 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance of Tuning Hyperparameters of Machine Learning Algorithms
Jul 15, 2020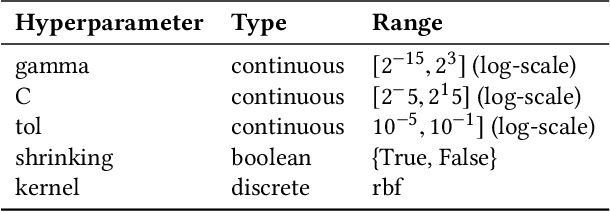
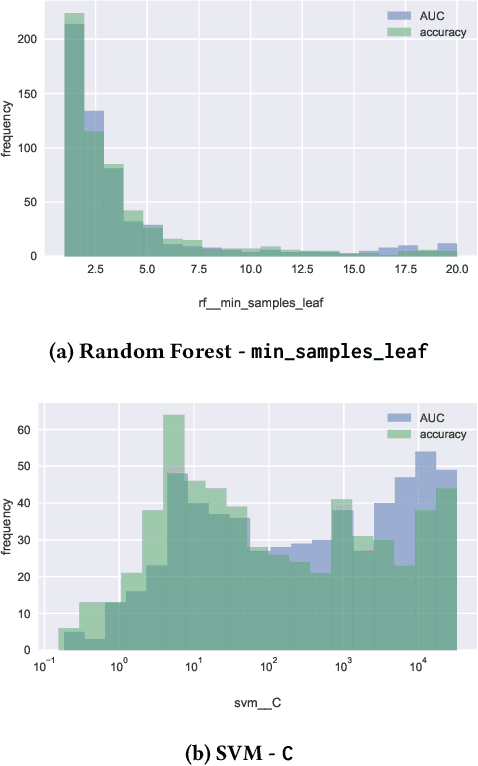


The performance of many machine learning algorithms depends on their hyperparameter settings. The goal of this study is to determine whether it is important to tune a hyperparameter or whether it can be safely set to a default value. We present a methodology to determine the importance of tuning a hyperparameter based on a non-inferiority test and tuning risk: the performance loss that is incurred when a hyperparameter is not tuned, but set to a default value. Because our methods require the notion of a default parameter, we present a simple procedure that can be used to determine reasonable default parameters. We apply our methods in a benchmark study using 59 datasets from OpenML. Our results show that leaving particular hyperparameters at their default value is non-inferior to tuning these hyperparameters. In some cases, leaving the hyperparameter at its default value even outperforms tuning it using a search procedure with a limited number of iterations.
Case-Based Reasoning for Assisting Domain Experts in Processing Fraud Alerts of Black-Box Machine Learning Models
Jul 07, 2019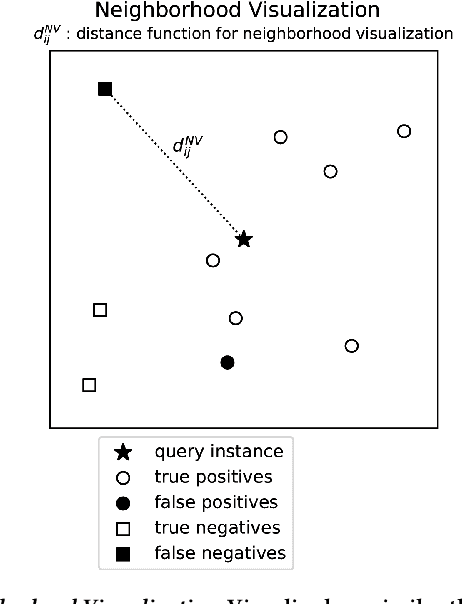

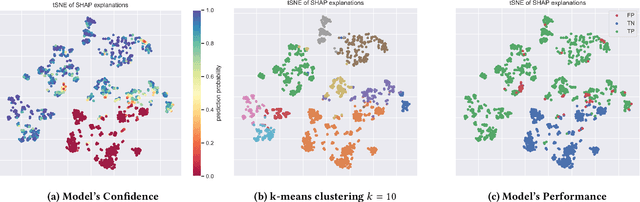
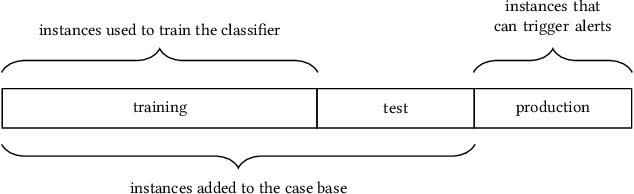
In many contexts, it can be useful for domain experts to understand to what extent predictions made by a machine learning model can be trusted. In particular, estimates of trustworthiness can be useful for fraud analysts who process machine learning-generated alerts of fraudulent transactions. In this work, we present a case-based reasoning (CBR) approach that provides evidence on the trustworthiness of a prediction in the form of a visualization of similar previous instances. Different from previous works, we consider similarity of local post-hoc explanations of predictions and show empirically that our visualization can be useful for processing alerts. Furthermore, our approach is perceived useful and easy to use by fraud analysts at a major Dutch bank.
A Human-Grounded Evaluation of SHAP for Alert Processing
Jul 07, 2019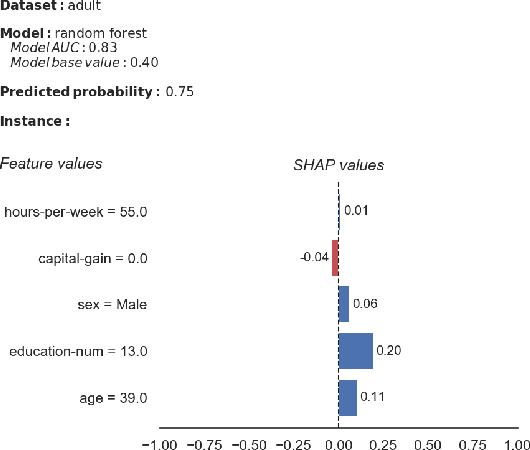


In the past years, many new explanation methods have been proposed to achieve interpretability of machine learning predictions. However, the utility of these methods in practical applications has not been researched extensively. In this paper we present the results of a human-grounded evaluation of SHAP, an explanation method that has been well-received in the XAI and related communities. In particular, we study whether this local model-agnostic explanation method can be useful for real human domain experts to assess the correctness of positive predictions, i.e. alerts generated by a classifier. We performed experimentation with three different groups of participants (159 in total), who had basic knowledge of explainable machine learning. We performed a qualitative analysis of recorded reflections of experiment participants performing alert processing with and without SHAP information. The results suggest that the SHAP explanations do impact the decision-making process, although the model's confidence score remains to be a leading source of evidence. We statistically test whether there is a significant difference in task utility metrics between tasks for which an explanation was available and tasks in which it was not provided. As opposed to common intuitions, we did not find a significant difference in alert processing performance when a SHAP explanation is available compared to when it is not.