 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResGCN: Attention-based Deep Residual Modeling for Anomaly Detection on Attributed Networks
Sep 30, 2020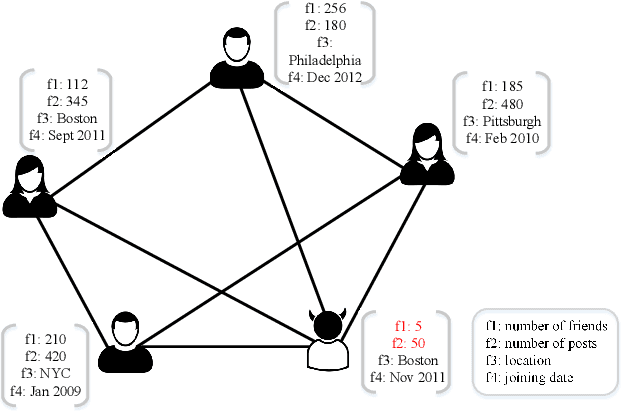

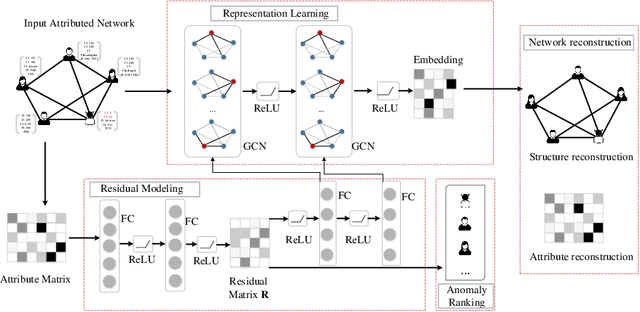
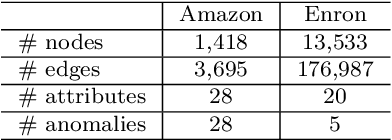
Effectively detecting anomalous nodes in attributed networks is crucial for the success of many real-world applications such as fraud and intrusion detection. Existing approaches have difficulties with three major issues: sparsity and nonlinearity capturing, residual modeling, and network smoothing. We propose Residual Graph Convolutional Network (ResGCN), an attention-based deep residual modeling approach that can tackle these issues: modeling the attributed networks with GCN allows to capture the sparsity and nonlinearity; utilizing a deep neural network allows to directly learn residual from the input, and a residual-based attention mechanism reduces the adverse effect from anomalous nodes and prevents over-smoothing. Extensive experiments on several real-world attributed networks demonstrate the effectiveness of ResGCN in detecting anomalies.
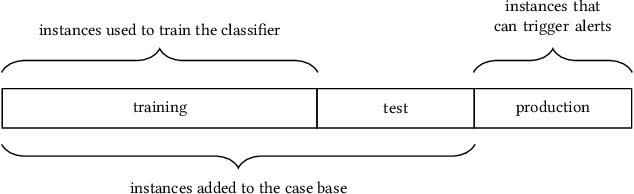
Case-Based Reasoning for Assisting Domain Experts in Processing Fraud Alerts of Black-Box Machine Learning Models
Jul 07, 2019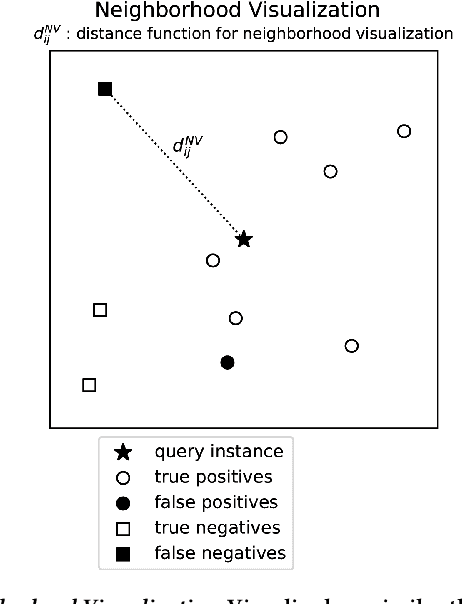

