 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Evidence into the Design of XAI and AI-based Decision Support Systems: A Means-End Framework for End-users in Construction
Dec 17, 2024A narrative review is used to develop a theoretical evidence-based means-end framework to build an epistemic foundation to uphold explainable artificial intelligence instruments so that the reliability of outcomes generated from decision support systems can be assured and better explained to end-users. The implications of adopting an evidence-based approach to designing decision support systems in construction are discussed with emphasis placed on evaluating the strength, value, and utility of evidence needed to develop meaningful human explanations for end-users. While the developed means-end framework is focused on end-users, stakeholders can also utilize it to create meaningful human explanations. However, they will vary due to their different epistemic goals. Including evidence in the design and development of explainable artificial intelligence and decision support systems will improve decision-making effectiveness, enabling end-users' epistemic goals to be achieved. The proposed means-end framework is developed from a broad spectrum of literature. Thus, it is suggested that it can be used in construction and other engineering domains where there is a need to integrate evidence into the design of explainable artificial intelligence and decision support systems.
Explainable Artificial Intelligence in Construction: The Content, Context, Process, Outcome Evaluation Framework
Nov 12, 2022Explainable artificial intelligence is an emerging and evolving concept. Its impact on construction, though yet to be realised, will be profound in the foreseeable future. Still, XAI has received limited attention in construction. As a result, no evaluation frameworks have been propagated to enable construction organisations to understand the what, why, how, and when of XAI. Our paper aims to fill this void by developing a content, context, process, and outcome evaluation framework that can be used to justify the adoption and effective management of XAI. After introducing and describing this novel framework, we discuss its implications for future research. While our novel framework is conceptual, it provides a frame of reference for construction organisations to make headway toward realising XAI business value and benefits.
Explainable Artificial Intelligence: Precepts, Methods, and Opportunities for Research in Construction
Nov 12, 2022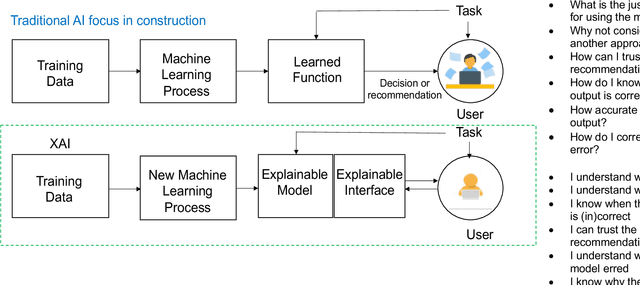
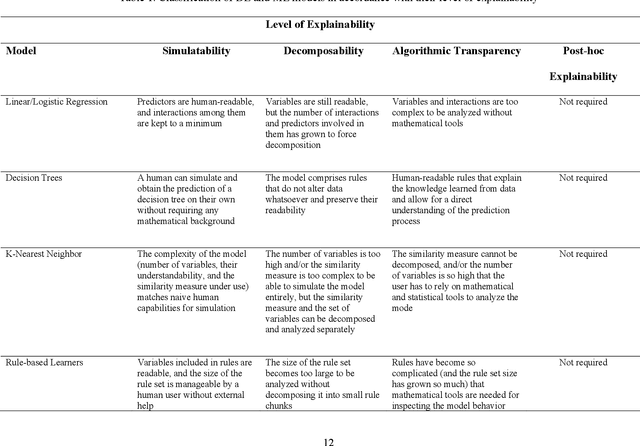
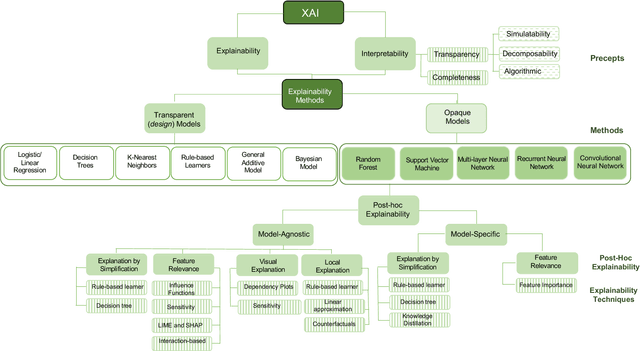

Explainable artificial intelligence has received limited attention in construction despite its growing importance in various other industrial sectors. In this paper, we provide a narrative review of XAI to raise awareness about its potential in construction. Our review develops a taxonomy of the XAI literature comprising its precepts and approaches. Opportunities for future XAI research focusing on stakeholder desiderata and data and information fusion are identified and discussed. We hope the opportunities we suggest stimulate new lines of inquiry to help alleviate the scepticism and hesitancy toward AI adoption and integration in construction.
