 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Deep Learning: A New Framework Immune to Local Traps and Miscalibration
Oct 01, 2021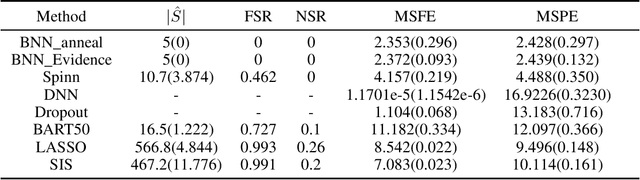
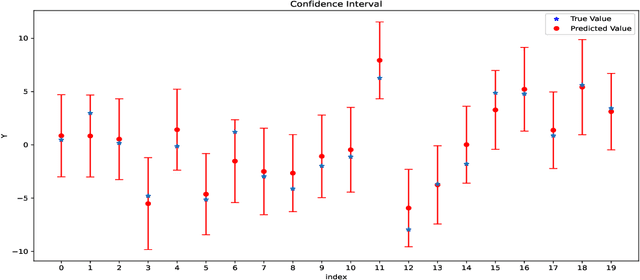
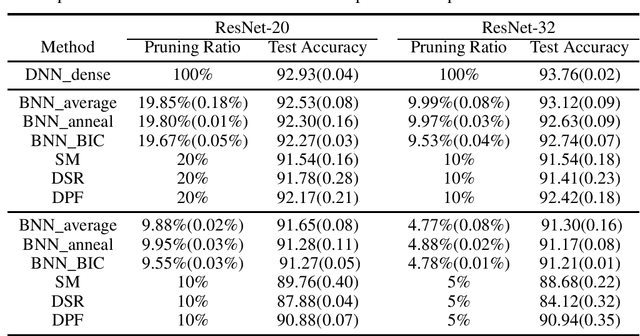
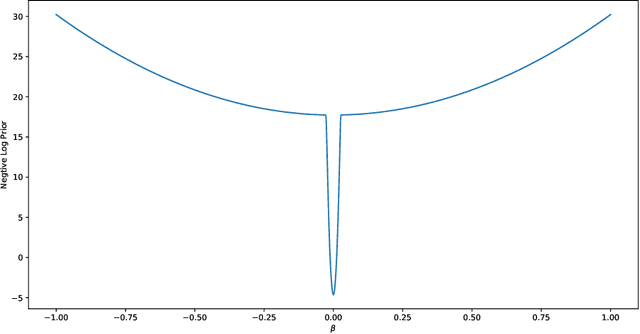
Deep learning has powered recent successes of artificial intelligence (AI). However, the deep neural network, as the basic model of deep learning, has suffered from issues such as local traps and miscalibration. In this paper, we provide a new framework for sparse deep learning, which has the above issues addressed in a coherent way. In particular, we lay down a theoretical foundation for sparse deep learning and propose prior annealing algorithms for learning sparse neural networks. The former has successfully tamed the sparse deep neural network into the framework of statistical modeling, enabling prediction uncertainty correctly quantified. The latter can be asymptotically guaranteed to converge to the global optimum, enabling the validity of the down-stream statistical inference. Numerical result indicates the superiority of the proposed method compared to the existing ones.
MöbiusE: Knowledge Graph Embedding on Möbius Ring
Jan 07, 2021
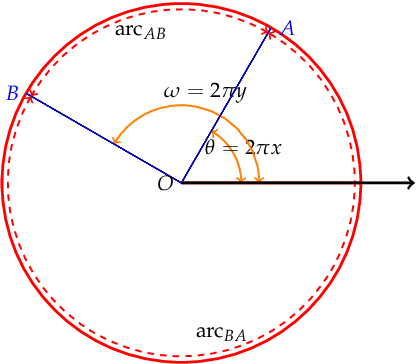
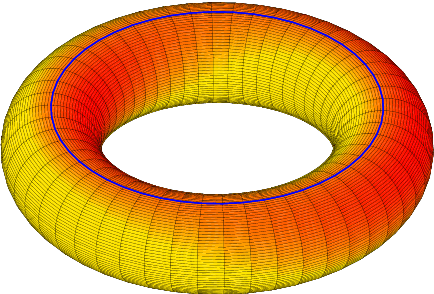
In this work, we propose a novel Knowledge Graph Embedding (KGE) strategy, called M\"{o}biusE, in which the entities and relations are embedded to the surface of a M\"{o}bius ring. The proposition of such a strategy is inspired by the classic TorusE, in which the addition of two arbitrary elements is subject to a modulus operation. In this sense, TorusE naturally guarantees the critical boundedness of embedding vectors in KGE. However, the nonlinear property of addition operation on Torus ring is uniquely derived by the modulus operation, which in some extent restricts the expressiveness of TorusE. As a further generalization of TorusE, M\"{o}biusE also uses modulus operation to preserve the closeness of addition operation on it, but the coordinates on M\"{o}bius ring interacts with each other in the following way: {\em \color{red} any vector on the surface of a M\"{o}bius ring moves along its parametric trace will goes to the right opposite direction after a cycle}. Hence, M\"{o}biusE assumes much more nonlinear representativeness than that of TorusE, and in turn it generates much more precise embedding results. In our experiments, M\"{o}biusE outperforms TorusE and other classic embedding strategies in several key indicators.