 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking AI Explainability and Plausibility
Mar 30, 2023Setting proper evaluation objectives for explainable artificial intelligence (XAI) is vital for making XAI algorithms follow human communication norms, support human reasoning processes, and fulfill human needs for AI explanations. In this article, we examine explanation plausibility, which is the most pervasive human-grounded concept in XAI evaluation. Plausibility measures how reasonable the machine explanation is compared to the human explanation. Plausibility has been conventionally formulated as an important evaluation objective for AI explainability tasks. We argue against this idea, and show how optimizing and evaluating XAI for plausibility is sometimes harmful, and always ineffective to achieve model understandability, transparency, and trustworthiness. Specifically, evaluating XAI algorithms for plausibility regularizes the machine explanation to express exactly the same content as human explanation, which deviates from the fundamental motivation for humans to explain: expressing similar or alternative reasoning trajectories while conforming to understandable forms or language. Optimizing XAI for plausibility regardless of the model decision correctness also jeopardizes model trustworthiness, as doing so breaks an important assumption in human-human explanation namely that plausible explanations typically imply correct decisions, and violating this assumption eventually leads to either undertrust or overtrust of AI models. Instead of being the end goal in XAI evaluation, plausibility can serve as an intermediate computational proxy for the human process of interpreting explanations to optimize the utility of XAI. We further highlight the importance of explainability-specific evaluation objectives by differentiating the AI explanation task from the object localization task.
Invisible Users: Uncovering End-Users' Requirements for Explainable AI via Explanation Forms and Goals
Feb 15, 2023Non-technical end-users are silent and invisible users of the state-of-the-art explainable artificial intelligence (XAI) technologies. Their demands and requirements for AI explainability are not incorporated into the design and evaluation of XAI techniques, which are developed to explain the rationales of AI decisions to end-users and assist their critical decisions. This makes XAI techniques ineffective or even harmful in high-stakes applications, such as healthcare, criminal justice, finance, and autonomous driving systems. To systematically understand end-users' requirements to support the technical development of XAI, we conducted the EUCA user study with 32 layperson participants in four AI-assisted critical tasks. The study identified comprehensive user requirements for feature-, example-, and rule-based XAI techniques (manifested by the end-user-friendly explanation forms) and XAI evaluation objectives (manifested by the explanation goals), which were shown to be helpful to directly inspire the proposal of new XAI algorithms and evaluation metrics. The EUCA study findings, the identified explanation forms and goals for technical specification, and the EUCA study dataset support the design and evaluation of end-user-centered XAI techniques for accessible, safe, and accountable AI.
Transcending XAI Algorithm Boundaries through End-User-Inspired Design
