 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Adaptive MCMC
May 22, 2024



An informal observation, made by several authors, is that the adaptive design of a Markov transition kernel has the flavour of a reinforcement learning task. Yet, to-date it has remained unclear how to actually exploit modern reinforcement learning technologies for adaptive MCMC. The aim of this paper is to set out a general framework, called Reinforcement Learning Metropolis--Hastings, that is theoretically supported and empirically validated. Our principal focus is on learning fast-mixing Metropolis--Hastings transition kernels, which we cast as deterministic policies and optimise via a policy gradient. Control of the learning rate provably ensures conditions for ergodicity are satisfied. The methodology is used to construct a gradient-free sampler that out-performs a popular gradient-free adaptive Metropolis--Hastings algorithm on $\approx 90 \%$ of tasks in the PosteriorDB benchmark.
Optimal Thinning of MCMC Output
May 08, 2020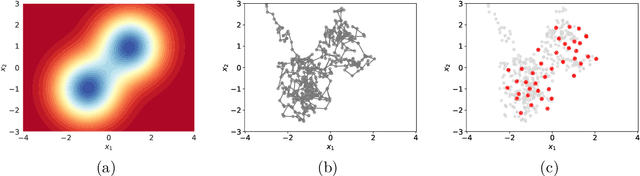


The use of heuristics to assess the convergence and compress the output of Markov chain Monte Carlo can be sub-optimal in terms of the empirical approximations that are produced. Typically a number of the initial states are attributed to "burn in" and removed, whilst the chain can be "thinned" if compression is also required. In this paper we consider the problem of selecting a subset of states, of fixed cardinality, such that the approximation provided by their empirical distribution is close to optimal. A novel method is proposed, based on greedy minimisation of a kernel Stein discrepancy, that is suitable for problems where heavy compression is required. Theoretical results guarantee consistency of the method and its effectiveness is demonstrated in the challenging context of parameter inference for ordinary differential equations. Software is available in the "Stein Thinning" package in both Python and MATLAB, and example code is included.