 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-training Improves Pre-training for Few-shot Learning in Task-oriented Dialog Systems
Aug 28, 2021
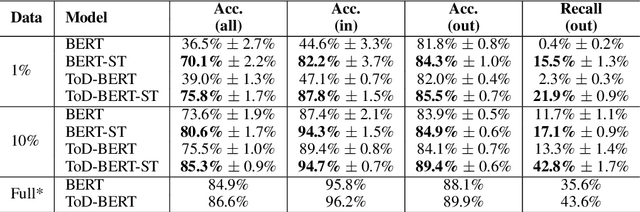


As the labeling cost for different modules in task-oriented dialog (ToD) systems is expensive, a major challenge is to train different modules with the least amount of labeled data. Recently, large-scale pre-trained language models, have shown promising results for few-shot learning in ToD. In this paper, we devise a self-training approach to utilize the abundant unlabeled dialog data to further improve state-of-the-art pre-trained models in few-shot learning scenarios for ToD systems. Specifically, we propose a self-training approach that iteratively labels the most confident unlabeled data to train a stronger Student model. Moreover, a new text augmentation technique (GradAug) is proposed to better train the Student by replacing non-crucial tokens using a masked language model. We conduct extensive experiments and present analyses on four downstream tasks in ToD, including intent classification, dialog state tracking, dialog act prediction, and response selection. Empirical results demonstrate that the proposed self-training approach consistently improves state-of-the-art pre-trained models (BERT, ToD-BERT) when only a small number of labeled data are available.
SLIM: Explicit Slot-Intent Mapping with BERT for Joint Multi-Intent Detection and Slot Filling
Aug 26, 2021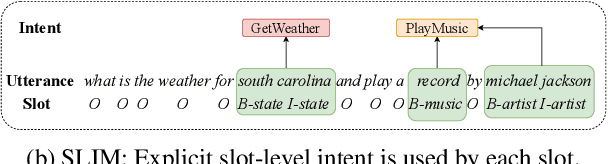


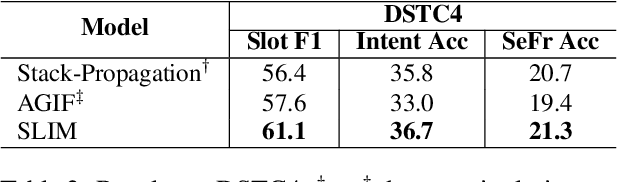
Utterance-level intent detection and token-level slot filling are two key tasks for natural language understanding (NLU) in task-oriented systems. Most existing approaches assume that only a single intent exists in an utterance. However, there are often multiple intents within an utterance in real-life scenarios. In this paper, we propose a multi-intent NLU framework, called SLIM, to jointly learn multi-intent detection and slot filling based on BERT. To fully exploit the existing annotation data and capture the interactions between slots and intents, SLIM introduces an explicit slot-intent classifier to learn the many-to-one mapping between slots and intents. Empirical results on three public multi-intent datasets demonstrate (1) the superior performance of SLIM compared to the current state-of-the-art for NLU with multiple intents and (2) the benefits obtained from the slot-intent classifier.
Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning
Aug 21, 2018

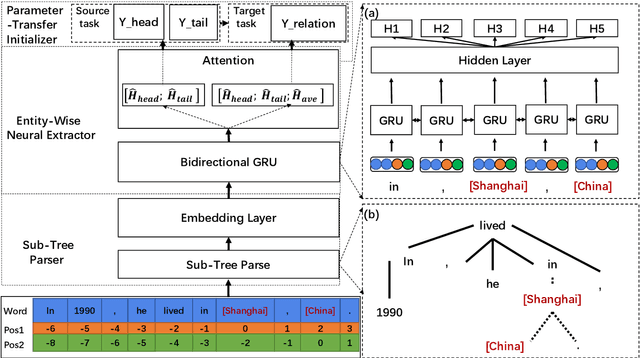

Extracting relations is critical for knowledge base completion and construction in which distant supervised methods are widely used to extract relational facts automatically with the existing knowledge bases. However, the automatically constructed datasets comprise amounts of low-quality sentences containing noisy words, which is neglected by current distant supervised methods resulting in unacceptable precisions. To mitigate this problem, we propose a novel word-level distant supervised approach for relation extraction. We first build Sub-Tree Parse(STP) to remove noisy words that are irrelevant to relations. Then we construct a neural network inputting the sub-tree while applying the entity-wise attention to identify the important semantic features of relational words in each instance. To make our model more robust against noisy words, we initialize our network with a priori knowledge learned from the relevant task of entity classification by transfer learning. We conduct extensive experiments using the corpora of New York Times(NYT) and Freebase. Experiments show that our approach is effective and improves the area of Precision/Recall(PR) from 0.35 to 0.39 over the state-of-the-art work.