Adversarial Attacks and Defenses in Physiological Computing: A Systematic Review
Feb 11, 2021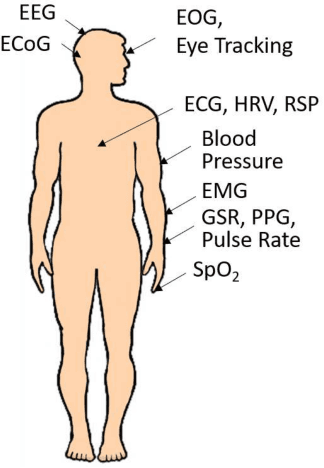
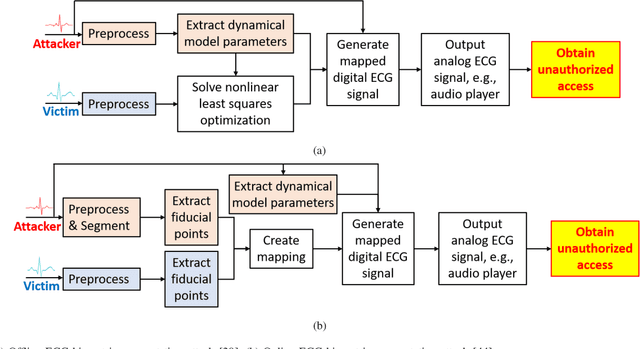
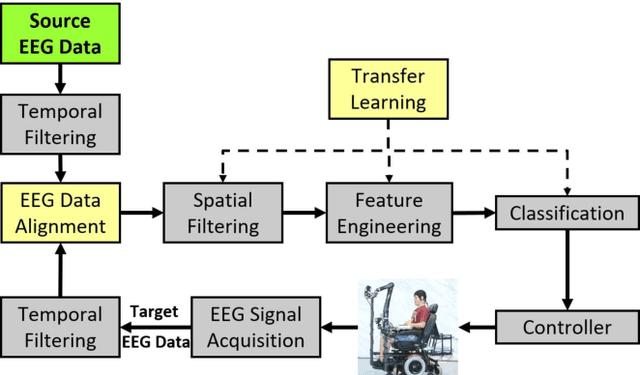
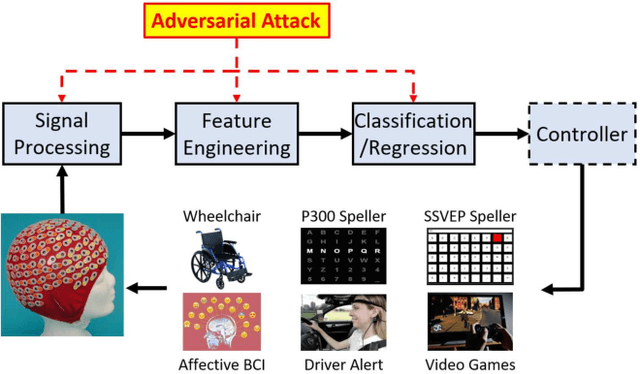
Physiological computing uses human physiological data as system inputs in real time. It includes, or significantly overlaps with, brain-computer interfaces, affective computing, adaptive automation, health informatics, and physiological signal based biometrics. Physiological computing increases the communication bandwidth from the user to the computer, but is also subject to various types of adversarial attacks, in which the attacker deliberately manipulates the training and/or test examples to hijack the machine learning algorithm output, leading to possibly user confusion, frustration, injury, or even death. However, the vulnerability of physiological computing systems has not been paid enough attention to, and there does not exist a comprehensive review on adversarial attacks to it. This paper fills this gap, by providing a systematic review on the main research areas of physiological computing, different types of adversarial attacks and their applications to physiological computing, and the corresponding defense strategies. We hope this review will attract more research interests on the vulnerability of physiological computing systems, and more importantly, defense strategies to make them more secure.
