 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study in Surgical AI: Datasets, Foundation Models, and Barriers to Med-AGI
Mar 28, 2026Recent Artificial Intelligence (AI) models have matched or exceeded human experts in several benchmarks of biomedical task performance, but have lagged behind on surgical image-analysis benchmarks. Since surgery requires integrating disparate tasks -- including multimodal data integration, human interaction, and physical effects -- generally-capable AI models could be particularly attractive as a collaborative tool if performance could be improved. On the one hand, the canonical approach of scaling architecture size and training data is attractive, especially since there are millions of hours of surgical video data generated per year. On the other hand, preparing surgical data for AI training requires significantly higher levels of professional expertise, and training on that data requires expensive computational resources. These trade-offs paint an uncertain picture of whether and to-what-extent modern AI could aid surgical practice. In this paper, we explore this question through a case study of surgical tool detection using state-of-the-art AI methods available in 2026. We demonstrate that even with multi-billion parameter models and extensive training, current Vision Language Models fall short in the seemingly simple task of tool detection in neurosurgery. Additionally, we show scaling experiments indicating that increasing model size and training time only leads to diminishing improvements in relevant performance metrics. Thus, our experiments suggest that current models could still face significant obstacles in surgical use cases. Moreover, some obstacles cannot be simply ``scaled away'' with additional compute and persist across diverse model architectures, raising the question of whether data and label availability are the only limiting factors. We discuss the main contributors to these constraints and advance potential solutions.
