 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy on Feature Subspace of Archetypal Emotions for Speech Emotion Recognition
Nov 17, 2016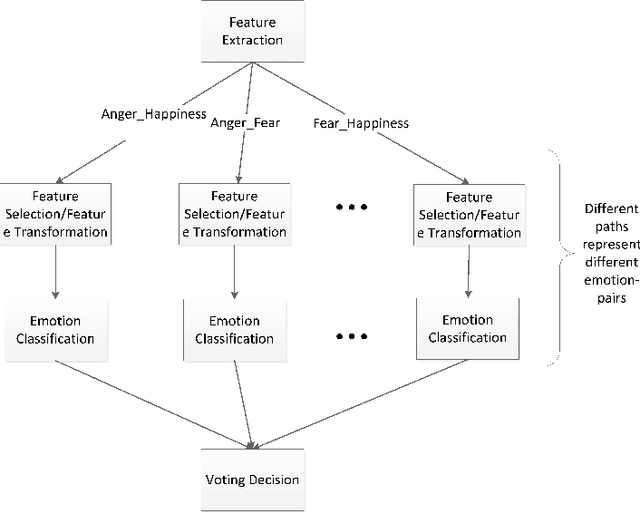

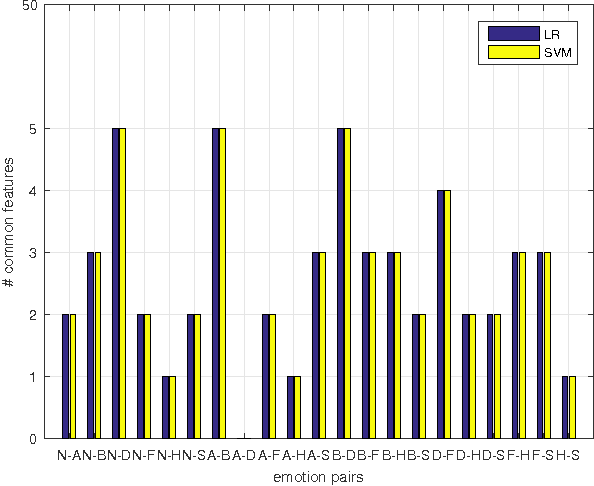
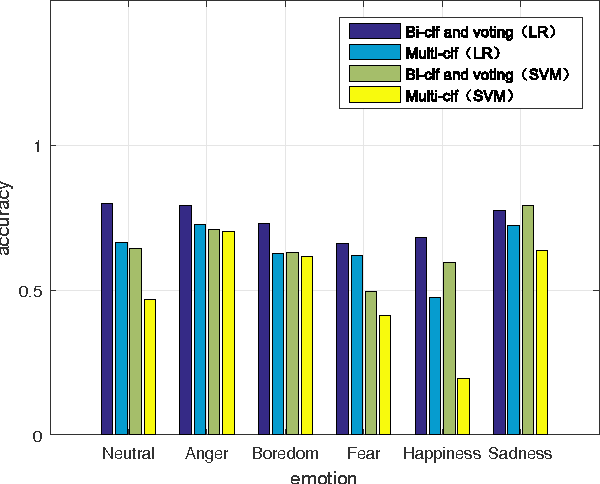
Feature subspace selection is an important part in speech emotion recognition. Most of the studies are devoted to finding a feature subspace for representing all emotions. However, some studies have indicated that the features associated with different emotions are not exactly the same. Hence, traditional methods may fail to distinguish some of the emotions with just one global feature subspace. In this work, we propose a new divide and conquer idea to solve the problem. First, the feature subspaces are constructed for all the combinations of every two different emotions (emotion-pair). Bi-classifiers are then trained on these feature subspaces respectively. The final emotion recognition result is derived by the voting and competition method. Experimental results demonstrate that the proposed method can get better results than the traditional multi-classification method.
Recognize Foreign Low-Frequency Words with Similar Pairs
Jun 16, 2015

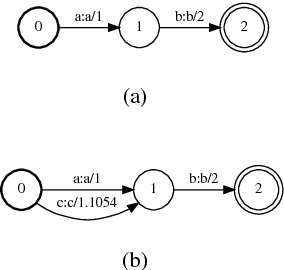
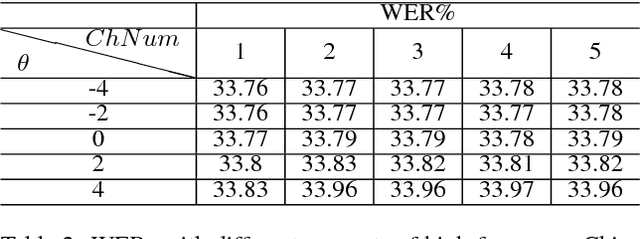
Low-frequency words place a major challenge for automatic speech recognition (ASR). The probabilities of these words, which are often important name entities, are generally under-estimated by the language model (LM) due to their limited occurrences in the training data. Recently, we proposed a word-pair approach to deal with the problem, which borrows information of frequent words to enhance the probabilities of low-frequency words. This paper presents an extension to the word-pair method by involving multiple `predicting words' to produce better estimation for low-frequency words. We also employ this approach to deal with out-of-language words in the task of multi-lingual speech recognition.