 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRAL: Motion-aware Multi-Frame 4D Radar and LiDAR Fusion for Robust 3D Object Detection
May 14, 2025Reliable autonomous driving systems require accurate detection of traffic participants. To this end, multi-modal fusion has emerged as an effective strategy. In particular, 4D radar and LiDAR fusion methods based on multi-frame radar point clouds have demonstrated the effectiveness in bridging the point density gap. However, they often neglect radar point clouds' inter-frame misalignment caused by object movement during accumulation and do not fully exploit the object dynamic information from 4D radar. In this paper, we propose MoRAL, a motion-aware multi-frame 4D radar and LiDAR fusion framework for robust 3D object detection. First, a Motion-aware Radar Encoder (MRE) is designed to compensate for inter-frame radar misalignment from moving objects. Later, a Motion Attention Gated Fusion (MAGF) module integrate radar motion features to guide LiDAR features to focus on dynamic foreground objects. Extensive evaluations on the View-of-Delft (VoD) dataset demonstrate that MoRAL outperforms existing methods, achieving the highest mAP of 73.30% in the entire area and 88.68% in the driving corridor. Notably, our method also achieves the best AP of 69.67% for pedestrians in the entire area and 96.25% for cyclists in the driving corridor.
4D mmWave Radar in Adverse Environments for Autonomous Driving: A Survey
Mar 31, 2025Autonomous driving systems require accurate and reliable perception. However, adverse environments, such as rain, snow, and fog, can significantly degrade the performance of LiDAR and cameras. In contrast, 4D millimeter-wave (mmWave) radar not only provides 3D sensing and additional velocity measurements but also maintains robustness in challenging conditions, making it increasingly valuable for autonomous driving. Recently, research on 4D mmWave radar under adverse environments has been growing, but a comprehensive survey is still lacking. To bridge this gap, this survey comprehensively reviews the current research on 4D mmWave radar under adverse environments. First, we present an overview of existing 4D mmWave radar datasets encompassing diverse weather and lighting scenarios. Next, we analyze methods and models according to different adverse conditions. Finally, the challenges faced in current studies and potential future directions are discussed for advancing 4D mmWave radar applications in harsh environments. To the best of our knowledge, this is the first survey specifically focusing on 4D mmWave radar in adverse environments for autonomous driving.
MutualForce: Mutual-Aware Enhancement for 4D Radar-LiDAR 3D Object Detection
Jan 17, 2025Radar and LiDAR have been widely used in autonomous driving as LiDAR provides rich structure information, and radar demonstrates high robustness under adverse weather. Recent studies highlight the effectiveness of fusing radar and LiDAR point clouds. However, challenges remain due to the modality misalignment and information loss during feature extractions. To address these issues, we propose a 4D radar-LiDAR framework to mutually enhance their representations. Initially, the indicative features from radar are utilized to guide both radar and LiDAR geometric feature learning. Subsequently, to mitigate their sparsity gap, the shape information from LiDAR is used to enrich radar BEV features. Extensive experiments on the View-of-Delft (VoD) dataset demonstrate our approach's superiority over existing methods, achieving the highest mAP of 71.76% across the entire area and 86.36\% within the driving corridor. Especially for cars, we improve the AP by 4.17% and 4.20% due to the strong indicative features and symmetric shapes.
LiRCDepth: Lightweight Radar-Camera Depth Estimation via Knowledge Distillation and Uncertainty Guidance
Dec 20, 2024Recently, radar-camera fusion algorithms have gained significant attention as radar sensors provide geometric information that complements the limitations of cameras. However, most existing radar-camera depth estimation algorithms focus solely on improving performance, often neglecting computational efficiency. To address this gap, we propose LiRCDepth, a lightweight radar-camera depth estimation model. We incorporate knowledge distillation to enhance the training process, transferring critical information from a complex teacher model to our lightweight student model in three key domains. Firstly, low-level and high-level features are transferred by incorporating pixel-wise and pair-wise distillation. Additionally, we introduce an uncertainty-aware inter-depth distillation loss to refine intermediate depth maps during decoding. Leveraging our proposed knowledge distillation scheme, the lightweight model achieves a 6.6% improvement in MAE on the nuScenes dataset compared to the model trained without distillation.
MUFASA: Multi-View Fusion and Adaptation Network with Spatial Awareness for Radar Object Detection
Aug 01, 2024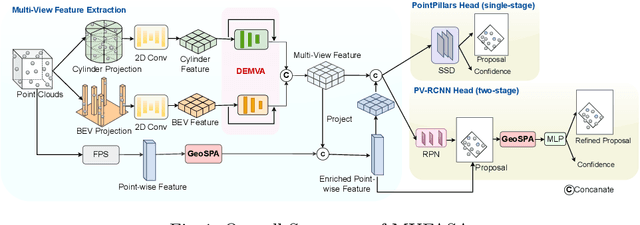
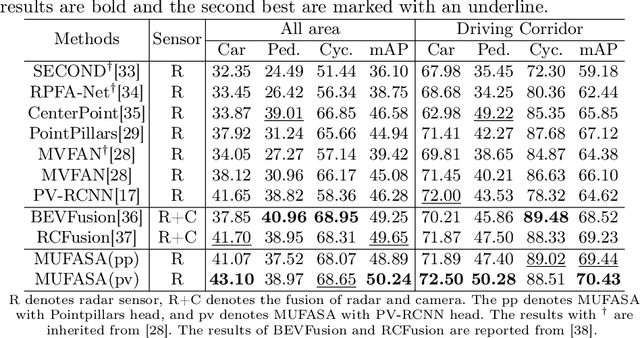
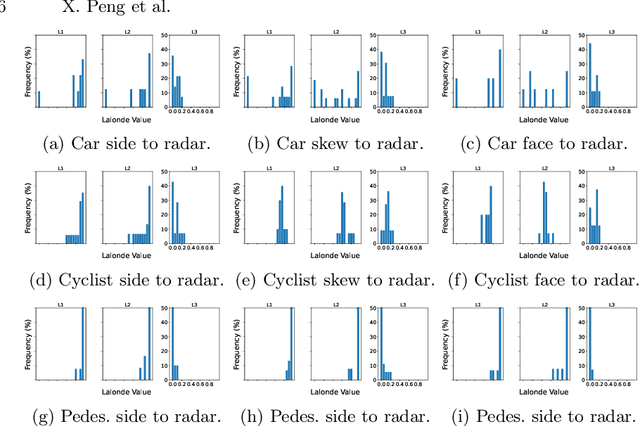

In recent years, approaches based on radar object detection have made significant progress in autonomous driving systems due to their robustness under adverse weather compared to LiDAR. However, the sparsity of radar point clouds poses challenges in achieving precise object detection, highlighting the importance of effective and comprehensive feature extraction technologies. To address this challenge, this paper introduces a comprehensive feature extraction method for radar point clouds. This study first enhances the capability of detection networks by using a plug-and-play module, GeoSPA. It leverages the Lalonde features to explore local geometric patterns. Additionally, a distributed multi-view attention mechanism, DEMVA, is designed to integrate the shared information across the entire dataset with the global information of each individual frame. By employing the two modules, we present our method, MUFASA, which enhances object detection performance through improved feature extraction. The approach is evaluated on the VoD and TJ4DRaDSet datasets to demonstrate its effectiveness. In particular, we achieve state-of-the-art results among radar-based methods on the VoD dataset with the mAP of 50.24%.