SurgPhase: Time efficient pituitary tumor surgery phase recognition via an interactive web platform
Mar 26, 2026Accurate surgical phase recognition is essential for analyzing procedural workflows, supporting intraoperative decision-making, and enabling data-driven improvements in surgical education and performance evaluation. In this work, we present a comprehensive framework for phase recognition in pituitary tumor surgery (PTS) videos, combining self-supervised representation learning, robust temporal modeling, and scalable data annotation strategies. Our method achieves 90\% accuracy on a held-out test set, outperforming current state-of-the-art approaches and demonstrating strong generalization across variable surgical cases. A central contribution of this work is the integration of a collaborative online platform designed for surgeons to upload surgical videos, receive automated phase analysis, and contribute to a growing dataset. This platform not only facilitates large-scale data collection but also fosters knowledge sharing and continuous model improvement. To address the challenge of limited labeled data, we pretrain a ResNet-50 model using the self-supervised framework on 251 unlabeled PTS videos, enabling the extraction of high-quality feature representations. Fine-tuning is performed on a labeled dataset of 81 procedures using a modified training regime that incorporates focal loss, gradual layer unfreezing, and dynamic sampling to address class imbalance and procedural variability.
Survey Descent: A Multipoint Generalization of Gradient Descent for Nonsmooth Optimization
Dec 29, 2021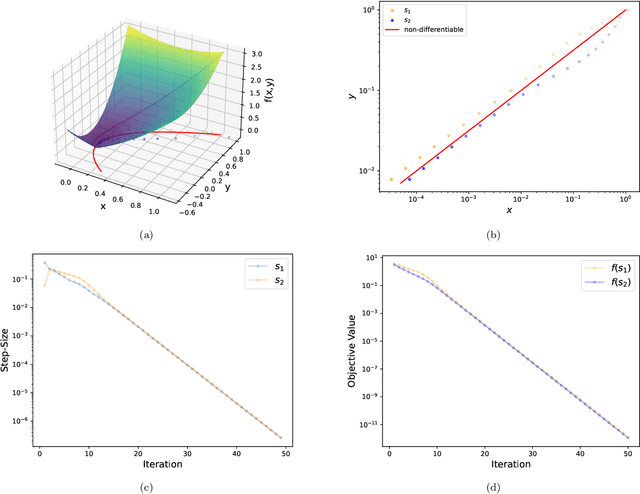
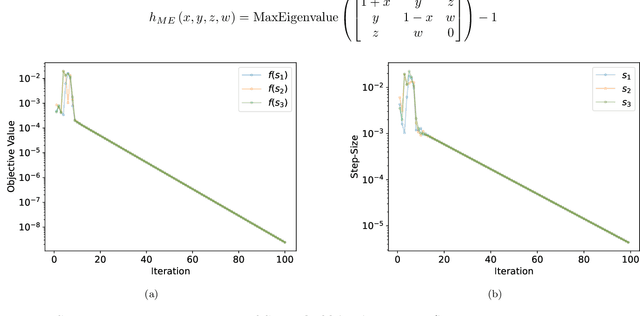
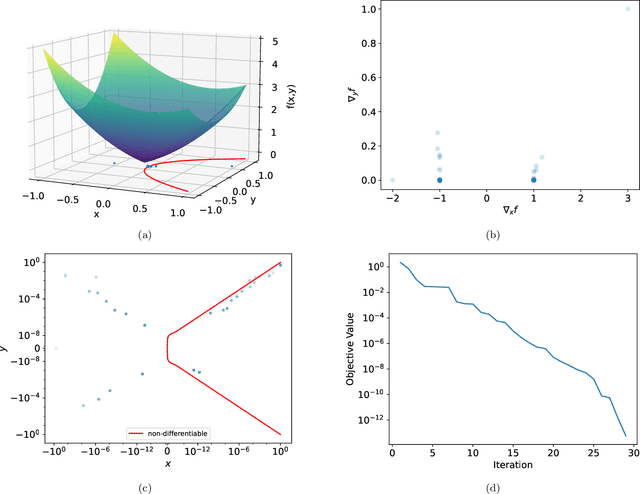
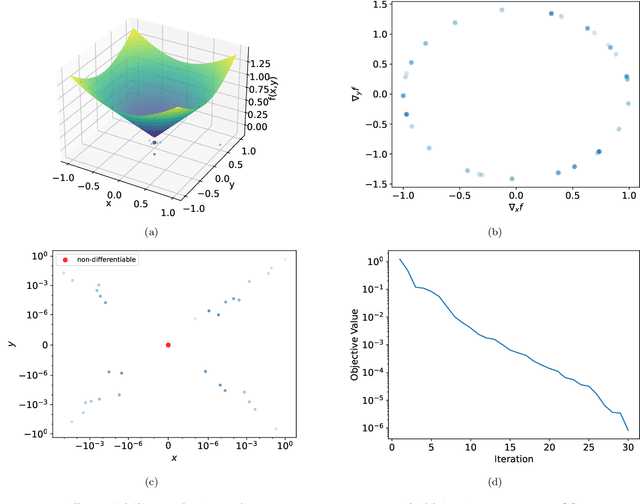
For strongly convex objectives that are smooth, the classical theory of gradient descent ensures linear convergence relative to the number of gradient evaluations. An analogous nonsmooth theory is challenging: even when the objective is smooth at every iterate, the corresponding local models are unstable, and traditional