 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealCamo: Boosting Real Camouflage Synthesis with Layout Controls and Textual-Visual Guidance
Dec 28, 2025Camouflaged image generation (CIG) has recently emerged as an efficient alternative for acquiring high-quality training data for camouflaged object detection (COD). However, existing CIG methods still suffer from a substantial gap to real camouflaged imagery: generated images either lack sufficient camouflage due to weak visual similarity, or exhibit cluttered backgrounds that are semantically inconsistent with foreground targets. To address these limitations, we propose ReamCamo, a unified out-painting based framework for realistic camouflaged image generation. ReamCamo explicitly introduces additional layout controls to regulate global image structure, thereby improving semantic coherence between foreground objects and generated backgrounds. Moreover, we construct a multi-modal textual-visual condition by combining a unified fine-grained textual task description with texture-oriented background retrieval, which jointly guides the generation process to enhance visual fidelity and realism. To quantitatively assess camouflage quality, we further introduce a background-foreground distribution divergence metric that measures the effectiveness of camouflage in generated images. Extensive experiments and visualizations demonstrate the effectiveness of our proposed framework.
Towards Context-aware Convolutional Network for Image Restoration
Dec 15, 2024
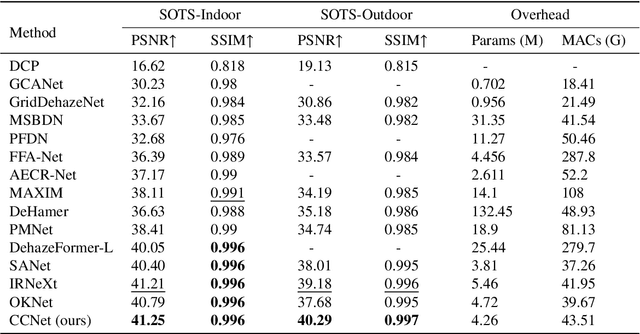


Image restoration (IR) is a long-standing task to recover a high-quality image from its corrupted observation. Recently, transformer-based algorithms and some attention-based convolutional neural networks (CNNs) have presented promising results on several IR tasks. However, existing convolutional residual building modules for IR encounter limited ability to map inputs into high-dimensional and non-linear feature spaces, and their local receptive fields have difficulty in capturing long-range context information like Transformer. Besides, CNN-based attention modules for IR either face static abundant parameters or have limited receptive fields. To address the first issue, we propose an efficient residual star module (ERSM) that includes context-aware "star operation" (element-wise multiplication) to contextually map features into exceedingly high-dimensional and non-linear feature spaces, which greatly enhances representation learning. To further boost the extraction of contextual information, as for the second issue, we propose a large dynamic integration module (LDIM) which possesses an extremely large receptive field. Thus, LDIM can dynamically and efficiently integrate more contextual information that helps to further significantly improve the reconstruction performance. Integrating ERSM and LDIM into an U-shaped backbone, we propose a context-aware convolutional network (CCNet) with powerful learning ability for contextual high-dimensional mapping and abundant contextual information. Extensive experiments show that our CCNet with low model complexity achieves superior performance compared to other state-of-the-art IR methods on several IR tasks, including image dehazing, image motion deblurring, and image desnowing.