Aug 18, 2022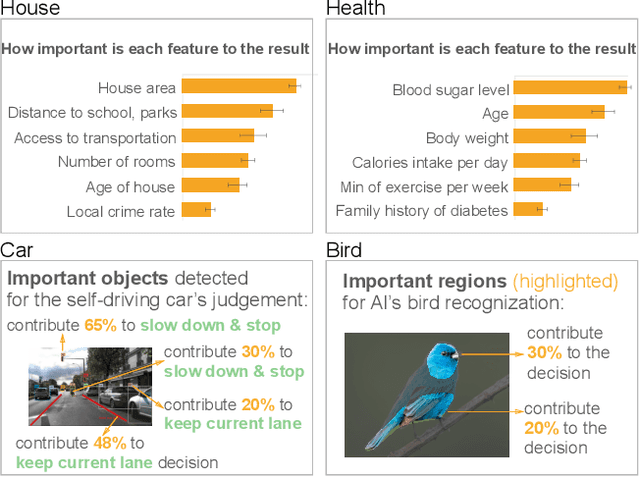
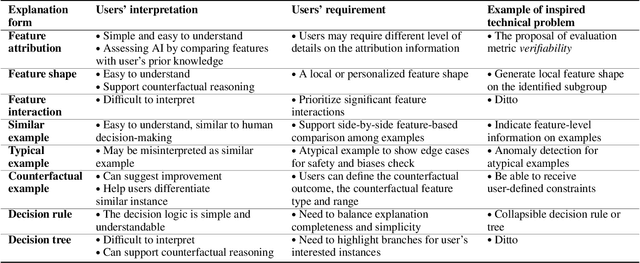
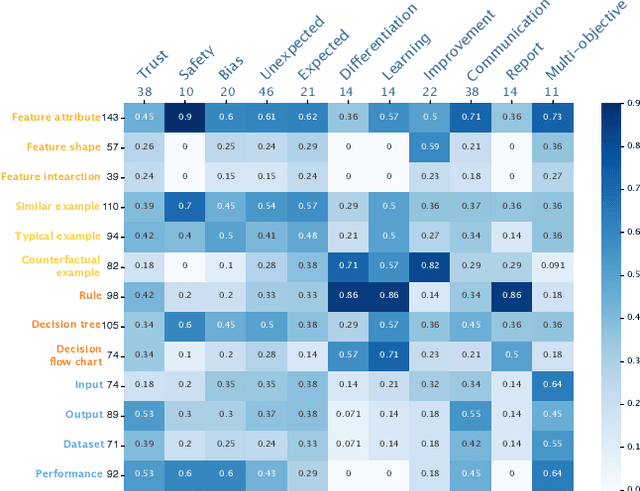
The boundaries of existing explainable artificial intelligence (XAI) algorithms are confined to problems grounded in technical users' demand for explainability. This research paradigm disproportionately ignores the larger group of non-technical end users of XAI, who do not have technical knowledge but need explanations in their AI-assisted critical decisions. Lacking explainability-focused functional support for end users may hinder the safe and responsible use of AI in high-stakes domains, such as healthcare, criminal justice, finance, and autonomous driving systems. In this work, we explore how designing XAI tailored to end users' critical tasks inspires the framing of new technical problems. To elicit users' interpretations and requirements for XAI algorithms, we first identify eight explanation forms as the communication tool between AI researchers and end users, such as explaining using features, examples, or rules. Using the explanation forms, we then conduct a user study with 32 layperson participants in the context of achieving different explanation goals (such as verifying AI decisions, and improving user's predicted outcomes) in four critical tasks. Based on the user study findings, we identify and formulate novel XAI technical problems, and propose an evaluation metric verifiability based on users' explanation goal of verifying AI decisions. Our work shows that grounding the technical problem in end users' use of XAI can inspire new research questions. Such end-user-inspired research questions have the potential to promote social good by democratizing AI and ensuring the responsible use of AI in critical domains.
Evaluating Explainable AI on a Multi-Modal Medical Imaging Task: Can Existing Algorithms Fulfill Clinical Requirements?
Mar 12, 2022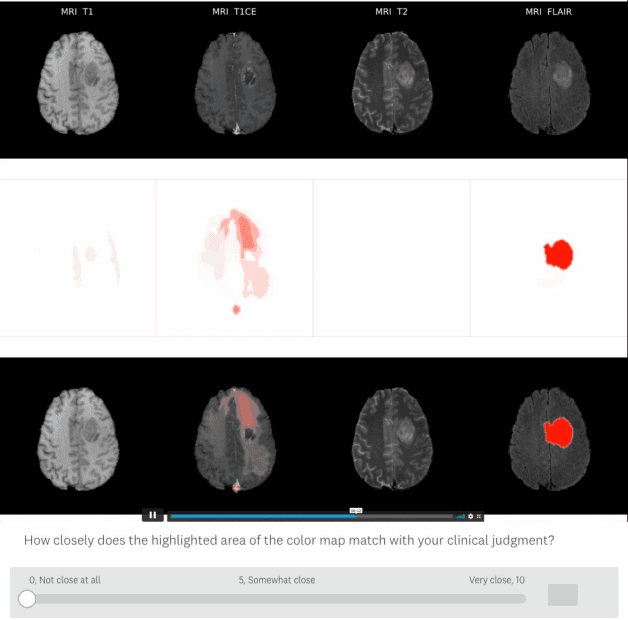
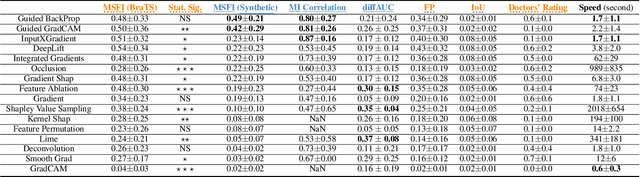
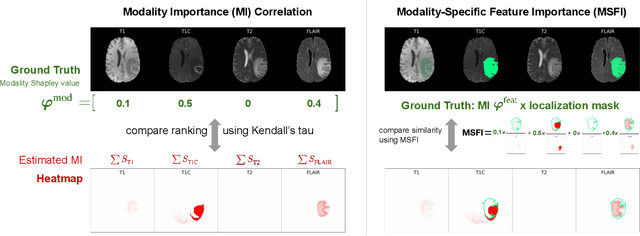

Being able to explain the prediction to clinical end-users is a necessity to leverage the power of artificial intelligence (AI) models for clinical decision support. For medical images, a feature attribution map, or heatmap, is the most common form of explanation that highlights important features for AI models' prediction. However, it is unknown how well heatmaps perform on explaining decisions on multi-modal medical images, where each image modality or channel visualizes distinct clinical information of the same underlying biomedical phenomenon. Understanding such modality-dependent features is essential for clinical users' interpretation of AI decisions. To tackle this clinically important but technically ignored problem, we propose the modality-specific feature importance (MSFI) metric. It encodes clinical image and explanation interpretation patterns of modality prioritization and modality-specific feature localization. We conduct a clinical requirement-grounded, systematic evaluation using computational methods and a clinician user study. Results show that the examined 16 heatmap algorithms failed to fulfill clinical requirements to correctly indicate AI model decision process or decision quality. The evaluation and MSFI metric can guide the design and selection of XAI algorithms to meet clinical requirements on multi-modal explanation.