remedies need unpredictably many cutting planes. We instead propose a multipoint generalization of the gradient descent iteration for local optimization. While designed with general objectives in mind, we are motivated by a "max-of-smooth" model that captures subdifferential dimension at optimality. We prove linear convergence when the objective is itself max-of-smooth, and experiments suggest a more general phenomenon.
Neural Collapse Under MSE Loss: Proximity to and Dynamics on the Central Path
Jun 03, 2021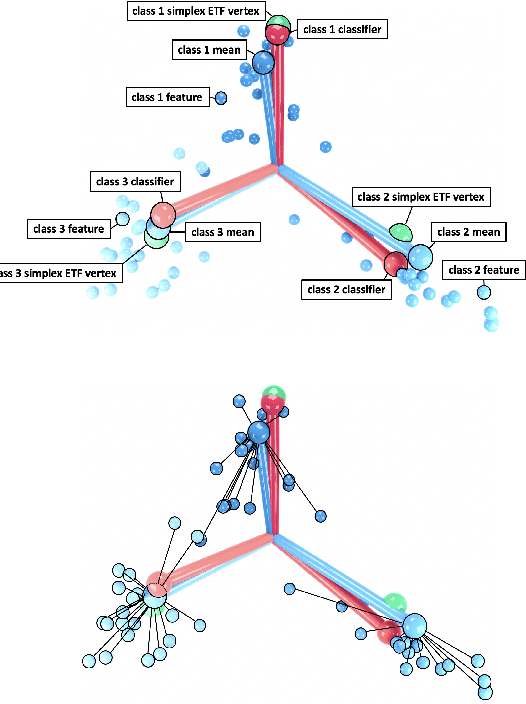
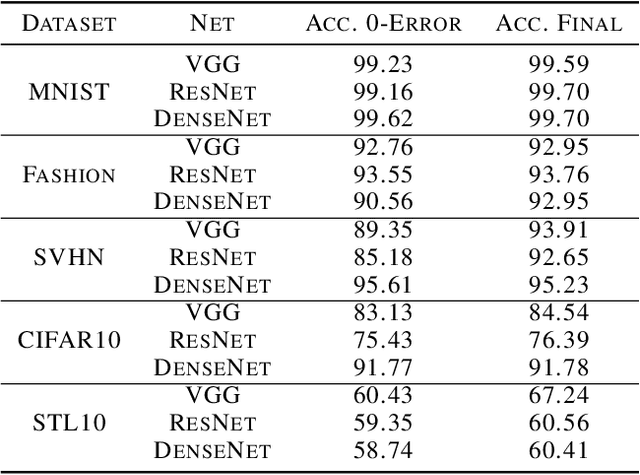
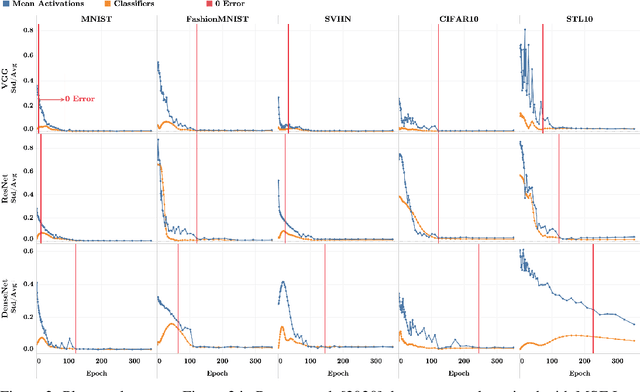
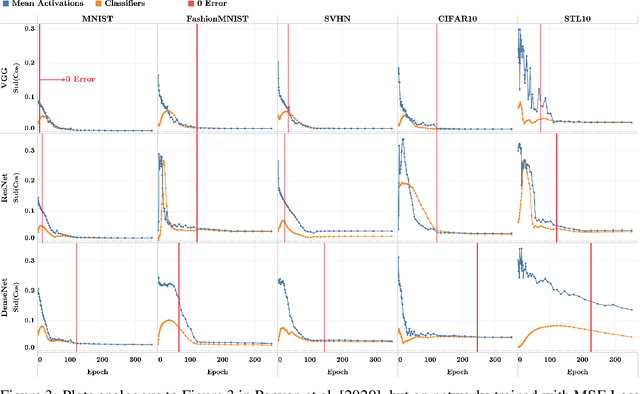
Recent work [Papyan, Han, and Donoho, 2020] discovered a phenomenon called Neural Collapse (NC) that occurs pervasively in today's deep net training paradigm of driving cross-entropy loss towards zero. In this phenomenon, the last-layer features collapse to their class-means, both the classifiers and class-means collapse to the same Simplex Equiangular Tight Frame (ETF), and the behavior of the last-layer classifier converges to that of the nearest-class-mean decision rule. Since then, follow-ups-such as Mixon et al. [2020] and Poggio and Liao [2020a,b]-formally analyzed this inductive bias by replacing the hard-to-study cross-entropy by the more tractable mean squared error (MSE) loss. But, these works stopped short of demonstrating the empirical reality of MSE-NC on benchmark datasets and canonical networks-as had been done in Papyan, Han, and Donoho [2020] for the cross-entropy loss. In this work, we establish the empirical reality of MSE-NC by reporting experimental observations for three prototypical networks and five canonical datasets with code for reproducing NC. Following this, we develop three main contributions inspired by MSE-NC. Firstly, we show a new theoretical decomposition of the MSE loss into (A) a term assuming the last-layer classifier is exactly the least-squares or Webb and Lowe [1990] classifier and (B) a term capturing the deviation