 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeachPro: Multi-Label Qualitative Teaching Evaluation via Cross-View Graph Synergy and Semantic Anchored Evidence Encoding
Jan 14, 2026Standardized Student Evaluation of Teaching often suffer from low reliability, restricted response options, and response distortion. Existing machine learning methods that mine open-ended comments usually reduce feedback to binary sentiment, which overlooks concrete concerns such as content clarity, feedback timeliness, and instructor demeanor, and provides limited guidance for instructional improvement.We propose TeachPro, a multi-label learning framework that systematically assesses five key teaching dimensions: professional expertise, instructional behavior, pedagogical efficacy, classroom experience, and other performance metrics. We first propose a Dimension-Anchored Evidence Encoder, which integrates three core components: (i) a pre-trained text encoder that transforms qualitative feedback annotations into contextualized embeddings; (ii) a prompt module that represents five teaching dimensions as learnable semantic anchors; and (iii) a cross-attention mechanism that aligns evidence with pedagogical dimensions within a structured semantic space. We then propose a Cross-View Graph Synergy Network to represent student comments. This network comprises two components: (i) a Syntactic Branch that extracts explicit grammatical dependencies from parse trees, and (ii) a Semantic Branch that models latent conceptual relations derived from BERT-based similarity graphs. BiAffine fusion module aligns syntactic and semantic units, while a differential regularizer disentangles embeddings to encourage complementary representations. Finally, a cross-attention mechanism bridges the dimension-anchored evidence with the multi-view comment representations. We also contribute a novel benchmark dataset featuring expert qualitative annotations and multi-label scores. Extensive experiments demonstrate that TeachPro offers superior diagnostic granularity and robustness across diverse evaluation settings.
Adversarial Reciprocal Points Learning for Open Set Recognition
Mar 02, 2021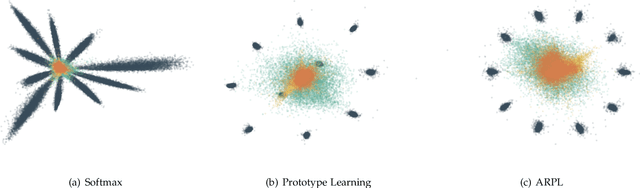
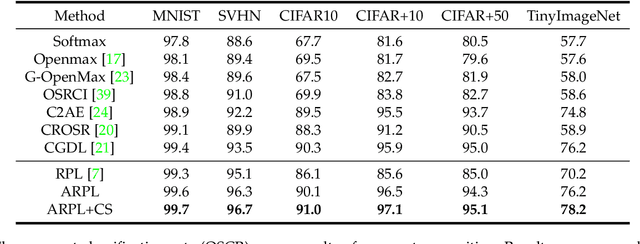
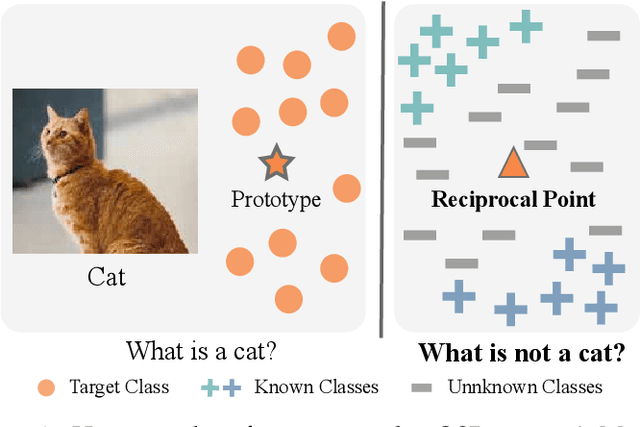
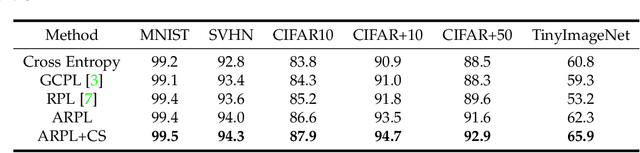