Guidelines and evaluation for clinical explainable AI on medical image analysis
Feb 16, 2022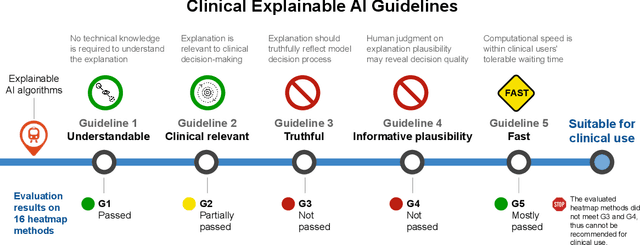
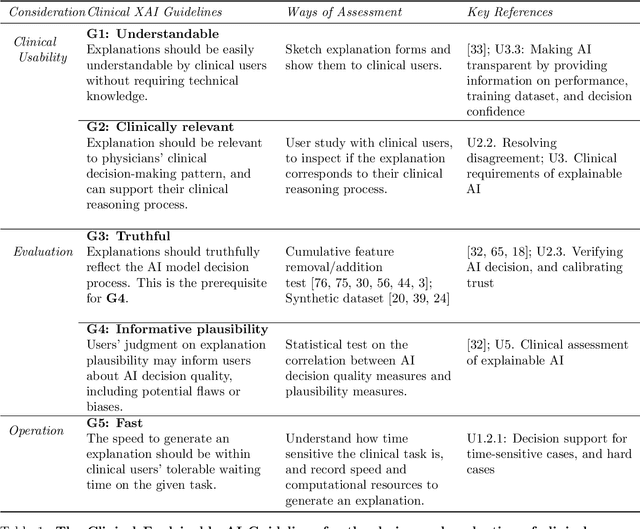
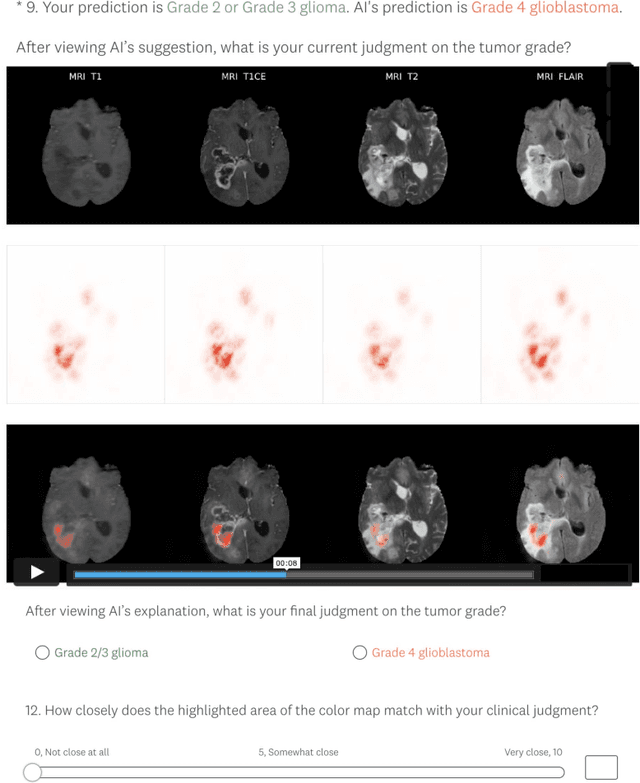
Explainable artificial intelligence (XAI) is essential for enabling clinical users to get informed decision support from AI and comply with evidence-based medical practice. Applying XAI in clinical settings requires proper evaluation criteria to ensure the explanation technique is both technically sound and clinically useful, but specific support is lacking to achieve this goal. To bridge the research gap, we propose the Clinical XAI Guidelines that consist of five criteria a clinical XAI needs to be optimized for. The guidelines recommend choosing an explanation form based on Guideline 1 (G1) Understandability and G2 Clinical relevance. For the chosen explanation form, its specific XAI technique should be optimized for G3 Truthfulness, G4 Informative plausibility, and G5 Computational efficiency. Following the guidelines, we conducted a systematic evaluation on a novel problem of multi-modal medical image explanation with two clinical tasks, and proposed new evaluation metrics accordingly. The evaluated 16 commonly-used heatmap XAI techniques were not suitable for clinical use due to their failure in \textbf{G3} and \textbf{G4}. Our evaluation demonstrated the use of Clinical XAI Guidelines to support the design and evaluation for clinically viable XAI.
