 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Network Pruning with Structural Redundancy Reduction
Apr 08, 2021
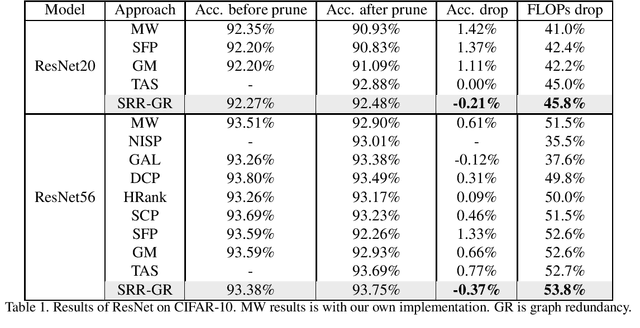
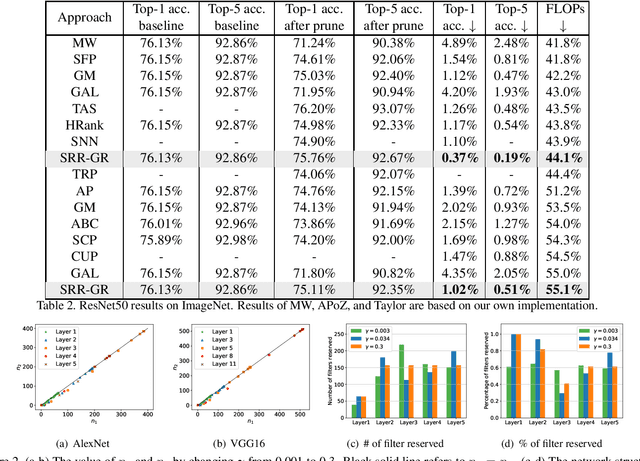
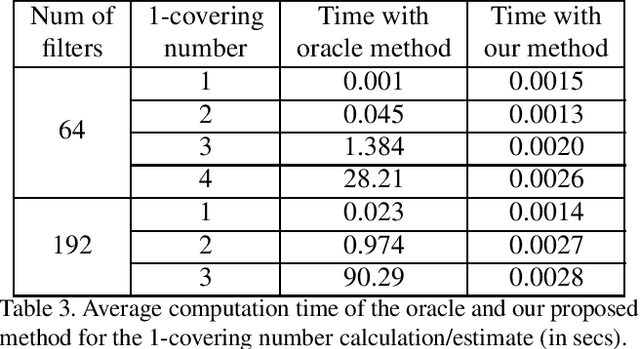
Convolutional neural network (CNN) pruning has become one of the most successful network compression approaches in recent years. Existing works on network pruning usually focus on removing the least important filters in the network to achieve compact architectures. In this study, we claim that identifying structural redundancy plays a more essential role than finding unimportant filters, theoretically and empirically. We first statistically model the network pruning problem in a redundancy reduction perspective and find that pruning in the layer(s) with the most structural redundancy outperforms pruning the least important filters across all layers. Based on this finding, we then propose a network pruning approach that identifies structural redundancy of a CNN and prunes filters in the selected layer(s) with the most redundancy. Experiments on various benchmark network architectures and datasets show that our proposed approach significantly outperforms the previous state-of-the-art.
Investigating Channel Pruning through Structural Redundancy Reduction - A Statistical Study
May 19, 2019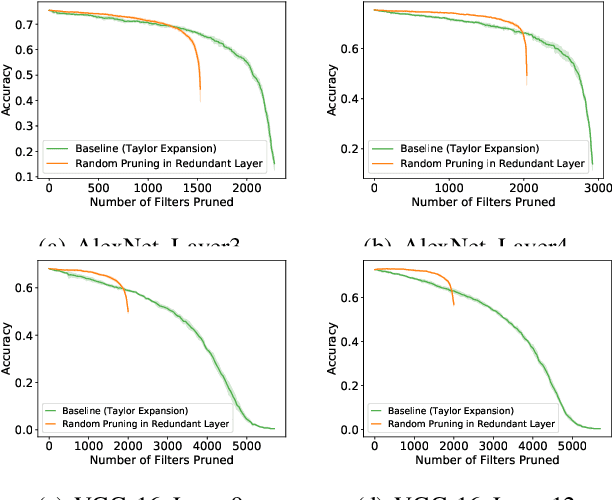
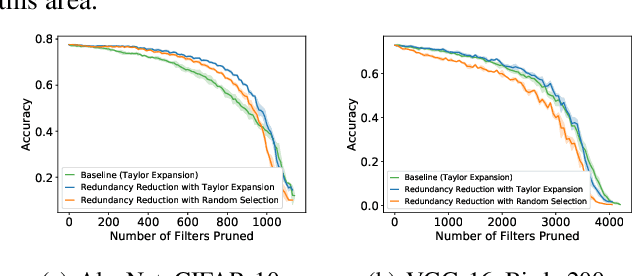
Most existing channel pruning methods formulate the pruning task from a perspective of inefficiency reduction which iteratively rank and remove the least important filters, or find the set of filters that minimizes some reconstruction errors after pruning. In this work, we investigate the channel pruning from a new perspective with statistical modeling. We hypothesize that the number of filters at a certain layer reflects the level of 'redundancy' in that layer and thus formulate the pruning problem from the aspect of redundancy reduction. Based on both theoretic analysis and empirical studies, we make an important discovery: randomly pruning filters from layers of high redundancy outperforms pruning the least important filters across all layers based on the state-of-the-art ranking criterion. These results advance our understanding of pruning and further testify to the recent findings that the structure of the pruned model plays a key role in the network efficiency as compared to inherited weights.
