 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg-Agent: Test-Time Multimodal Reasoning for Training-Free Language-Guided Segmentation
May 13, 2026Language-guided segmentation transcends the scope limitations of traditional semantic segmentation, enabling models to segment arbitrary target regions based on natural language instructions. Existing approaches typically adopt a two-stage framework: employing Multimodal Large Language Models (MLLMs) to interpret instructions and generate visual prompts, followed by foundational segmentation models (e.g., SAM) to produce masks. However, due to the limited spatial grounding capabilities of off-the-shelf MLLMs, these methods often rely on extensive training on large-scale datasets to achieve satisfactory accuracy. While recent advances have introduced reasoning mechanisms to improve performance, they predominantly operate within the textual domain, performing chain-of-thought reasoning solely based on abstract text representations without direct visual feedback. In this paper, we propose Seg-Agent, a completely training-free framework that pioneers Explicit Multimodal Chain-of-Reasoning. Unlike prior text-only reasoning, our approach constructs an interactive visual reasoning loop comprising three stages: generation, selection, and refinement. Specifically, we leverage Set-of-Mark (SoM) visual prompting to render candidate regions directly onto the image, allowing the MLLM to ``see'' and iteratively reason about spatial relationships in the visual domain rather than just the textual one. This explicit multimodal interaction enables Seg-Agent to achieve performance comparable to state-of-the-art training-based methods without any parameter updates. Furthermore, to comprehensively evaluate generalization across diverse scenarios, we introduce Various-LangSeg, a novel benchmark covering explicit semantic, generic object, and reasoning-guided segmentation tasks. Extensive experiments demonstrate the effectiveness and robustness of our method.
Efficient Star Distillation Attention Network for Lightweight Image Super-Resolution
Jun 14, 2025In recent years, the performance of lightweight Single-Image Super-Resolution (SISR) has been improved significantly with the application of Convolutional Neural Networks (CNNs) and Large Kernel Attention (LKA). However, existing information distillation modules for lightweight SISR struggle to map inputs into High-Dimensional Non-Linear (HDNL) feature spaces, limiting their representation learning. And their LKA modules possess restricted ability to capture the multi-shape multi-scale information for long-range dependencies while encountering a quadratic increase in the computational burden with increasing convolutional kernel size of its depth-wise convolutional layer. To address these issues, we firstly propose a Star Distillation Module (SDM) to enhance the discriminative representation learning via information distillation in the HDNL feature spaces. Besides, we present a Multi-shape Multi-scale Large Kernel Attention (MM-LKA) module to learn representative long-range dependencies while incurring low computational and memory footprints, leading to improving the performance of CNN-based self-attention significantly. Integrating SDM and MM-LKA, we develop a Residual Star Distillation Attention Module (RSDAM) and take it as the building block of the proposed efficient Star Distillation Attention Network (SDAN) which possesses high reconstruction efficiency to recover a higher-quality image from the corresponding low-resolution (LR) counterpart. When compared with other lightweight state-of-the-art SISR methods, extensive experiments show that our SDAN with low model complexity yields superior performance quantitatively and visually.
Towards Context-aware Convolutional Network for Image Restoration
Dec 15, 2024
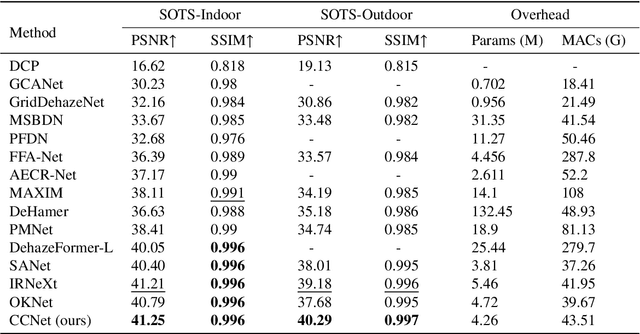


Image restoration (IR) is a long-standing task to recover a high-quality image from its corrupted observation. Recently, transformer-based algorithms and some attention-based convolutional neural networks (CNNs) have presented promising results on several IR tasks. However, existing convolutional residual building modules for IR encounter limited ability to map inputs into high-dimensional and non-linear feature spaces, and their local receptive fields have difficulty in capturing long-range context information like Transformer. Besides, CNN-based attention modules for IR either face static abundant parameters or have limited receptive fields. To address the first issue, we propose an efficient residual star module (ERSM) that includes context-aware "star operation" (element-wise multiplication) to contextually map features into exceedingly high-dimensional and non-linear feature spaces, which greatly enhances representation learning. To further boost the extraction of contextual information, as for the second issue, we propose a large dynamic integration module (LDIM) which possesses an extremely large receptive field. Thus, LDIM can dynamically and efficiently integrate more contextual information that helps to further significantly improve the reconstruction performance. Integrating ERSM and LDIM into an U-shaped backbone, we propose a context-aware convolutional network (CCNet) with powerful learning ability for contextual high-dimensional mapping and abundant contextual information. Extensive experiments show that our CCNet with low model complexity achieves superior performance compared to other state-of-the-art IR methods on several IR tasks, including image dehazing, image motion deblurring, and image desnowing.
