 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTightening Discretization-based MILP Models for the Pooling Problem using Upper Bounds on Bilinear Terms
Jul 08, 2022
Discretization-based methods have been proposed for solving nonconvex optimization problems with bilinear terms. These methods convert the original nonconvex optimization problems into mixed-integer linear programs (MILPs). Compared to a wide range of studies related to methods to convert nonconvex optimization problems into MILPs, research on tightening the resulting MILP models is limited. In this paper, we present tightening constraints for the discretization-based MILP models for the pooling problem. Specifically, we study tightening constraints derived from upper bounds on bilinear term and exploiting the structures resulting from the discretization. We demonstrate the effectiveness of our constraints, showing computational results for MILP models derived from different formulations for (1) the pooling problem and (2) discretization-based pooling models. Computational results show that our methods reduce the computational time for MILP models on CPLEX 12.10. Finally, we note that while our methods are presented in the context of the pooling problem, they can be extended to address other nonconvex optimization problems with upper bounds on bilinear terms.
On the identifiability of mixtures of ranking models
Jan 31, 2022
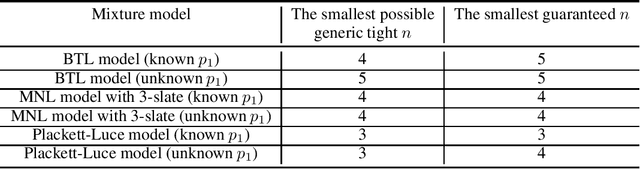
Mixtures of ranking models are standard tools for ranking problems. However, even the fundamental question of parameter identifiability is not fully understood: the identifiability of a mixture model with two Bradley-Terry-Luce (BTL) components has remained open. In this work, we show that popular mixtures of ranking models with two components (Plackett-Luce, multinomial logistic model with slates of size 3, or BTL) are generically identifiable, i.e., the ground-truth parameters can be identified except when they are from a pathological subset of measure zero. We provide a framework for verifying the number of solutions in a general family of polynomial systems using algebraic geometry, and apply it to these mixtures of ranking models. The framework can be applied more broadly to other learning models and may be of independent interest.
PBoS: Probabilistic Bag-of-Subwords for Generalizing Word Embedding
Oct 21, 2020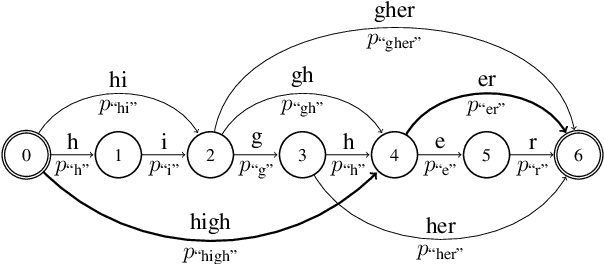


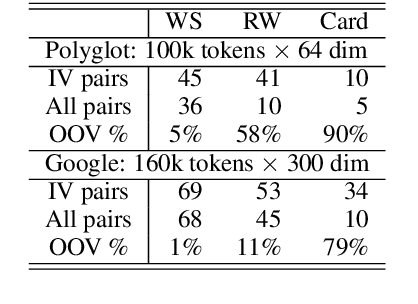
We look into the task of \emph{generalizing} word embeddings: given a set of pre-trained word vectors over a finite vocabulary, the goal is to predict embedding vectors for out-of-vocabulary words, \emph{without} extra contextual information. We rely solely on the spellings of words and propose a model, along with an efficient algorithm, that simultaneously models subword segmentation and computes subword-based compositional word embedding. We call the model probabilistic bag-of-subwords (PBoS), as it applies bag-of-subwords for all possible segmentations based on their likelihood. Inspections and affix prediction experiment show that PBoS is able to produce meaningful subword segmentations and subword rankings without any source of explicit morphological knowledge. Word similarity and POS tagging experiments show clear advantages of PBoS over previous subword-level models in the quality of generated word embeddings across languages.
Theory of Machine Learning Debugging via M-estimation
Jun 16, 2020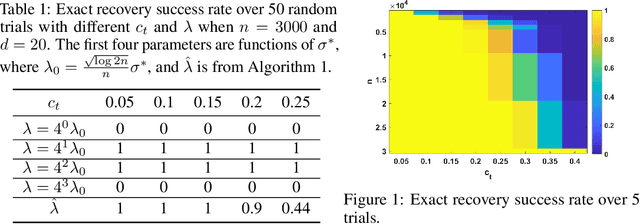
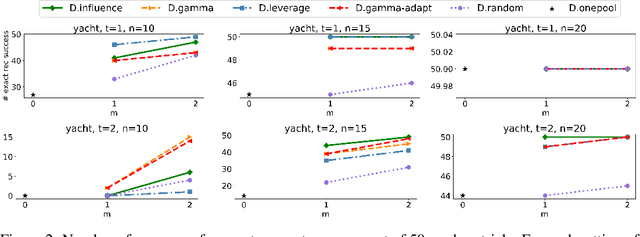

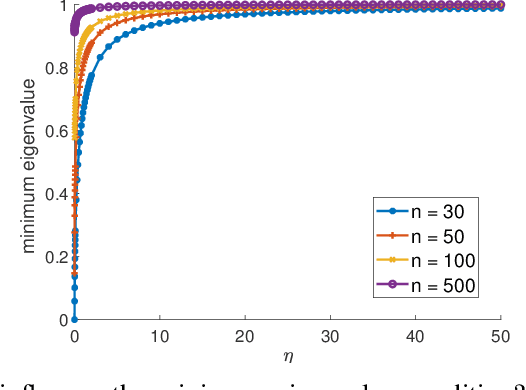
We investigate problems in penalized $M$-estimation, inspired by applications in machine learning debugging. Data are collected from two pools, one containing data with possibly contaminated labels, and the other which is known to contain only cleanly labeled points. We first formulate a general statistical algorithm for identifying buggy points and provide rigorous theoretical guarantees under the assumption that the data follow a linear model. We then present two case studies to illustrate the results of our general theory and the dependence of our estimator on clean versus buggy points. We further propose an algorithm for tuning parameter selection of our Lasso-based algorithm and provide corresponding theoretical guarantees. Finally, we consider a two-person "game" played between a bug generator and a debugger, where the debugger can augment the contaminated data set with cleanly labeled versions of points in the original data pool. We establish a theoretical result showing a sufficient condition under which the bug generator can always fool the debugger. Nonetheless, we provide empirical results showing that such a situation may not occur in practice, making it possible for natural augmentation strategies combined with our Lasso debugging algorithm to succeed.