 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBoS: Probabilistic Bag-of-Subwords for Generalizing Word Embedding
Oct 21, 2020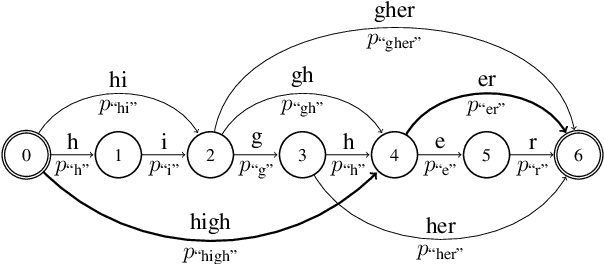


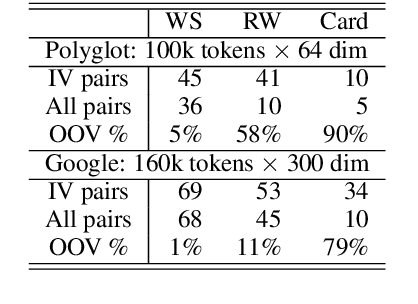
We look into the task of \emph{generalizing} word embeddings: given a set of pre-trained word vectors over a finite vocabulary, the goal is to predict embedding vectors for out-of-vocabulary words, \emph{without} extra contextual information. We rely solely on the spellings of words and propose a model, along with an efficient algorithm, that simultaneously models subword segmentation and computes subword-based compositional word embedding. We call the model probabilistic bag-of-subwords (PBoS), as it applies bag-of-subwords for all possible segmentations based on their likelihood. Inspections and affix prediction experiment show that PBoS is able to produce meaningful subword segmentations and subword rankings without any source of explicit morphological knowledge. Word similarity and POS tagging experiments show clear advantages of PBoS over previous subword-level models in the quality of generated word embeddings across languages.