Dilated Strip Attention Network for Image Restoration
Jul 26, 2024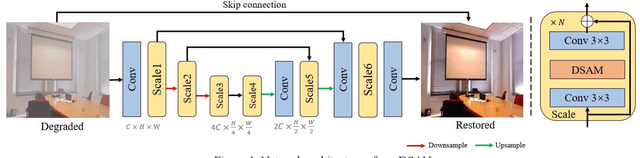
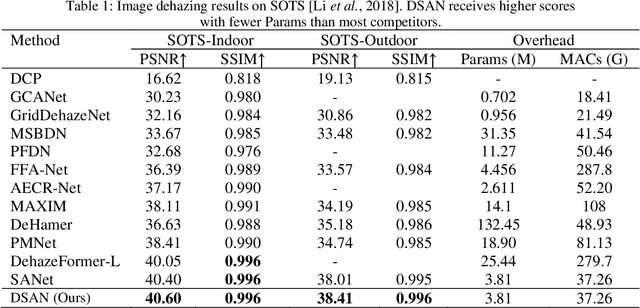
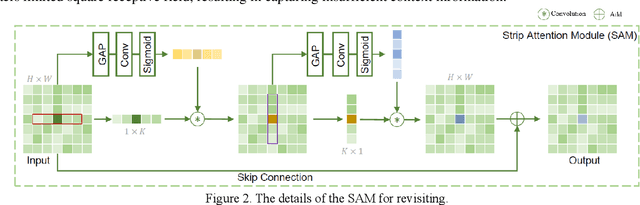
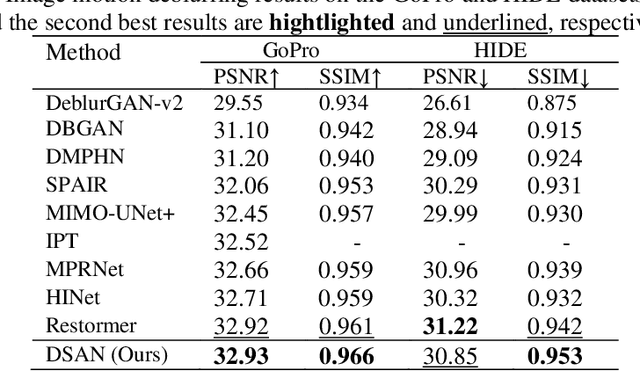
Image restoration is a long-standing task that seeks to recover the latent sharp image from its deteriorated counterpart. Due to the robust capacity of self-attention to capture long-range dependencies, transformer-based methods or some attention-based convolutional neural networks have demonstrated promising results on many image restoration tasks in recent years. However, existing attention modules encounters limited receptive fields or abundant parameters. In order to integrate contextual information more effectively and efficiently, in this paper, we propose a dilated strip attention network (DSAN) for image restoration. Specifically, to gather more contextual information for each pixel from its neighboring pixels in the same row or column, a dilated strip attention (DSA) mechanism is elaborately proposed. By employing the DSA operation horizontally and vertically, each location can harvest the contextual information from a much wider region. In addition, we utilize multi-scale receptive fields across different feature groups in DSA to improve representation learning. Extensive experiments show that our DSAN outperforms state-of-the-art algorithms on several image restoration tasks.
