 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Deeper into Deep Learning Model: Attribution-based Explanations of TextCNN
Dec 02, 2018
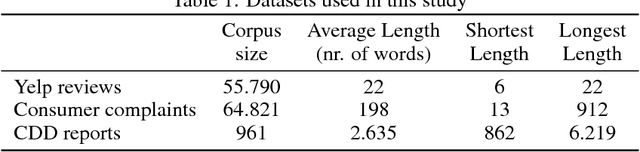
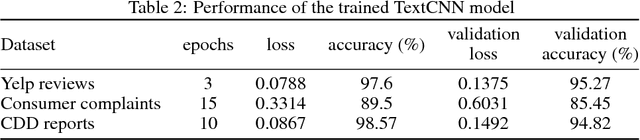
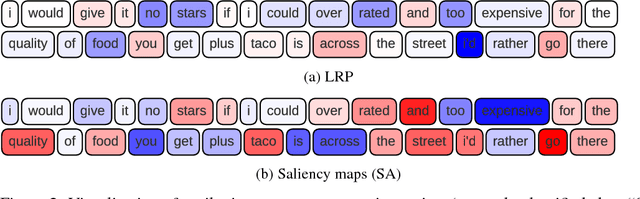
Layer-wise Relevance Propagation (LRP) and saliency maps have been recently used to explain the predictions of Deep Learning models, specifically in the domain of text classification. Given different attribution-based explanations to highlight relevant words for a predicted class label, experiments based on word deleting perturbation is a common evaluation method. This word removal approach, however, disregards any linguistic dependencies that may exist between words or phrases in a sentence, which could semantically guide a classifier to a particular prediction. In this paper, we present a feature-based evaluation framework for comparing the two attribution methods on customer reviews (public data sets) and Customer Due Diligence (CDD) extracted reports (corporate data set). Instead of removing words based on the relevance score, we investigate perturbations based on embedded features removal from intermediate layers of Convolutional Neural Networks. Our experimental study is carried out on embedded-word, embedded-document, and embedded-ngrams explanations. Using the proposed framework, we provide a visualization tool to assist analysts in reasoning toward the model's final prediction.