 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Boundary Knowledge Translation for Foreground Segmentation
Aug 01, 2021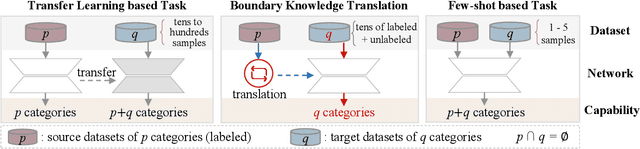



When confronted with objects of unknown types in an image, humans can effortlessly and precisely tell their visual boundaries. This recognition mechanism and underlying generalization capability seem to contrast to state-of-the-art image segmentation networks that rely on large-scale category-aware annotated training samples. In this paper, we make an attempt towards building models that explicitly account for visual boundary knowledge, in hope to reduce the training effort on segmenting unseen categories. Specifically, we investigate a new task termed as Boundary Knowledge Translation (BKT). Given a set of fully labeled categories, BKT aims to translate the visual boundary knowledge learned from the labeled categories, to a set of novel categories, each of which is provided only a few labeled samples. To this end, we propose a Translation Segmentation Network (Trans-Net), which comprises a segmentation network and two boundary discriminators. The segmentation network, combined with a boundary-aware self-supervised mechanism, is devised to conduct foreground segmentation, while the two discriminators work together in an adversarial manner to ensure an accurate segmentation of the novel categories under light supervision. Exhaustive experiments demonstrate that, with only tens of labeled samples as guidance, Trans-Net achieves close results on par with fully supervised methods.