Speeding up convolutional networks pruning with coarse ranking
Feb 18, 2019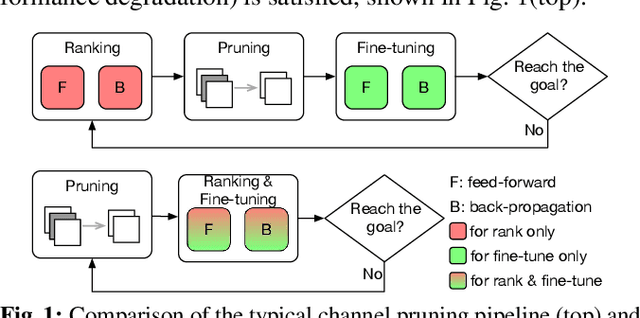
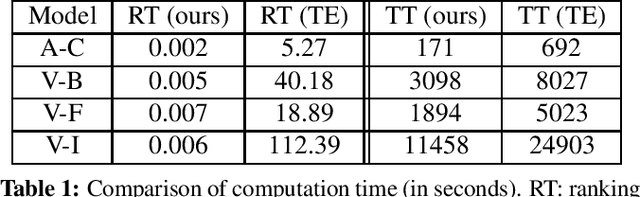
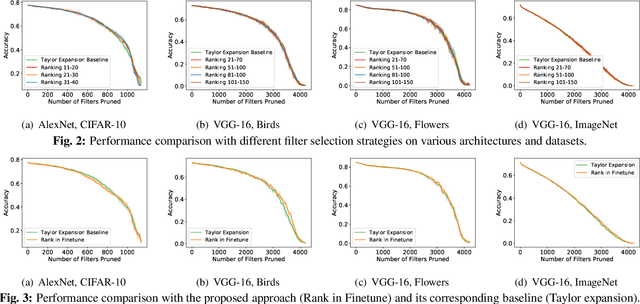
Channel-based pruning has achieved significant successes in accelerating deep convolutional neural network, whose pipeline is an iterative three-step procedure: ranking, pruning and fine-tuning. However, this iterative procedure is computationally expensive. In this study, we present a novel computationally efficient channel pruning approach based on the coarse ranking that utilizes the intermediate results during fine-tuning to rank the importance of filters, built upon state-of-the-art works with data-driven ranking criteria. The goal of this work is not to propose a single improved approach built upon a specific channel pruning method, but to introduce a new general framework that works for a series of channel pruning methods. Various benchmark image datasets (CIFAR-10, ImageNet, Birds-200, and Flowers-102) and network architectures (AlexNet and VGG-16) are utilized to evaluate the proposed approach for object classification purpose. Experimental results show that the proposed method can achieve almost identical performance with the corresponding state-of-the-art works (baseline) while our ranking time is negligibly short. In specific, with the proposed method, 75% and 54% of the total computation time for the whole pruning procedure can be reduced for AlexNet on CIFAR-10, and for VGG-16 on ImageNet, respectively. Our approach would significantly facilitate pruning practice, especially on resource-constrained platforms.
Single-shot Channel Pruning Based on Alternating Direction Method of Multipliers
Feb 18, 2019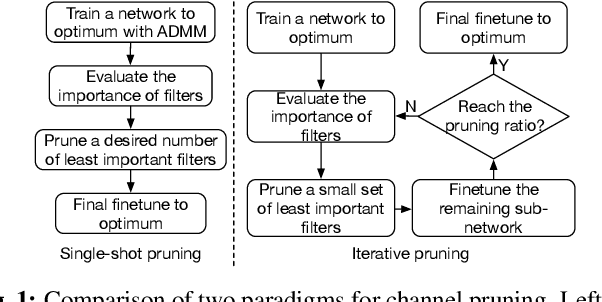
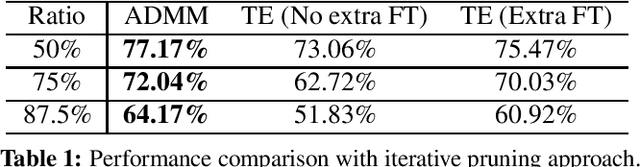
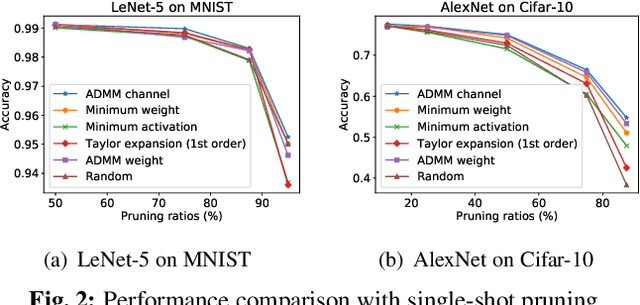
Channel pruning has been identified as an effective approach to constructing efficient network structures. Its typical pipeline requires iterative pruning and fine-tuning. In this work, we propose a novel single-shot channel pruning approach based on alternating direction methods of multipliers (ADMM), which can eliminate the need for complex iterative pruning and fine-tuning procedure and achieve a target compression ratio with only one run of pruning and fine-tuning. To the best of our knowledge, this is the first study of single-shot channel pruning. The proposed method introduces filter-level sparsity during training and can achieve competitive performance with a simple heuristic pruning criterion (L1-norm). Extensive evaluations have been conducted with various widely-used benchmark architectures and image datasets for object classification purpose. The experimental results on classification accuracy show that the proposed method can outperform state-of-the-art network pruning works under various scenarios.