Urban 3D, Deep Globe and WHU datasets, respectively. The TensorFlow implementation is available at https://github.com/lehaifeng/MAPNet.