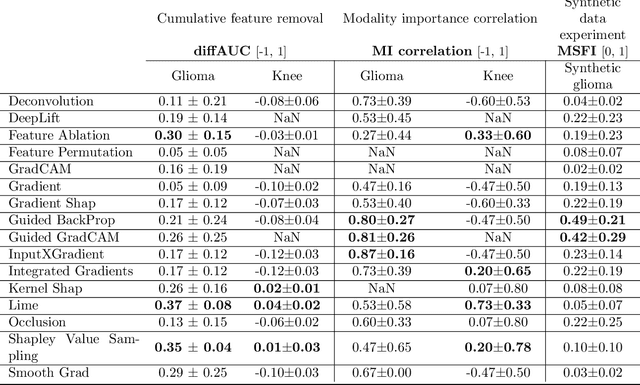
One Map Does Not Fit All: Evaluating Saliency Map Explanation on Multi-Modal Medical Images
Jul 11, 2021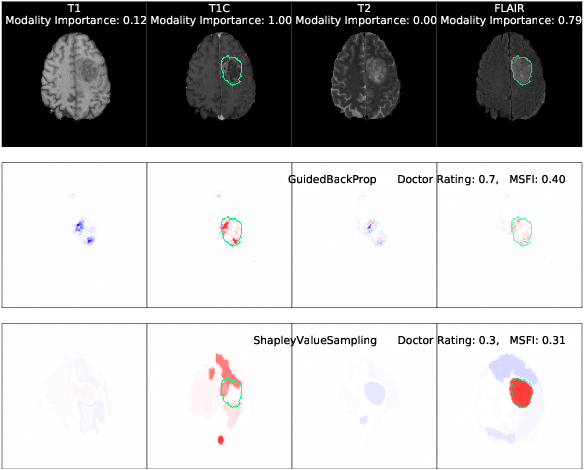

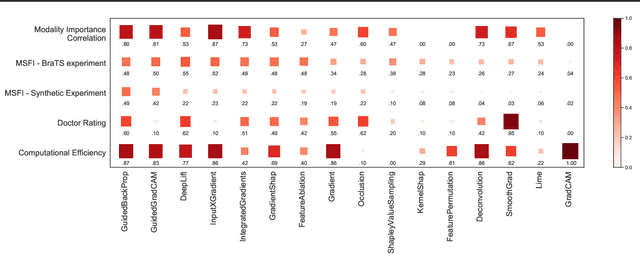
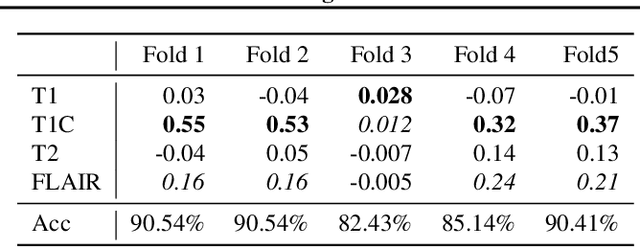
Being able to explain the prediction to clinical end-users is a necessity to leverage the power of AI models for clinical decision support. For medical images, saliency maps are the most common form of explanation. The maps highlight important features for AI model's prediction. Although many saliency map methods have been proposed, it is unknown how well they perform on explaining decisions on multi-modal medical images, where each modality/channel carries distinct clinical meanings of the same underlying biomedical phenomenon. Understanding such modality-dependent features is essential for clinical users' interpretation of AI decisions. To tackle this clinically important but technically ignored problem, we propose the MSFI (Modality-Specific Feature Importance) metric to examine whether saliency maps can highlight modality-specific important features. MSFI encodes the clinical requirements on modality prioritization and modality-specific feature localization. Our evaluations on 16 commonly used saliency map methods, including a clinician user study, show that although most saliency map methods captured modality importance information in general, most of them failed to highlight modality-specific important features consistently and precisely. The evaluation results guide the choices of saliency map methods and provide insights to propose new ones targeting clinical applications.
