 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge coordinate kernel attention network for lightweight image super-resolution
Paper and Code
May 15, 2024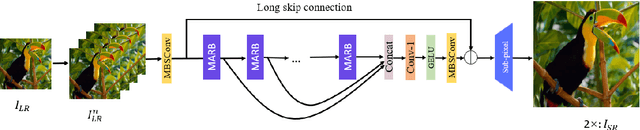

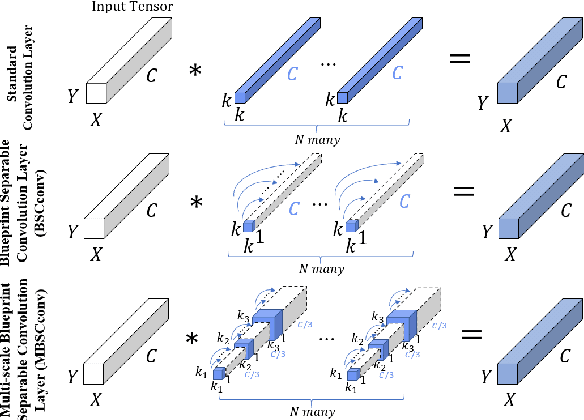
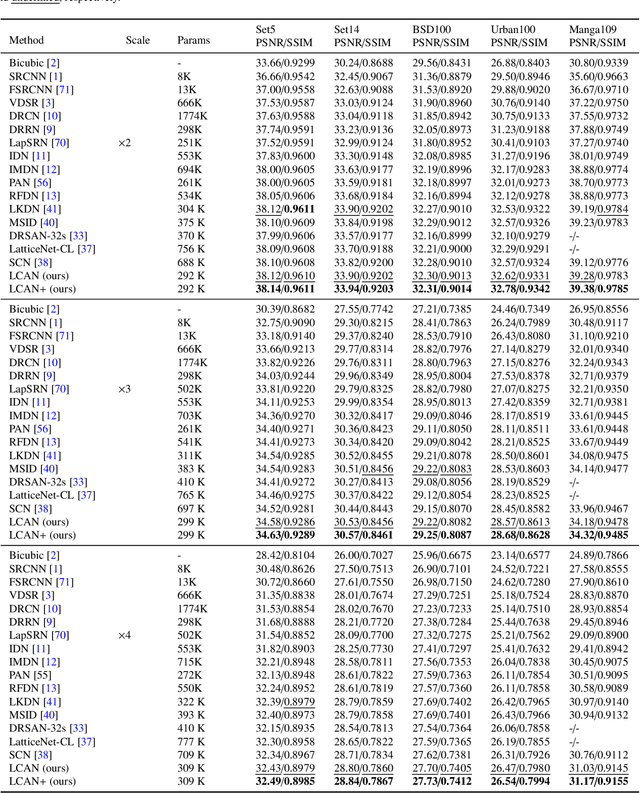
The multi-scale receptive field and large kernel attention (LKA) module have been shown to significantly improve performance in the lightweight image super-resolution task. However, existing lightweight super-resolution (SR) methods seldom pay attention to designing efficient building block with multi-scale receptive field for local modeling, and their LKA modules face a quadratic increase in computational and memory footprints as the convolutional kernel size increases. To address the first issue, we propose the multi-scale blueprint separable convolutions (MBSConv) as highly efficient building block with multi-scale receptive field, it can focus on the learning for the multi-scale information which is a vital component of discriminative representation. As for the second issue, we revisit the key properties of LKA in which we find that the adjacent direct interaction of local information and long-distance dependencies is crucial to provide remarkable performance. Thus, taking this into account and in order to mitigate the complexity of LKA, we propose a large coordinate kernel attention (LCKA) module which decomposes the 2D convolutional kernels of the depth-wise convolutional layers in LKA into horizontal and vertical 1-D kernels. LCKA enables the adjacent direct interaction of local information and long-distance dependencies not only in the horizontal direction but also in the vertical. Besides, LCKA allows for the direct use of extremely large kernels in the depth-wise convolutional layers to capture more contextual information, which helps to significantly improve the reconstruction performance, and it incurs lower computational complexity and memory footprints. Integrating MBSConv and LCKA, we propose a large coordinate kernel attention network (LCAN).