from this least-squares classifier. Secondly, we exhibit experiments on canonical datasets and networks demonstrating that, during training, term-(B) is negligible. This motivates a new theoretical construct: the central path, where the linear classifier stays MSE-optimal-for the given feature activations-throughout the dynamics. Finally, through our study of continually renormalized gradient flow along the central path, we produce closed-form dynamics that predict full Neural Collapse in an unconstrained features model.
Prevalence of Neural Collapse during the terminal phase of deep learning training
Aug 21, 2020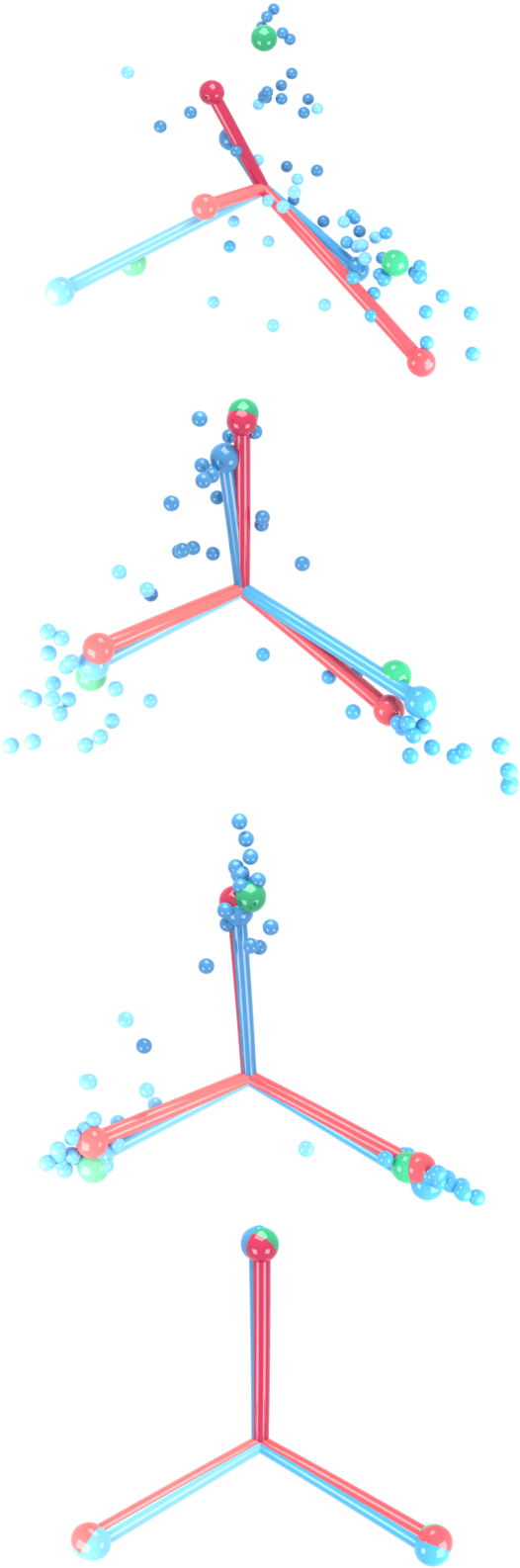
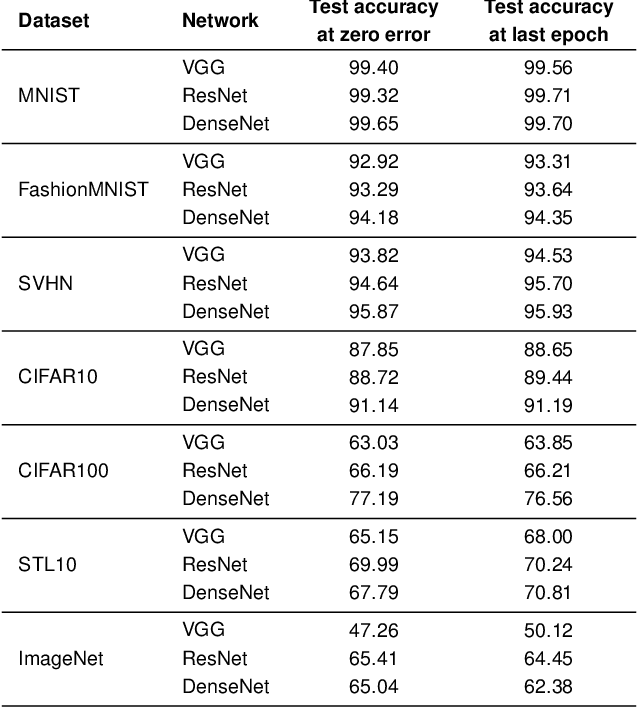
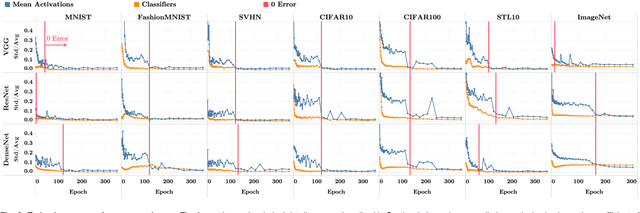
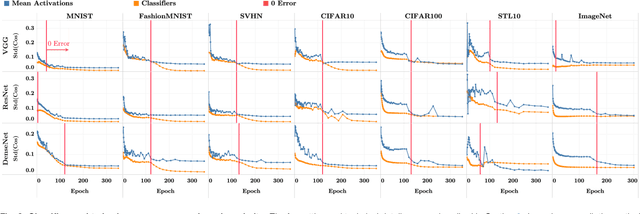
Modern practice for training classification deepnets involves a Terminal Phase of Training (TPT), which begins at the epoch where training error first vanishes; During TPT, the training error stays effectively zero while training loss is pushed towards zero. Direct measurements of TPT, for three prototypical deepnet architectures and across seven canonical classification datasets, expose a pervasive inductive bias we call Neural Collapse, involving four deeply interconnected phenomena: (NC1) Cross-example within-class variability of last-layer training activations collapses to zero, as the individual activations themselves collapse to their class-means; (NC2) The class-means collapse to the vertices of a Simplex Equiangular Tight Frame (ETF); (NC3) Up to rescaling, the last-layer classifiers collapse to the class-means, or in other words to the Simplex ETF, i.e. to a self-dual configuration; (NC4) For a given activation, the classifier's decision collapses to simply choosing whichever class has the closest train class-mean, i.e. the Nearest Class Center (NCC) decision rule. The symmetric and very simple geometry induced by the TPT confers important benefits, including better generalization performance, better robustness, and better interpretability.