 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesignADAM: Learning Confidences for Deep Neural Networks
Jul 21, 2019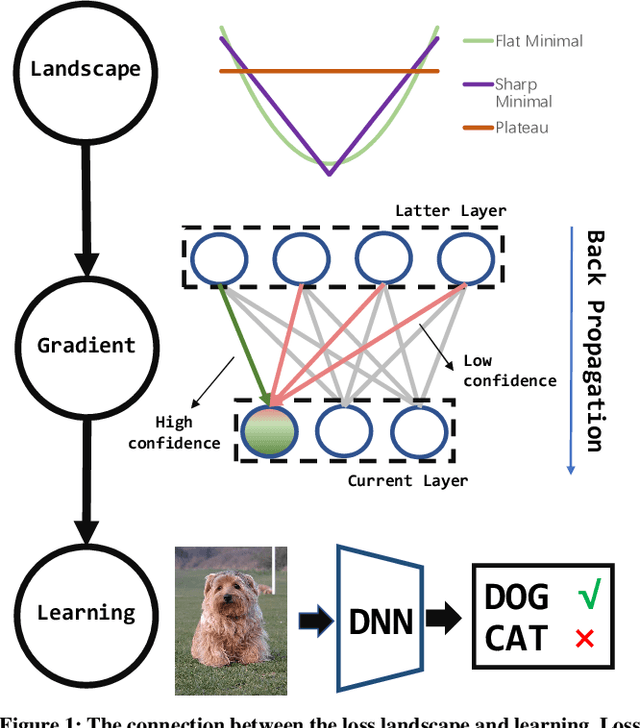

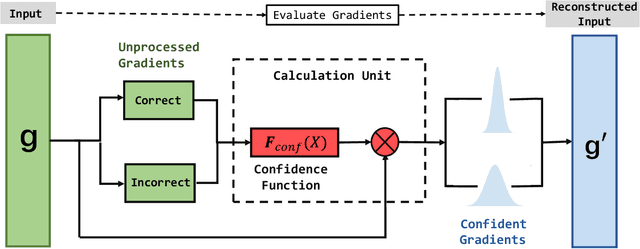

In this paper, we propose a new first-order gradient-based algorithm to train deep neural networks. We first introduce the sign operation of stochastic gradients (as in sign-based methods, e.g., SIGN-SGD) into ADAM, which is called as signADAM. Moreover, in order to make the rate of fitting each feature closer, we define a confidence function to distinguish different components of gradients and apply it to our algorithm. It can generate more sparse gradients than existing algorithms do. We call this new algorithm signADAM++. In particular, both our algorithms are easy to implement and can speed up training of various deep neural networks. The motivation of signADAM++ is preferably learning features from the most different samples by updating large and useful gradients regardless of useless information in stochastic gradients. We also establish theoretical convergence guarantees for our algorithms. Empirical results on various datasets and models show that our algorithms yield much better performance than many state-of-the-art algorithms including SIGN-SGD, SIGNUM and ADAM. We also analyze the performance from multiple perspectives including the loss landscape and develop an adaptive method to further improve generalization. The source code is available at https://github.com/DongWanginxdu/signADAM-Learn-by-Confidence.