Open set recognition (OSR), aiming to simultaneously classify the seen classes and identify the unseen classes as 'unknown', is essential for reliable machine learning.The key challenge of OSR is how to reduce the empirical classification risk on the labeled known data and the open space risk on the potential unknown data simultaneously. To handle the challenge, we formulate the open space risk problem from the perspective of multi-class integration, and model the unexploited extra-class space with a novel concept Reciprocal Point. Follow this, a novel learning framework, termed Adversarial Reciprocal Point Learning (ARPL), is proposed to minimize the overlap of known distribution and unknown distributions without loss of known classification accuracy. Specifically, each reciprocal point is learned by the extra-class space with the corresponding known category, and the confrontation among multiple known categories are employed to reduce the empirical classification risk. Then, an adversarial margin constraint is proposed to reduce the open space risk by limiting the latent open space constructed by reciprocal points. To further estimate the unknown distribution from open space, an instantiated adversarial enhancement method is designed to generate diverse and confusing training samples, based on the adversarial mechanism between the reciprocal points and known classes. This can effectively enhance the model distinguishability to the unknown classes. Extensive experimental results on various benchmark datasets indicate that the proposed method is significantly superior to other existing approaches and achieves state-of-the-art performance.
Variationally and Intrinsically motivated reinforcement learning for decentralized traffic signal control
Jan 20, 2021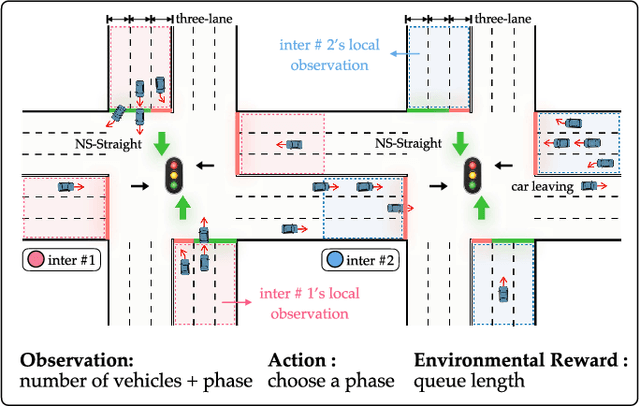

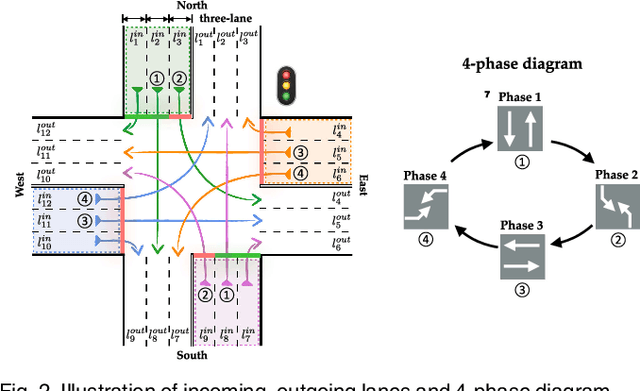

One of the biggest challenges in multi-agent reinforcement learning is coordination, a typical application scenario of this is traffic signal control. Recently, it has attracted a rising number of researchers and has become a hot research field with great practical significance. In this paper, we propose a novel method called MetaVRS~(Meta Variational RewardShaping) for traffic signal coordination control. By heuristically applying the intrinsic reward to the environmental reward, MetaVRS can wisely capture the agent-to-agent interplay. Besides, latent variables generated by VAE are brought into policy for automatically tradeoff between exploration and exploitation to optimize the policy. In addition, meta learning was used in decoder for faster adaptation and better approximation. Empirically, we demonstate that MetaVRS substantially outperforms existing methods and shows superior adaptability, which predictably has a far-reaching significance to the multi-agent traffic signal coordination control.