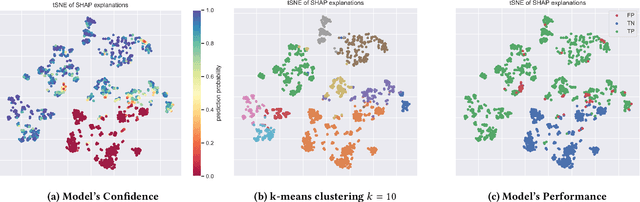
In many contexts, it can be useful for domain experts to understand to what extent predictions made by a machine learning model can be trusted. In particular, estimates of trustworthiness can be useful for fraud analysts who process machine learning-generated alerts of fraudulent transactions. In this work, we present a case-based reasoning (CBR) approach that provides evidence on the trustworthiness of a prediction in the form of a visualization of similar previous instances. Different from previous works, we consider similarity of local post-hoc explanations of predictions and show empirically that our visualization can be useful for processing alerts. Furthermore, our approach is perceived useful and easy to use by fraud analysts at a major Dutch bank.
A Human-Grounded Evaluation of SHAP for Alert Processing
Jul 07, 2019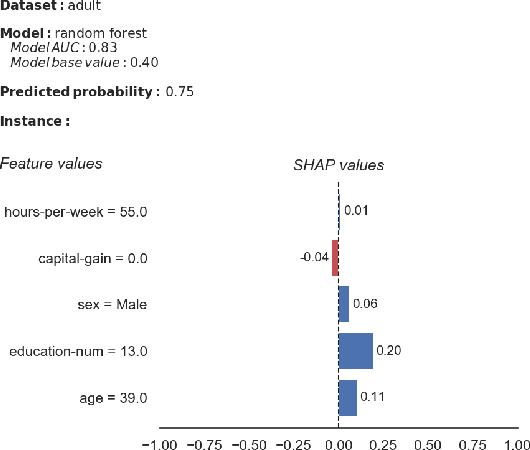


In the past years, many new explanation methods have been proposed to achieve interpretability of machine learning predictions. However, the utility of these methods in practical applications has not been researched extensively. In this paper we present the results of a human-grounded evaluation of SHAP, an explanation method that has been well-received in the XAI and related communities. In particular, we study whether this local model-agnostic explanation method can be useful for real human domain experts to assess the correctness of positive predictions, i.e. alerts generated by a classifier. We performed experimentation with three different groups of participants (159 in total), who had basic knowledge of explainable machine learning. We performed a qualitative analysis of recorded reflections of experiment participants performing alert processing with and without SHAP information. The results suggest that the SHAP explanations do impact the decision-making process, although the model's confidence score remains to be a leading source of evidence. We statistically test whether there is a significant difference in task utility metrics between tasks for which an explanation was available and tasks in which it was not provided. As opposed to common intuitions, we did not find a significant difference in alert processing performance when a SHAP explanation is available compared to when it is not.
Looking Deeper into Deep Learning Model: Attribution-based Explanations of TextCNN
Dec 02, 2018
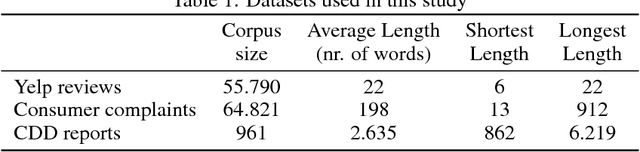
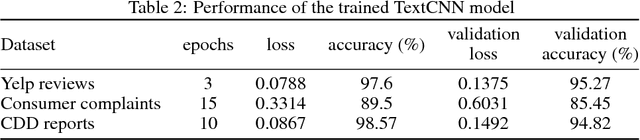
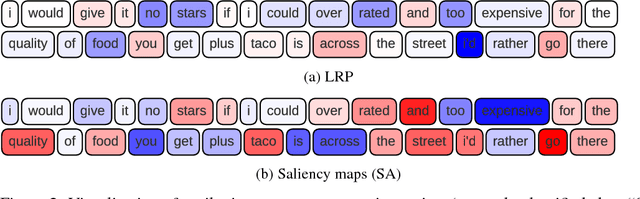
Layer-wise Relevance Propagation (LRP) and saliency maps have been recently used to explain the predictions of Deep Learning models, specifically in the domain of text classification. Given different attribution-based explanations to highlight relevant words for a predicted class label, experiments based on word deleting perturbation is a common evaluation method. This word removal approach, however, disregards any linguistic dependencies that may exist between words or phrases in a sentence, which could semantically guide a classifier to a particular prediction. In this paper, we present a feature-based evaluation framework for comparing the two attribution methods on customer reviews (public data sets) and Customer Due Diligence (CDD) extracted reports (corporate data set). Instead of removing words based on the relevance score, we investigate perturbations based on embedded features removal from intermediate layers of Convolutional Neural Networks. Our experimental study is carried out on embedded-word, embedded-document, and embedded-ngrams explanations. Using the proposed framework, we provide a visualization tool to assist analysts in reasoning toward the model's final prediction.