Large coordinate kernel attention network for lightweight image super-resolution
May 15, 2024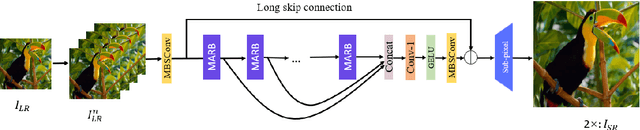

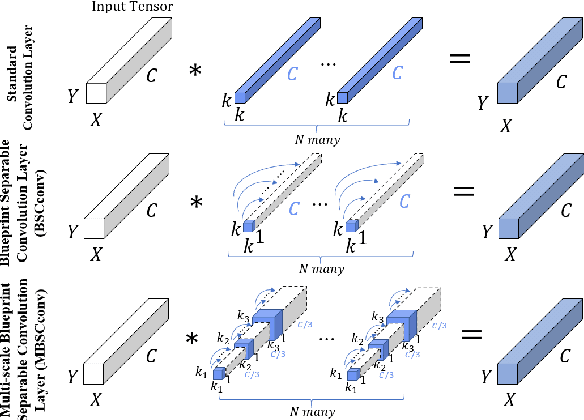
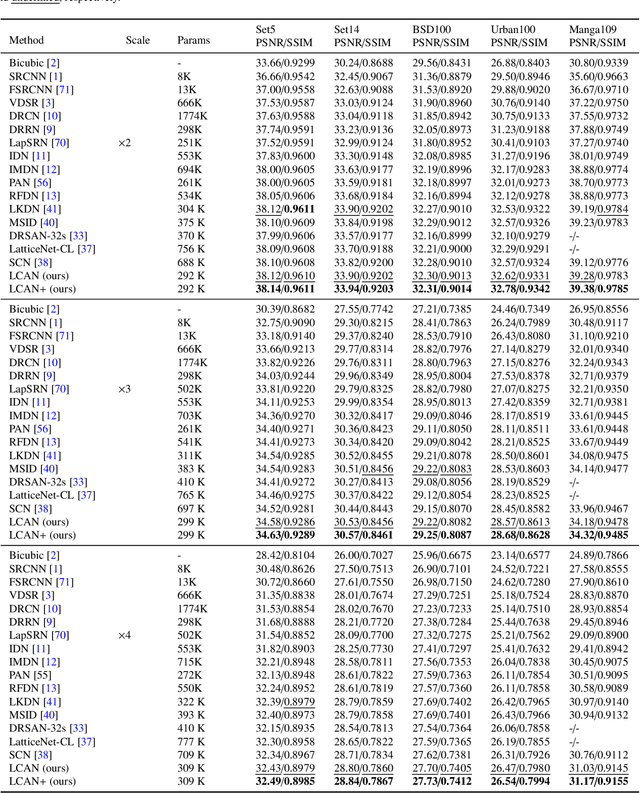
The multi-scale receptive field and large kernel attention (LKA) module have been shown to significantly improve performance in the lightweight image super-resolution task. However, existing lightweight super-resolution (SR) methods seldom pay attention to designing efficient building block with multi-scale receptive field for local modeling, and their LKA modules face a quadratic increase in computational and memory footprints as the convolutional kernel size increases. To address the first issue, we propose the multi-scale blueprint separable convolutions (MBSConv) as highly efficient building block with multi-scale receptive field, it can focus on the learning for the multi-scale information which is a vital component of discriminative representation. As for the second issue, we revisit the key properties of LKA in which we find that the adjacent direct interaction of local information and long-distance dependencies is crucial to provide remarkable performance. Thus, taking this into account and in order to mitigate the complexity of LKA, we propose a large coordinate kernel attention (LCKA) module which decomposes the 2D convolutional kernels of the depth-wise convolutional layers in LKA into horizontal and vertical 1-D kernels. LCKA enables the adjacent direct interaction of local information and long-distance dependencies not only in the horizontal direction but also in the vertical. Besides, LCKA allows for the direct use of extremely large kernels in the depth-wise convolutional layers to capture more contextual information, which helps to significantly improve the reconstruction performance, and it incurs lower computational complexity and memory footprints. Integrating MBSConv and LCKA, we propose a large coordinate kernel attention network (LCAN).