Pool-Based Unsupervised Active Learning for Regression Using Iterative Representativeness-Diversity Maximization (iRDM)
Mar 31, 2020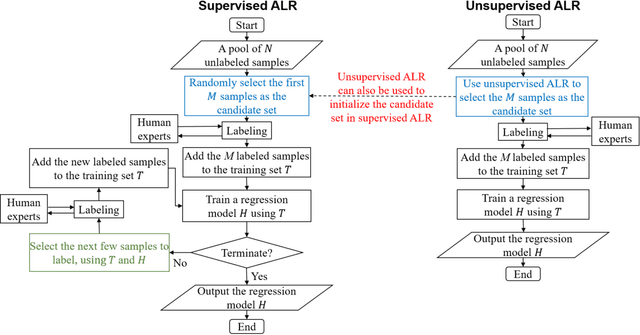
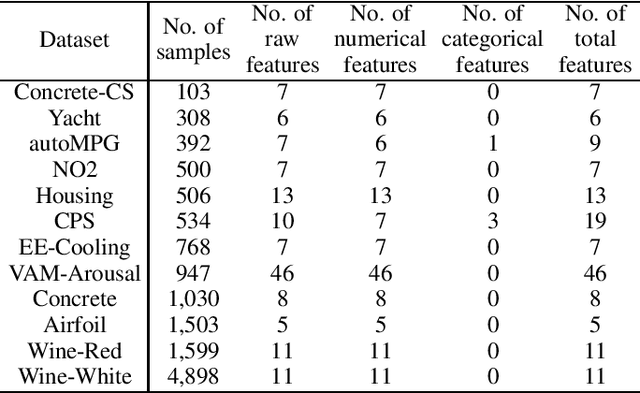
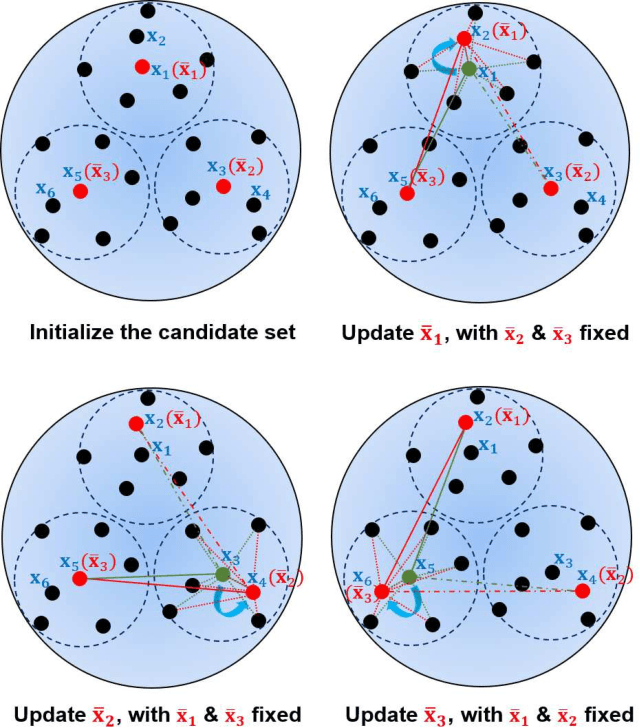
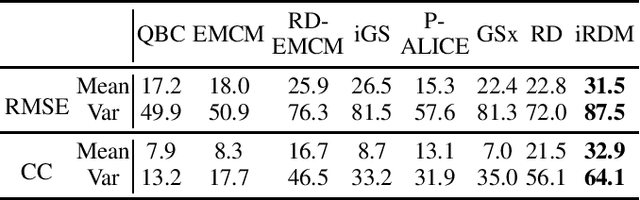
Active learning (AL) selects the most beneficial unlabeled samples to label, and hence a better machine learning model can be trained from the same number of labeled samples. Most existing active learning for regression (ALR) approaches are supervised, which means the sampling process must use some label information, or an existing regression model. This paper considers completely unsupervised ALR, i.e., how to select the samples to label without knowing any true label information. We propose a novel unsupervised ALR approach, iterative representativeness-diversity maximization (iRDM), to optimally balance the representativeness and the diversity of the selected samples. Experiments on 12 datasets from various domains demonstrated its effectiveness. Our iRDM can be applied to both linear regression and kernel regression, and it even significantly outperforms supervised ALR when the number of labeled samples is small.