Applying Artificial Intelligence to Glioma Imaging: Advances and Challenges
Nov 28, 2019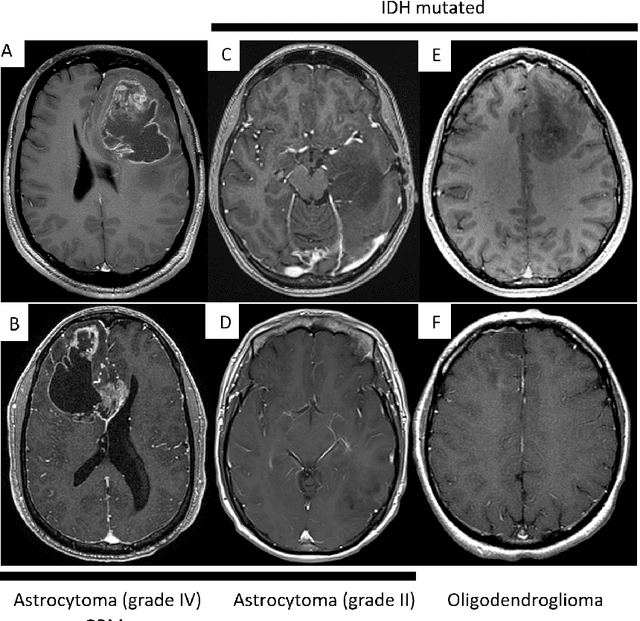
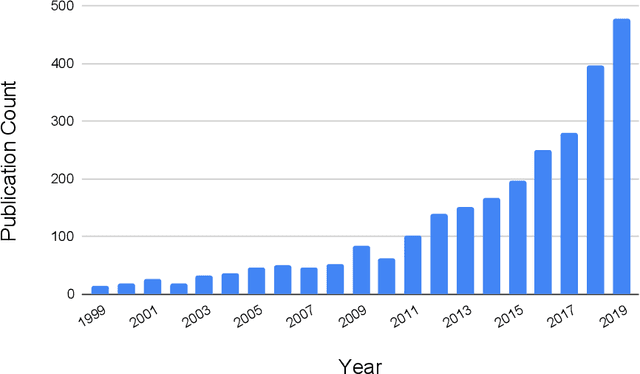
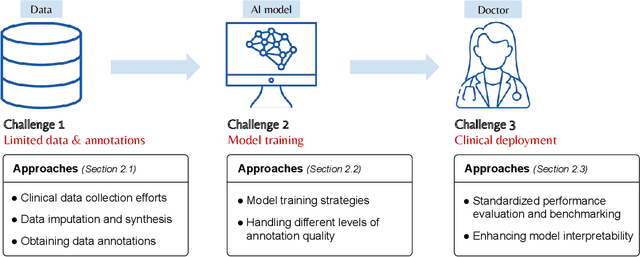
Primary brain tumors including gliomas continue to pose significant management challenges to clinicians. While the presentation, the pathology, and the clinical course of these lesions is variable, the initial investigations are usually similar. Patients who are suspected to have a brain tumor will be assessed with computed tomography (CT) and magnetic resonance imaging (MRI). The imaging findings are used by neurosurgeons to determine the feasibility of surgical resection and plan such an undertaking. Imaging studies are also an indispensable tool in tracking tumor progression or its response to treatment. As these imaging studies are non-invasive, relatively cheap and accessible to patients, there have been many efforts over the past two decades to increase the amount of clinically-relevant information that can be extracted from brain imaging. Most recently, artificial intelligence (AI) techniques have been employed to segment and characterize brain tumors, as well as to detect progression or treatment-response. However, the clinical utility of such endeavours remains limited due to challenges in data collection and annotation, model training, and in the reliability of AI-generated information. We provide a review of recent advances in addressing the above challenges. First, to overcome the challenge of data paucity, different image imputation and synthesis techniques along with annotation collection efforts are summarized. Next, various training strategies are presented to meet multiple desiderata, such as model performance, generalization ability, data privacy protection, and learning with sparse annotations. Finally, standardized performance evaluation and model interpretability methods have been reviewed. We believe that these technical approaches will facilitate the development of a fully-functional AI tool in the clinical care of patients with gliomas.