 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Intelligent Imaging and Uncertainty Quantification by Deterministic Diffusion Model
Aug 23, 2024


Computational imaging is crucial in many disciplines from autonomous driving to life sciences. However, traditional model-driven and iterative methods consume large computational power and lack scalability for imaging. Deep learning (DL) is effective in processing local-to-local patterns, but it struggles with handling universal global-to-local (nonlocal) patterns under current frameworks. To bridge this gap, we propose a novel DL framework that employs a progressive denoising strategy, named the deterministic diffusion model (DDM), to facilitate general computational imaging at a low cost. We experimentally demonstrate the efficient and faithful image reconstruction capabilities of DDM from nonlocal patterns, such as speckles from multimode fiber and intensity patterns of second harmonic generation, surpassing the capability of previous state-of-the-art DL algorithms. By embedding Bayesian inference into DDM, we establish a theoretical framework and provide experimental proof of its uncertainty quantification. This advancement ensures the predictive reliability of DDM, avoiding misjudgment in high-stakes scenarios. This versatile and integrable DDM framework can readily extend and improve the efficacy of existing DL-based imaging applications.
RAKA:Co-training of Relationships and Attributes for Cross-lingual Knowledge Alignment
Oct 29, 2019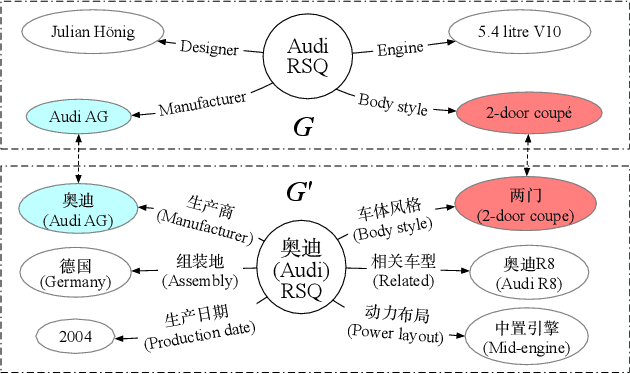
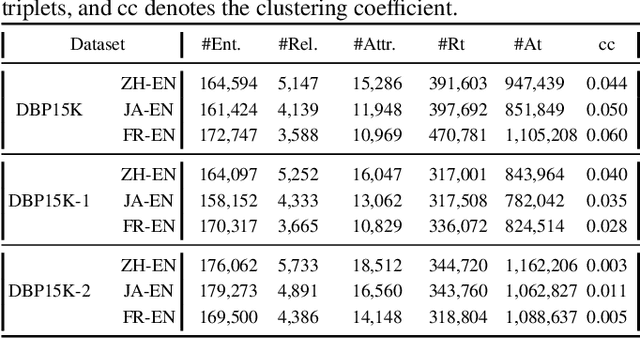
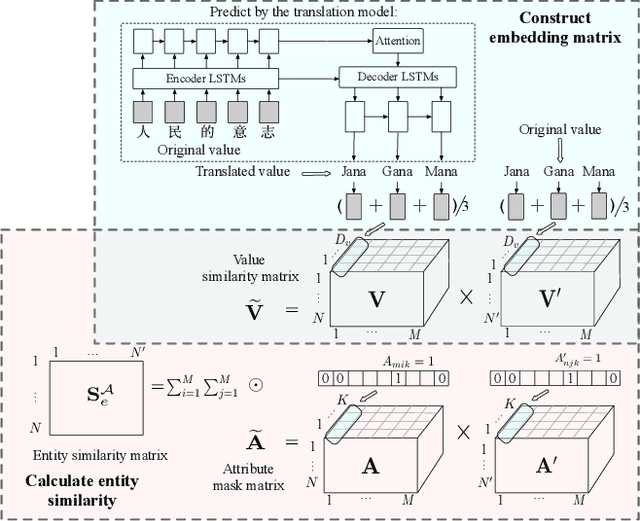
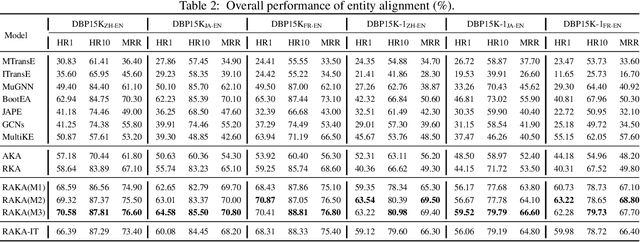
Cross-lingual knowledge alignment suffers from the attribute heterogeneity when leveraging the attributes and also suffers from the conflicts when combing the results inferred from attributes and relationships. This paper proposes an interaction based attribute model to capture the attribute-level interactions for estimating entity similarities, eliminating the negative impact of the dissimilar attributes. A matrix-based strategy is adopted in the model to accelerate the similarity estimation. We further propose a co-training framework together with three merge strategies to combine the alignments inferred by the attribute model and the relationship model. The whole framework can effectively and efficiently infer the aligned entities, relationships, attributes, and values simultaneously. Experimental results on several cross-lingual knowledge datasets show that our model significantly outperforms the state-of-the-art comparison methods (improving 2.35-51.57% in terms of Hit Ratio@1).