 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSplatter: Enabling Cross-Device Efficient Gaussian Splatting in Web Browsers via WebGPU
Feb 03, 2026We present WebSplatter, an end-to-end GPU rendering pipeline for the heterogeneous web ecosystem. Unlike naive ports, WebSplatter introduces a wait-free hierarchical radix sort that circumvents the lack of global atomics in WebGPU, ensuring deterministic execution across diverse hardware. Furthermore, we propose an opacity-aware geometry culling stage that dynamically prunes splats before rasterization, significantly reducing overdraw and peak memory footprint. Evaluation demonstrates that WebSplatter consistently achieves 1.2$\times$ to 4.5$\times$ speedups over state-of-the-art web viewers.
PixelWeb: The First Web GUI Dataset with Pixel-Wise Labels
Apr 23, 2025Graphical User Interface (GUI) datasets are crucial for various downstream tasks. However, GUI datasets often generate annotation information through automatic labeling, which commonly results in inaccurate GUI element BBox annotations, including missing, duplicate, or meaningless BBoxes. These issues can degrade the performance of models trained on these datasets, limiting their effectiveness in real-world applications. Additionally, existing GUI datasets only provide BBox annotations visually, which restricts the development of visually related GUI downstream tasks. To address these issues, we introduce PixelWeb, a large-scale GUI dataset containing over 100,000 annotated web pages. PixelWeb is constructed using a novel automatic annotation approach that integrates visual feature extraction and Document Object Model (DOM) structure analysis through two core modules: channel derivation and layer analysis. Channel derivation ensures accurate localization of GUI elements in cases of occlusion and overlapping elements by extracting BGRA four-channel bitmap annotations. Layer analysis uses the DOM to determine the visibility and stacking order of elements, providing precise BBox annotations. Additionally, PixelWeb includes comprehensive metadata such as element images, contours, and mask annotations. Manual verification by three independent annotators confirms the high quality and accuracy of PixelWeb annotations. Experimental results on GUI element detection tasks show that PixelWeb achieves performance on the mAP95 metric that is 3-7 times better than existing datasets. We believe that PixelWeb has great potential for performance improvement in downstream tasks such as GUI generation and automated user interaction.
S2DNAS:Transforming Static CNN Model for Dynamic Inference via Neural Architecture Search
Dec 17, 2019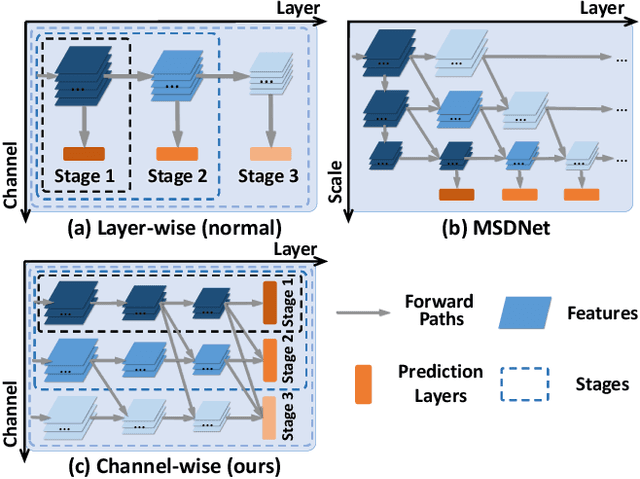



Recently, dynamic inference has emerged as a promising way to reduce the computational cost of deep convolutional neural network (CNN). In contrast to static methods (e.g. weight pruning), dynamic inference adaptively adjusts the inference process according to each input sample, which can considerably reduce the computational cost on "easy" samples while maintaining the overall model performance. In this paper, we introduce a general framework, S2DNAS, which can transform various static CNN models to support dynamic inference via neural architecture search. To this end, based on a given CNN model, we first generate a CNN architecture space in which each architecture is a multi-stage CNN generated from the given model using some predefined transformations. Then, we propose a reinforcement learning based approach to automatically search for the optimal CNN architecture in the generated space. At last, with the searched multi-stage network, we can perform dynamic inference by adaptively choosing a stage to evaluate for each sample. Unlike previous works that introduce irregular computations or complex controllers in the inference or re-design a CNN model from scratch, our method can generalize to most of the popular CNN architectures and the searched dynamic network can be directly deployed using existing deep learning frameworks in various hardware devices.